第一节 性能优化
本章先结合Google官方的优化教程以及笔者自己的经验,来说一下应用开发时常见的性能优化手段,随后则会介绍一些内存优化的技巧。
界面优化
基础知识
刷新率和帧率
- 屏幕刷新率:代表了屏幕一秒内刷新的次数,60Hz就是屏幕一秒内刷新60次。
- 帧率:代表了GPU在一秒内绘制的帧数,例如60fps就是指GPU一秒钟能生成60张画面,即每秒60帧。
绘制原理
- Android系统要求每一帧都要在16ms内绘制完成,即系统每隔16ms发出VSYNC信号,触发对UI进行渲染,以保持流畅的体验。
- 这样一来系统就可以达到约60帧每秒(1秒/0.016帧每秒 = 62.5帧/秒)的平滑帧率来渲染。
- 如果你的应用没有在16ms内完成这一帧的绘制,假设你花了24ms来绘制这一帧,那么就会出现掉帧的情况。
- 即当系统准备将新的一帧绘制到屏幕上时,但是上一帧并没有画完,所以此时就不会有绘制操作,画面也就不会刷新。反馈到用户身上,就是用户盯着同一张图看了32ms而不是16ms,也就是说掉帧发生了。
为什么是60Fps?
- 由于人类眼睛的特殊生理结构,如果所看画面之帧率高于每秒约10-12帧(即10-12fps)的时候,就会认为是连贯的。
- 电影的拍摄及播放帧率均为每秒24帧,对一般人而言已算可接受,因为这个帧率已经足够支撑大部分电影画面所要表达的内容,同时能最大限度地减少费用支出。不过电影界已经有使用48帧拍摄的电影了 —— 《霍比特人》。
- 但对早期的高动态电子游戏,尤其是射击游戏或竞速游戏来说,帧率少于每秒30帧的话,游戏就会显得不连贯,此时就需要用到60Fps来达到想要表达的效果。
- 因此Android这边也采用了60fps的设计,保持60Fps就意味着每一帧你只有16ms(1秒/60帧率)的时间来处理所有的任务。

垂直同步
- 假设帧率是屏幕刷新率的1/2,那么意味着屏幕刷新2次,GPU才能绘制完一幅画面。
- 相反,如果帧率是刷新率的2倍,那么意味着屏幕刷新1次,GPU能绘制完2幅画面。
- 但是,高于刷新率的帧数都是无效帧数,对画面效果没有任何提升,反而可能导致画面异常。所以许多游戏都有垂直同步选项,打开垂直同步就是强制游戏帧数最大不超过刷新率。
在没有垂直同步的情况下,帧数可以无限高,但屏幕刷新率会受到显示器的硬件限制。
- 所以你可以在60赫兹的显示器上看到200多帧的画面,但是这是200帧的画面流畅程度其实和60帧是一样的,其余140帧全是无效帧数,这140帧的显示信号根本没有被显卡输出到显示器。
- 所以屏幕刷新率的高低决定了有效帧数的多少。
UI绘制机制与栅格化
那么Activity的画面是如何绘制到屏幕上的?那些复杂的XML布局文件又是如何能够被识别并绘制出来的?
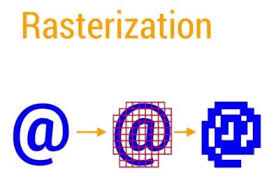
- 绝大多数渲染操作都依赖CPU和GPU两个硬件。
- CPU负责Measure、layout、Record、Execute的计算操作。
- GPU负责栅格化(Rasterization)操作。简单的说,栅格化就是把图像变成像素。
- 比如,将Button、Shape、Path、Bitmap等资源组件拆分到不同的像素上进行显示。这个操作很费时,所以引入了GPU来加快栅格化的操作。
- 显示图片的时候,需要先经过CPU的计算加载到内存中,然后传递给GPU进行渲染。
- 显示文字的时候,需要先经过CPU换算成纹理,然后再交给GPU进行渲染。
- 动画则是一个更加复杂的操作流程,想知道的话,自己查去。
- 因此,非必需的视图组件会带来多余的CPU计算操作,还会占用多余的GPU资源。
主要的原因
通过上面的介绍可以知道,为了能够使得App流畅,我们需要在16ms以内处理完每一帧的CPU与GPU计算,绘制,渲染等操作,否则就会发生掉帧(也就是我们常说的卡顿、不流畅)。
因此所谓的丢帧,本质上就是CPU或GPU饥渴,不论是系统APP还是普通APP,不论是前台App还是后台App,都会共用手机的CPU和GPU资源,而CPU和GPU过于繁忙就会发生App掉帧,如下场景都会导致CPU或GPU饥渴:
- App进程内的主线程繁忙(IO操作、网络操作、SQL操作等都会抢占CPU时间),进而挤压UI绘制时间。
- App进程内的主线程不繁忙,但界面里UI组件太多,导致绘制量大(即16ms内无法绘制完一帧)。
- App进程内的主线程不繁忙,UI组件也不多,但过度绘制严重,也就是说在用户看不到的地方上花费了太多的绘制时间(具体后述)。
- App进程内垃圾回收频繁(GC触发时虚拟机会先暂停所有线程后再执行GC操作,包括主线程),所以当内存泄露、内存抖动等问题发生时,垃圾收集的过程需要花费处理器的时间,(具体后述)。
- 系统资源不足。比如SystemServer进程里的各类服务忙碌的话,还会导致AMS等无法为普通APP服务,进而导致普通APP阻塞、丢帧。
本节参考阅读:
过度绘制
过渡绘制是一个术语,表示某些组件在屏幕上的一个像素点的绘制次数超过1次。
通俗来讲,绘制界面可以类比成一个涂鸦客涂鸦墙壁,涂鸦是一件工作量很大的事情,墙面的每个点在涂鸦过程中可能被涂了各种各样的颜色,但最终呈现的颜色却只可能是1种。
这意味着我们花大力气涂鸦过程中那些非最终呈现的颜色对路人是不可见的,是一种对时间、精力和资源的浪费,存在很大的改善空间。绘制界面同理,花了太多的时间去绘制那些堆叠在下面的、用户看不到的东西,这样是在浪费CPU周期和渲染时间!
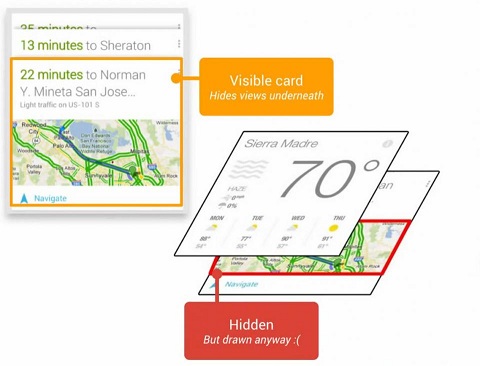
上图中,被用户激活的卡片在最上面,而那些没有激活的卡片在下面,在绘制用户看不到的对象上花费了太多的时间。
追踪过度绘制
通过在手机的开发者选项里打开“调试GPU过度绘制”,来查看应用所有界面及分支界面下的过度绘制情况,方便进行优化。
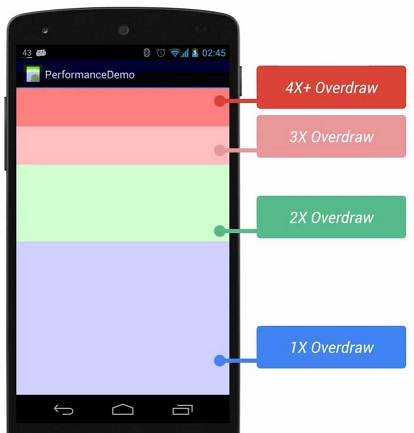
Android会在屏幕上显示不同深浅的颜色来表示过度绘制:
- 没颜色:没有过度绘制,即一个像素点绘制了1次,显示应用本来的颜色;
- 蓝色:1倍过度绘制,即一个像素点绘制了2次;
- 绿色:2倍过度绘制,即一个像素点绘制了3次;
- 浅红色:3倍过度绘制,即一个像素点绘制了4次;
- 深红色:4倍过度绘制及以上,即一个像素点绘制了5次及以上;
设备的硬件性能是有限的,当过度绘制导致应用需要消耗更多资源(超过了可用资源)的时候性能就会降低,表现为卡顿、不流畅、ANR等。
尽管大部分情况下,App 的过度绘制不可避免,但是在开发中,我们还是应该尽可能去减少过度绘制。
实际测试,可以参考以下两点来作为过度绘制的测试指标:
- 应用所有界面以及分支界面均不存在超过4X过度绘制(深红色区域);
- 应用所有界面以及分支界面下,3X过度绘制总面积(浅红色区域)不超过屏幕可视区域的1/4;
过度绘制很大程度上来自于视图相互重叠的问题,其次还有不必要的背景重叠。
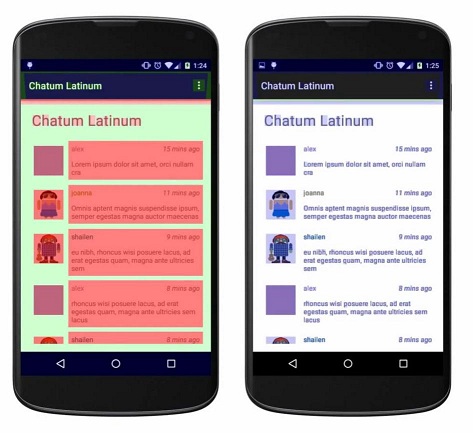
比如一个应用所有的View都有背景的话,就会看起来像第一张图中那样,而在去除这些不必要的背景之后(指的是Window的默认背景、Layout的背景、文字以及图片的可能存在的背景),效果就像第二张图那样,基本没有过度绘制的情况。
自定义控件
在自定义控件的时候也会遇到过度绘制的问题,比如我们连续绘制3遍同样的图片,效果如下图所示:

绘制的代码为:
1 | protected void onDraw(Canvas canvas) { |
语句解释:
- 本范例只是为了演示效果,实际开发中不要在onDraw方法中加载Bitmap对象。
- 从效果图里可看出来,在三张图重合的部位,显示出了绿色和红色。
我们可以通过canvas.clipRect()这个方法来设置需要绘制的区域,这个方法用来指定一块矩形区域,只有在这个区域内才会被绘制,在区域之外的绘制指令都不会被执行。

绘制的代码为:
1 | protected void onDraw(Canvas canvas) { |
语句解释:
- 简单的说,前两张图片我们只绘制了50的宽度,第三张图片才绘制了完整宽度。
内存抖动
Android系统里面有一个Generational Heap Memory的模型(具体后述)。
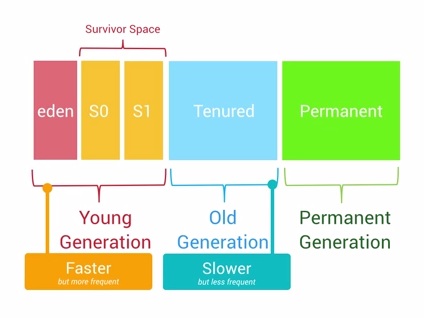
事实上,新创建的对象会先被存放在Young Generation区域,当该对象在这个区域停留的时间达到一定程度,它会被移动到Old Generation,最后到Permanent Generation区域。
- 每一个级别的内存区域都有固定的大小,此后不断有新的对象被分配到此区域,当这些对象总的大小快达到这一级别内存区域的阀值时,会触发GC的操作,以便腾出空间来存放其他新的对象。
- GC所占用的时间和它是哪一个Generation也有关系,Young Generation的每次GC操作时间是最短的,Old Generation其次,Permanent Generation最长。
内存抖动是因为大量的对象被创建又在短时间内马上被释放,如下图所示:
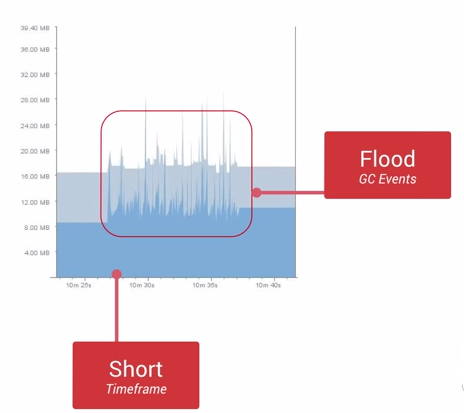
- 瞬间产生大量的对象会严重占用Young Generation的内存区域,当达到阀值剩余空间不够的时候,也会触发GC。
- 即使每次分配的对象占用了很少的内存,但是他们叠加在一起会增加Heap的压力,从而触发更多其他类型的GC。
- 这个操作有可能会影响到帧率(因为GC时会暂停所有线程的执行,包括主线程),并使得用户感知到性能问题。
- 比如二维码扫描的界面就很容易出现内存抖动的问题。
渲染性能
渲染性能往往是掉帧的罪魁祸首,这种问题很常见,让人头疼。好在Android给我们提供了一个强大的工具,帮助我们追踪性能渲染问题,看到究竟是什么导致你的应用出现卡顿、掉帧。
追踪渲染性能
通过在手机的开发者选项里打开GPU 呈现模式分析,来查看应用所有界面及分支界面下的渲染性能,方便进行优化。
这个工具会在屏幕上实时显示当前界面的最近128帧的GPU绘制图形数据,包括StatusBar、NavBar,以及我们最关心的当前界面的GPU绘制图形柱状图数据。
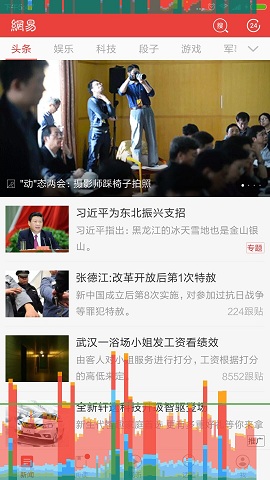
中间有一条绿线,代表16ms,保持动画流畅的关键就在于让这些垂直的柱状条尽可能地保持在绿线下面,任何时候超过绿线,你就有可能丢失一帧的内容。
布局变化的问题
布局中的任何一个View一旦发生一些属性变化,都可能引起很大的连锁反应。例如某个button的大小突然增加一倍,有可能会导致兄弟视图的位置变化,也有可能导致父视图的大小发生改变。当大量的layout()操作被频繁调用执行的时候,就很可能引起丢帧的现象。
本节参考阅读:
代码优化
本节将介绍一些常见的写代码技巧,通过它们可以避免一些内存的消耗,提高程序运行速度。
ArrayMap
在Android开发时,我们使用的大部分都是Java的API(比如使用率非常高HashMap):
- 但是对于Android这种对内存非常敏感的移动平台,很多时候使用一些java的API并不能达到更好的性能,相反反而更消耗内存。
- 所以针对Android这种移动平台,Google也推出了更符合自己的API,比如SparseArray、ArrayMap用来代替HashMap在有些情况下能带来更好的性能提升。
笔者在《媒体篇》中简单的介绍了HashMap的特点:
- 通过计算元素的hashCode码,实现高速存取元素。
- 内部使用数组+链表来存储元素。
- 元素无序排列。如果你想让集合中元素按照插入的顺序排列可以使用LinkedHashMap类。
下面继续来介绍一下HashMap,并从源码的角度来说明它的一个显著的缺点:浪费内存。
内部原理
开发中,我们常会使用数组和链表来存储数据,但这两者基本上是两个极端。
数组:
- 特点:在内存中开辟连续的存储空间,顺序存储每一个数据元素,相邻的两个元素紧挨着存储。
- 优点:使用下标对元素进行高速的存取。
- 缺点:插入和删除的效率低,因为需要移动元素;尤其在数组的前部进行数据的插入和删除操作。
链表:
- 特点:链表中的结点分散在内存中的各个角落,相邻的结点间通过指针联系。
- 优点:
- 第一,链表中的结点,只有在需要的时候才去建立,不必事先开辟过多空间。
- 第二,删除和增加结点时,不需要移动元素。
- 缺点:链表无法高速存取,当需要查找元素时,只能从表头开始依次遍历,而且每个元素都多出一个指针字段。
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是哈希表。
- 哈希表通常由数组和链表组合而成。
- 当存取元素时,会进行如下操作:
- 首先,使用元素来计算出一个值index。
- 然后,将元素存到存到数组的第index位置上去。
- 接着,若数组的index位置上已经有元素了,则会把该元素放到已有元素的后面。
哈希表大体的样子如下图所示:
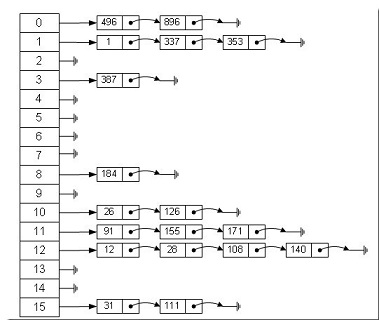
而HashMap就是基于哈希表结构的。
源码阅读
既然上面说HashMap内部使用数组+链表来存储元素,那么数组总有存满的时候,我们来看看它的put方法:
1 | public V put(K key, V value) { |
语句解释:
- 通过上面的注释可以读明白HashMap的put方法到底做了哪些事。
接下来,我们再来看一下doubleCapacity方法的代码:
1 | private HashMapEntry<K, V>[] doubleCapacity() { |
语句解释:
- 从本范例中可以看出,每当HashMap扩容的时候,都会执行一次复制元素的操作。
问题所在
仔细观察上面的哈希表结构图就会发现一个问题:
- 假设我们有100个元素,在极端的情况下,这100个元素全都被放到数组的第一个元素的链表里了。
- 那么导致的问题就是,数组的其它99个位置是空的。
- 如果元素持续增加的话,就造成了大量的内存浪费,因为元素都集中到某几个链表里了,数组的利用率缺很低。
- 也就是说,数据分布需要均匀(最好数组的每项都只有一个元素),不能太紧也不能太松。
当然,这个问题HashMap肯定考虑到了,但是即便如此也还是存在“数据分布不均匀”的情况。
- 而且从源码上也可以看到,如果HashMap中已经有100个元素了,那么HashMap中的数组可不只100个元素,因为它还需要有预留位置。
- 这意味着HashMap的元素越多,它的空闲状态的预留位置也就可能越多。
这个问题在Java(或则Java服务器端)开发的时候也许不算问题(因为它们不涉及到图片显示,内存主要用来存对象和数据,而且服务端的内存通常都比较大)。但是在Android开发时就不能忍了,所以就有了ArrayMap等类。
ArrayMap的特点
从本质上来说,ArrayMap是牺牲了存取速度,来换取内存的节省。
通过阅读源码可知,ArrayMap使用如下的数组来保存数据:
1 | Object[] mArray; |
语句解释:
- 第n个元素(n>=1)的key保存在mArray[n-1]的位置上。
- 第n个元素(n>=1)的value保存在mArray[n]的位置上。
按照一般的思路,当我们调用arrayMap.get(key)时候,是这样的流程:
- 首先,在ArrayMap中for循环,依次让key和每一个元素的key进行比较。
- 然后,当找到相同的key时,就把key所在位置(n)的下一个(n+1)位置上的元素返回。
这个过程是没有错误的,但是效率太低了,随着数据的增多,遍历的时间也就越久。
为了解决这个问题,ArrayMap中还定义了另一个数组:
1 | int[] mHashes; |
语句解释:
- 它用来保存每一个元素的key的hashCode码。
- 当往ArrayMap中添加数据时,ArrayMap除了会把key/value添加到mArray外,还会把key的hashCode码放到mHashes中。
这样一来,执行get操作的步骤就变为了:
- 首先,ArrayMap会计算出key的hashCode码,我们假设它是x。
- 接着,使用二分查找法从mHashes查找是否存在x,如果存在,则把x的下标记下来,我们假设它是index。
- 最后,ArrayMap直接使用mArray[index<<1]和mArray[index<<1+1]就可以获得元素的key和value了。
- “<<”表示左移,每左移1位数字就变大2倍,而index<<1就表示左移一位。
通过一个mHashes数组,就大幅度提高了查找元素的效率。不过官方对ArrayMap也有说明:
- 它相比传统的HashMap速度要慢,因为查找方法是二分法,并且当你删除或者添加数据时,会对空间重新调整,在使用大量数据时,效率并不明显,低于50%。
- 但是,如果元素能控制在千以内的话,使用ArrayMap完全不需要考虑效率问题。
而日常开发时集合里元素低于1000的情况还是比较多的,所以推荐使用ArrayMap。
本节参考阅读:
SparseArray
有时候性能问题也可能是因为那些不起眼的小细节引起的,例如在代码中不经意的“自动装箱”。
我们知道,系统为了能够让基础数据类型正常运作,会做一个autoboxing的操作,比如将int转换成Integer对象。
如下演示了循环操作的时候是否发生autoboxing行为的差异:

Autoboxing的行为还经常发生在类似HashMap这样的容器里面,对HashMap的增删改查操作都会发生。
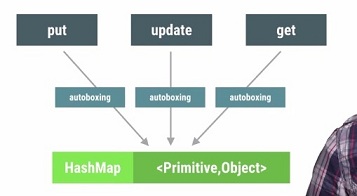
为了避免HashMap的autoboxing行为,系统提供了下面几个容器:
- SparseArray:key是int,value是Object。
- SparseBooleanArray:key是int,value是boolean。
- SparseIntArray:key是int,value是int。
- SparseLongArray:key是int,value是long。
- 这些容器的使用场景也和ArrayMap一致,需要满足数量级在千以内,数据组织形式需要包含Map结构。
Enum
假设我们有这样一份代码,编译之后的dex大小是2556 bytes,在此基础之上,添加一些如下代码,这些代码使用普通static常量相关作为判断值:
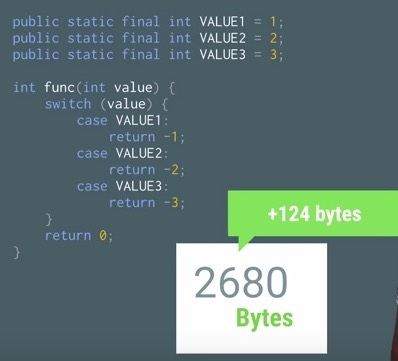
增加上面那段代码之后,编译成dex的大小是2680 bytes,相比起之前的2556 bytes只增加124 bytes。假如换做使用enum,情况如下:

使用enum之后的dex大小是4188 bytes,相比起2556增加了1632 bytes,增长量是使用static int的13倍。不仅仅如此,使用enum,运行时还会产生额外的内存占用,如下图所示:
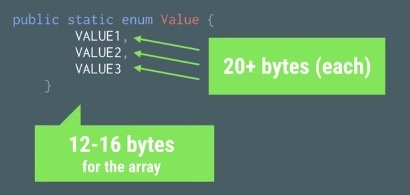
因此,Android官方强烈建议不要在程序里面使用到enum。
ListView
首先,这是一个悲伤的故事:
- 笔者之前在面试的时候,有两次被面试官问到过:“你有哪些ListView优化的方法?”,由于之前没特意优化过ListView,所以只回答出常见的几个方式,因此面试官不太满意。
- 我对此有不同的看法:我更看重的是面试者解决问题的方法和能力,因为“ListView的优化”这个问题,对代码功力要求的不高,反而对知识储备有要求;甚至于学会一种优化的方法可能只需要几分钟的时间而已。
然后,我们收拾一下悲伤的心情,来看看到底有哪些坑爹的优化方法。
最常见的优化方法:
1、使用convertView和ViewHolder类,且ViewHolder应该是静态的(防止持有外部类引用)。
2、延迟加载。即等待滚动条停止的时候再加载,滚动的时候也停止gif动画的播放。
3、异步加载。对于体积比较大的图片等资源,应该在子线程中加载,防止阻塞主线程。
4、防止过度绘制。
5、在getView方法中尽可能少创建对象
最常见的情况,就是为Button设置点击监听器了:
1 | public class MyListViewAdapter extends BaseAdapter { |
语句解释:
- 不注意的话,就会有人在getView方法里setOnClickListener(new ...),这样每次getView被调用时,程序都会创建一个监听器对象,这样是很影响效率和内存的。
- 按照上面的写法,整个ListView中所有的Button就共用一个点击事件监听器了。
6、简化每个Item的布局文件的嵌套层级
推荐阅读:《听FackBook工程师讲Custom ViewGroups》
7、局部刷新
调用notifydatasetchange通知ListView刷新界面会造成getView方法被多次调用,如果是很明确的知道只更新了某一个项的数据,应该尽量避免getView被无辜的多次调用。
解决的方法就是,手动调用getView方法:
1 | private void updateSingleRow(ListView listView, long id) { |
语句解释:
- 其实可以直接使用recyclerView,它默认就支持局部刷新。
8、采用TextView的预渲染方案
推荐阅读:《TextView预渲染研究》,但该文的作者好像也没把这个优化用到实际项目中。
目前,笔者只找到上面这8个方法,以后如果发现其他方法,那么也会继续更新。
本节参考阅读:
Parcelable和Serializable
我们知道,在开发时不能将对象的引用直接传给目标Activities或者Fragments,而是需要先将它们放到一个Intent或Bundle里面,然后再传递。
我们有两种方式可以将对象放到Intent或Bundle里面,即对对象进行Parcelable或者Serializable化。作为Java开发者,相信大家对Serializable机制有一定了解,那为什么还需要Parcelable呢?
为了回答这个问题,让我们分别来看看这两者的差异。
范例1:Serializable简单易用。
1 | public class SeriaPerson implements Serializable { |
语句解释:
- 你只需要对某个类以及它的属性实现Serializable接口即可,无需实现其它任何方法,Java便会对这个对象进行序列化操作。
- 序列化时使用了反射,从而导致序列化的过程较慢;而且在序列化过程中会产生大量的临时对象,从而更加频繁的触发GC。
甚至于直接将一个对象转成JSON格式的字符串,然后保存到本地的效率,都可能比使用Serializable接要高,点击阅读 。
范例2:Parcelable速度至上。
1 | public class ParcelPerson implements Parcelable { |
语句解释:
- 根据google工程师的说法,这些代码将会运行地特别快。原因之一就是我们已经清楚地知道了序列化的过程,而不需要使用反射来推断。
- 不过,很明显实现Parcelable需要写大量的代码,这使得对象代码变得稍微有点难以阅读和维护。
速度测试
当然,我们还是想知道到底Parcelable相对于Serializable要快多少。
范例3:测试代码。
1 | // AActivity.java |
语句解释:
- 首先,本范例在启动Activity之前,往Intent里面放了1000个对象。
- 然后,在BActivity的onCreate中打印接收到的时间。
- 接着,分别测试使用ParcelPerson和SeriaPerson类时,所消耗的时间。
- 最后,在笔者小米Note手机上测试结果为:
- 使用SeriaPerson类的耗时,大约在200毫秒。
- 使用ParcelPerson类的耗时,大约在100毫秒。
- 需要注意的是,我们写的只是测试代码,实际使用的时候,耗时会随着类的字段数量和结构复杂度的提升而提升。
另外,Parcelable除了效率高外,在IPC等场景下我们只能使用Parcelable类,所以以后就尽量别用Serializable了。
本节参考阅读:
遍历列表
在Java语言中Iterator是一个比较常见的遍历方法,但是在Android中大家却尽量避免使用Iterator来遍历。
下面我们看下三种不同的遍历方法:
1 | // for index,即下标遍历 |
使用上面三种方式在同一台手机上,使用相同的数据集做测试,它们的表现性能如下所示:
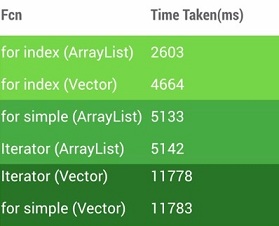
从上面可以看到for index的方式有更好的效率,但是因为不同平台编译器优化各有差异,我们最好还是针对实际的方法做一下简单的测量比较好,拿到数据之后,再选择效率最高方式。
图片处理
调整解码率
常见的png,jpeg,webp等格式的图片在设置到UI上之前需要先载入内存,而载入时可以选择不同的解码格式,不同的格式对内存的占用是有很大差别的。
Android为图片提供了4种解码格式:
- ARGB_8888 每个像素点占32位(即4个字节)
- RGB_565 每个像素点占16位(即2个字节)
- ARGB_4444 每个像素点占16位(即2个字节)
- ALPHA_8 每个像素点占 8位(即1个字节)
另外,低解码格式能节省内存,但清晰度也会有损失,所以需要针对不同场景做不同的处理。
使用inBitmap属性
从Android3.0开始,我们可以在加载位图时为BitmapFactory.Options的Bitmap inBitmap属性设置值。
- 该属性用来告知系统在加载Bitmap时先不要去申请新的内存空间,而是去尝试使用inBitmap所对应的位图的内存区域。
- 利用这种特性,即使是上千张的图片,也只会占用屏幕所能够显示的图片数量的内存大小。
使用inBitmap需要注意几个限制条件:
- 在Api Level 11到18之间,重用的bitmap大小必须是一致的。
- 例如给inBitmap赋值的图片大小为100-100,那么新申请的bitmap必须也为100-100才能够被重用。
- 从Api Level 19开始,新申请的bitmap大小必须小于或者等于已经赋值过的bitmap大小。
- 新申请的bitmap与旧的bitmap必须有相同的解码格式,否则无法重用。例如大家都是8888的。
因此,我们可以创建一个包含多种典型可重用Bitmap的对象池,如下图所示:

Google介绍了一个开源的加载Bitmap的库: Glide ,这里面包含了各种对位图的优化技巧。
其他优化
Lint工具
Lint是Android提供的一个静态扫描应用源码并找出其中的潜在问题的一个强大的工具。
- 例如,如果我们在onDraw方法里面执行了new对象的操作,Lint就会提示我们这里有性能问题,并提出对应的建议方案。
Lint已经集成到Android Studio中了,在“Analyze”菜单中选择“Inspect Code…”,触发之后,Lint会开始工作,并把结果输出到底部的工具栏,我们可以逐个查看原因并根据指示做相应的优化修改。
网络优化
一个网络请求可以简单分为连接服务器和获取数据两个部分;本节将介绍如何在这两个部分上进行优化。
一、连接服务器优化策略
1、不用域名,用IP直连。
- 这样可以省去DNS解析过程,DNS全名Domain Name System,解析意指根据域名得到其对应的IP地址。
- 首次域名解析一般需要几百毫秒,可通过直接向IP而非域名请求,节省掉这部分时间,同时可以预防域名劫持等带来的风险。
- 当然为了安全和扩展考虑,这个IP可能是一个动态更新的IP列表,并在IP不可用情况下通过域名访问。
- 也就是说,服务器端部署了多台机器,有多个IP地址,而客户端将这些IP地址都保存起来,每次请求时选一个地址请求。
2、服务器合理部署。
- 服务器多运营商多地部署,一般至少含三大运营商、南中北三地部署。
- 配合上面说到的动态IP列表,支持优先级,每次根据地域、网络类型等选择最优的服务器IP进行连接。
- 对于服务器端还可以调优服务器的TCP拥塞窗口大小、重传超时时间(RTO)、最大传输单元(MTU)等。
二、获取数据优化策略
1、请求合并。
- 即将多个请求合并为一个进行请求,比较常见的就是一个界面涉及了多类数据,也就会发起多个请求。
2、减小请求数据大小。
- 对于POST请求,Body可以做Gzip压缩。
3、减小返回数据大小。
- 压缩:一般使用Gzip压缩。
- 精简数据格式:如JSON代替XML,WebP代替其他图片格式。
- 对于不同的设备不同网络返回不同的内容,如不同分辨率图片大小。
4、数据缓存。
- 缓存获取到的数据,在一定的有效时间内再次请求可以直接从缓存读取数据。
本节参考阅读:
电量优化
手机各个硬件模块的耗电量是不一样的,有些模块非常耗电,而有些模块则相对显得耗电量小很多。
- 电量消耗的计算与统计是一件麻烦而且矛盾的事情,记录电量消耗本身也是一个费电量的事情。
- 唯一可行的方案是使用第三方监测电量的设备,这样才能够获取到真实的电量消耗。
- 当设备处于待机状态时消耗的电量是极少的,以Nexus 5为例,打开飞行模式,可以待机接近1个月。可是点亮屏幕,硬件各个模块就需要开始工作,这会需要消耗很多电量。
网络请求
网络请求的操作是非常耗电的,其中在移动网络情况下执行网络请求比在WIFI更耗电。
移动网络不同工作强度下,对电量的消耗也是有差异的,消耗有三种状态:
- 全功率:能量最高的状态,移动网络连接被激活,允许设备以最大的传输速率进行操作。
- 低功率:一种中间状态,对电量的消耗差不多是Full power状态下的50%。
- Standby:最低的状态,没有数据连接需要传输,电量消耗最少。
总之,为了减少电量的消耗,在移动网络下,最好做到批量执行网络请求,尽量避免频繁的间隔网络请求(比如消息轮询)。
本节参考阅读:
第二节 内存优化
尽管随着科技的进步,现今移动设备上的内存大小已经达到了低端桌面设备的水平,但是现今开发的应用程序对内存的需求也在同步增长,主要问题出在设备的屏幕尺寸上——分辨率越高需要的内存越多。
熟悉Android平台的开发人员一般都知道垃圾回收器并不能彻底杜绝内存泄露等问题,对于大型应用而言,内存泄露对性能产生的影响是难以估量的,因此开发人员必须要有内存分析的能力。
为了以后能更深入的进行内存分析,我们需要先来了解内存相关的知识。
概述
名词解释
内存泄漏(Memory Leak)
有个引用指向一个不再被使用的对象,导致该对象不会被垃圾回收器回收。如果这个对象内部有个引用指向一个包括很多其他对象的集合,就会导致这些对象都不会被垃圾回收。
内存溢出(Out of memory):
当程序需要为新对象分配空间,但是虚拟机能使用的内存不足以分配时,将会抛出内存溢出异常(即我们常说的OOM),当内存泄漏严重时通常会导致内存溢出。
最大内存限制
我们都知道Android是个多任务操作系统,同时运行着很多程序,它们都需要分配内存,所以系统不可能为一个程序分配越来越多的内存以至于让整个系统都崩溃。因此每个进程的heap的大小有个硬性的限制,跟设备相关,从发展来说也是越来越大,G1:16MB,Droid:24MB,Nexus One:32MB,Xoom:48MB,但是一旦超出了这个使用的范围,OOM便产生了。
如果你想知道设备的单个进程最大内存的限制是多少,并根据这个值来估算自己应用的缓存大小应该限制在什么样一个水平,你可以使用ActivityManager#getMemoryClass()来获得一个单位为MB的整数值,一般来说最低不少于16MB,对于现在的设备而言这个值会越来越大,32MB,128MB甚至更大。
需要知道的是,就算设备的单进程最大允许是128M,操作系统也不会在进程刚启动就给它128M,而是随着进程不断的有需求是才不断的分配,直到进程达到阀值(128M),系统就会抛出OOM。
但是对于一些内存非常吃紧的比如图库、浏览器等应用,在平板上所需的内存更大了。因此在Honeycomb(Android3.0)之后AndroidManifest.xml增加了largeHeap的选项:
1 | <application |
它允许你的应用使用更多的heap,可以用ActivityManager#getLargeMemoryClass()获取允许使用的heap容量。
但是这里要警告的是,千万不要因为你的应用报OOM了而使用这个选项,因为更大的heap size意味着更多的GC时间,意味着应用的性能越来越差,而且用户也会发现其他应用很有可能会内存不足。因此只有你需要使用很多的内存而且非常了解每一部分内存的用途,这些所需的内存都是不可或缺的,这个时候你才应该使用这个选项。
扩展:为什么图片会占据大量内存?
笔者在《媒体篇》中已经介绍了,这里再次重复一下:
- 需要知道的是,图片在磁盘中占据2M的大小,并不意味着它在内存中也占据2M。
- 图片在内存中大小的公式:图片的分辨率*单个像素点占据的字节大小。
- 例如,Galaxy Nexus上的照相机所照的图片最大达到2592x1936像素(500万像素)。
- 如果位图的配置使用ARGB_8888(Android 2.3的默认配置)那么加载这个图像到内存需要19MB的存储空间(2592*1936*4bytes),直接超过了许多低端设备上的单应用限制。
JVM内存结构
接着再来看一下JVM的内存结构。
JVM会把它所管理的内存会分为若干个不同的数据区域,这些区域都有各自的用途、创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有些区域则是依赖用户线程的启动和结束而建立和销毁。
根据《Java虚拟机规范》,包括以下几个运行时数据区域:
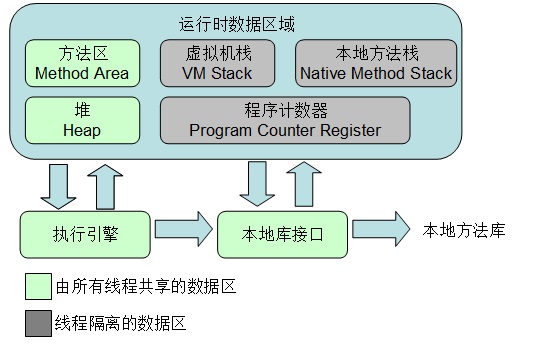
我们先抛开上图不看,而是基于自己现有的Java知识来想象一下内存应该是什么样的。
首先,Java程序是多线程的。
- 即每个进程中可以同时存在多个线程,在进程运行的时候,CPU会在它内部的多个线程之间来回切换执行。
- 那么问题来了,当CPU从线程A上切换到线程B上执行时,线程B应该从哪里开始呢?换而言之,其实每个线程都应该有自己的专属内存空间,用来保存一些自己的数据。
- 比如线程需要记录当前执行到哪一行代码了,以便当CPU切走又切换来时可以继续向下执行。
然后,还应该存在一个共有的区域。
- 无论是我们编写的代码,还是利用的第三方的类库,都是需要载入到内存的,即内存中应该有区域专门用于存储这些信息(类,方法,常量池等)。
- 这块区域应该对每个线程进行开放共享的。
最后,堆和栈。
- 从学习JAVA开始,我们就知道了内存有堆和栈的概念,而且我们都说new出来的对象是存放在堆中的,要知道JAVA是面向对象的,所以说这一块应该是占用空间较大的一块,也是内存管理、回收的一个核心点。堆,也是每个线程都可以来访问的,如果堆的空间不足了,却仍需为对象分配空间的话,就会OOM了。
- 而栈空间其实是每个线程所私有的,栈中存放的是方法中的局部变量,方法入口信息等。每一次调用方法,都涉及到入栈和出栈,如果有一个递归方法调用了几千次,甚至几万次,那么可能会因为在栈中积压了那么多信息导致栈溢出的,从而抛出StackOverFlow。
现在我们再回过头去看上面那张图就清晰一些了:
- 方法区和堆就是我们说的公共区域(线程公用)。
- 方法区用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
- 相对而言,垃圾收集行为在这个区域比较少出现,主要是针对该区域废弃常量的和无用类的回收。
- 运行时常量池是方法区的一部分,Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Class文件常量池),用于存放编译器生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
- 虚拟机栈、本地方法栈、程序计数器则是线程私有的,各个线程相互不影响。
- 程序计数器就是上面说的用来记录线程的执行位置。字节码解释器工作时,会通过改变该计数器的值来选择下一条需要执行的字节码指令,分支、循环等基础功能都要依赖它来实现。每条线程都有一个独立的的程序计数器,各线程间的计数器互不影响,因此该区域是线程私有的。
- 虚拟机栈就是上面说的栈,该区域也是线程私有的,它的生命周期也与线程相同。每个方法被执行的时候都会同时创建一个栈帧,对于执行引擎来讲,活动线程中只有栈顶的栈帧是有效的,称为当前栈帧,这个栈帧所关联的方法称为当前方法。栈帧用于存储局部变量表、操作数栈、动态链接、方法返回地址和一些额外的附加信息。
- 本地方法栈,该区域与虚拟机栈所发挥的作用非常相似,只是虚拟机栈为虚拟机执行Java方法服务,而本地方法栈则为使用到的本地操作系统(Native)方法服务。
既然上面说栈是隶属于线程的,那么栈溢出时应该只会影响其所隶属的线程才对。
范例1:事实就是如此。
1 | public class Test { |
语句解释:
- 上面的范例是Java程序,在运行后就会发现就算子线程栈溢出了,主线程依然会正常运行,如果反过来,主线程栈溢出的话,那么整个进程就会被终止了。
- 对于Android程序则不是如此,测试发现子线程Crash也会导致App闪退。
- 栈的大小因Java实现和架构的不同而不同,一些实现支持为 Java 线程指定栈大小,其范围通常在 256KB 到 756KB 之间。尽管每个线程使用的内存量非常小,但对于拥有数百个线程的应用程序来说,线程栈的总内存使用量可能非常大。
- 如果运行的应用程序的线程数量比可用于处理它们的处理器数量多,效率通常很低(因为CPU在线程间切换也是有消耗的),并且可能导致糟糕的性能和更高的内存占用。
本节参考阅读:
Java垃圾回收
Java中垃圾回收的工作由垃圾回收器 (Garbage Collector) 完成的,它的核心思想是:
- 有一组元素被称为根元素集合(GC Roots),它们是一组被虚拟机直接引用的对象,比如,正在运行的线程对象,方法区中的类静态属性(以及常量)引用的对象等。
- GC会对虚拟机可用内存空间中的对象进行识别,主要是堆空间。
- GC会从这些根节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,就证明此对象是不可用的(可以被回收)。
- 也就是说,存活对象占据的内存空间不能被回收和释放,垃圾对象的空间则可以。
- 如果说一个对象已经不被任何程序逻辑所需要但是还存在被根元素引用的情况,我们就说这里存在内存泄露。
由于下图蓝色部分没有直接或者间接引用到GC Roots,所以它们就是垃圾,会被GC回收掉:
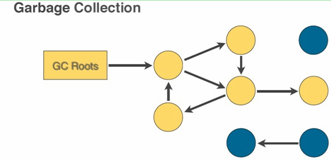
从图中也可以看出,更大的heap size需要遍历的对象更多,所以说使用largeHeap选项会导致更多的GC时间。
- 另外需要注意的是,Activity有View的引用,View也有Activity的引用,默认情况下当Activity被finish掉之后,Activity和View的循环引用已成孤岛,它们不再引用到GC Roots,因此它们之间无需断开也会被回收掉。
- 这和上图底部的那两个对象的情况是一样的。
从上面可知,若对象的(强)引用被某个GC Root对象所持有,那么该对象就不会被当做垃圾回收掉。
另外从JDK1.2版本开始,Java把对象的引用分为四种级别,强引用、软引用、弱引用和虚引用,简单的说:
- 强引用:是Java程序中最普遍的,只要强引用还存在,GC宁愿抛OOM也不会回收掉被引用的对象。
- 软引用:若对象存在强引用,则对象不会被GC回收,同时它的软引用也不会返回空,否则GC会在系统内存不够用时回收该对象,当该对象被回收后,它的软引用将返回空。需要注意的是,软引用返回空有两个条件:系统内存不足和对象没有强引用;只满足某一条是不行的,比如若对象只是没有强引用时你主动调用gc后,你立刻访问软引用所引用的对象,是可以获取到该对象的。
- 弱引用:它的强度比软引用更弱些,被弱引用关联的对象只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。若对象存在强引用则不会回收弱引用。
- 虚引用:最弱的一种引用关系,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的是希望能在这个对象被收集器回收时收到一个系统通知。
范例1:测试软引用。
1 | // 本范例是一个Java程序。 |
应用层开发中只有强引用和弱引用比较常用,而且非常简单不再冗述,笔者下面来介绍一下引用队列的概念。
引用队列配合Reference的子类使用,当Reference所指向的内存空间被GC回收后,该对象就会被追加到引用队列的末尾。
范例1:引用队列的使用。
1 | public class Test { |
语句解释:
- 引用队列的poll方法用来从队列中出队一个元素,若队列为空则返回null。
表面上来看引用队列好像没什么屌用,但那只是表面上看。
在Github上有一个检测内存泄露的项目 leakcanary ,现在市面上有大量的项目都集成了它,它就是利用了引用队列的特性。
我们来看一下 leakcanary 的源码,它是如何利用引用队列的。
范例2:com.squareup.leakcanary.RefWatcher代码片段。
1 | // 当Activity被finish时,程序就会调用这个watch方法。 |
语句解释:
- 多的也不说了,大家可以去试一试 leakcanary 的效果。
了解了leakcanary后,咱们还得把话说回来。
在Gingerbread(Andrid2.3)之前,GC执行的时候整个应用会暂停下来执行全面的垃圾回收,因此有时候会看到应用卡顿的时间比较长,一般来说>100ms,对用户而言已经足以察觉出来。Gingerbread及以上的版本,GC做了很大的改进,基本上可以说是并发的执行(注意只是基本上,实际上在GC时还是会有暂停所有线程的操作),并且也不是执行完全的回收。只有在GC开始以及结束的时候会有非常短暂的停顿时间,一般来说<5ms,用户也不会察觉到。
注意,Android4.4引进了新的ART虚拟机来取代Dalvik虚拟机。它们的机制大有不同,简单而言:
- Dalvik虚拟机的GC是非常耗资源的,并且在正常的情况下一个硬件性能不错的设备,单次GC很容易耗费掉10-20ms的时间;
- ART虚拟机的GC会动态提升垃圾回收的效率,单次GC通常在2-3ms之间,比Dalvik虚拟机有很大的性能提升;
- 虽然单次GC时间被大幅缩短了,但我们仍需要尽可能避免产生过多的GC操作,特别是在执行动画的情况下,过多次的GC仍可能会导致一些让用户明显感觉的丢帧。
推荐阅读:《Android 4.4的ART虚拟机性能实测:任务切换更迅速》
最后,再来看一下常见的 GC Root :
- Class:由系统类加载器加载的对象,这些类是不能够被回收的,他们可以以静态字段的方式保存持有其它对象。
- Thread:已经启动且正在执行的线程。
- JNI Local:JNI方法的local变量或参数。
- JNI Global:全局JNI引用。
- Monitor Used:用于同步的监控对象。
常见内存泄露
在应用层开发的兄弟,最常见到内存问题应该就是因为OOM了。
从早期G1的192MB RAM开始,到现在动辄2G - 3G RAM的设备,系统为单个App分配的内存从16MB到48MB甚至更多,但OOM从不曾离我们远去。这是因为大部分App中图片内容占据了50%甚至75%以上,而App内容的极大丰富,所需的图片越来越多,屏幕尺寸也越来越大分辨率也越来越高,所需的图片的大小也跟着往上涨,这在大屏手机和平板上尤其明显,而且还经常要兼容低版本的设备,所以Android的内存管理显得极为重要。
本节先来介绍几个常见的内存泄漏的范例,以便在以后写代码的时候可以避免掉。
范例1:Handler导致的泄露。
1 | public class HandlerActivity extends Activity { |
猛地一看并没有什么问题,但是Eclipse或Android Studio却会有如下警告:
This Handler class should be static or leaks might occur (com.example.ta.HandlerActivity.1)
大体的意思是:Handler应该使用静态声明,不然可能导致HandlerActivity被泄露。
为啥出现这样的问题呢?这是因为:
- 首先,当在主线程中初始化Handler时,该Handler会和主线程中的Looper的消息队列关联。
- 然后,通过Handler发送的消息,会被发送到Looper的消息队列里,直到消息被处理。
- 接着,但是通过Handler对象发送的消息会反向持有Handler的引用,这样系统可以调用Handler#handleMessage(Message)来分发处理该消息。
- 最后,由于消息会延迟60秒处理,因此Message对象的引用会被一直持有,同时导致Handler无法回收,又因为Handler是实例内部类,所以最终会导致Activity被泄漏。
也许你会说“我不去执行这种延期的Message不就行了”,但是:
- 首先,你不会执行但你不能保证你同事也不会执行。
- 然后,由于程序中可以存在多个Handler,并且一般情况下都是在主线程中处理消息,因此你也不能保证在其他地方的Handler对象不会阻塞主线程,进而导致你的Message被迫延迟处理。
- 因此,为了避免这些未知的情况,我们尽量不要这么写代码。
如何避免呢?
最简单的方法就是把Handler写成一个外部类,不过这样一来就会多出很多文件,也难以查找和管理。
另一个方法就是使用静态内部类+软引用:
1 | public class HandlerActivity2 extends Activity { |
语句解释:
- 本范例中创建了一个名为MyHandler的静态内部类,与实例内部类不同的是,静态内部类不会默认持有其外部类的引用。
- 在构造MyHandler类的对象时,虽然仍需要传递一个HandlerActivity2的引用过去,但MyHandler类不会持有它的强引用,因而不会阻止HandlerActivity2回收。
范例2:Thread导致的泄露。
1 | public class ThreadActivity extends Activity { |
语句解释:
- 在MyThread执行结束之前,Activity也会一直被持有,解决的方法同样也是静态内部类+软引用。
- 此时你可能会有疑问,在范例1中,Activity被泄漏是因为Handler对象被持有,但是这里的Thread对象是一个匿名对象,没有任何人持有它,为什么也会导致Activity泄漏呢?
- 因为Thread对象是GCRoot对象,虽然没有被引用,但是一旦它被启动了,那直到它执行完毕,都不会被回收。除非程序被切到后台且因为系统内存不足,该进程被系统杀掉进而终止线程。
范例3:HanderThread对象是如何防止泄露的。
1 | for (;;) { |
本节参考阅读:
内存优化
实际工作中遇到的问题可不会像上一节说的那么简单,假设Leader给你一个任务,让你把你们进程所占的内存在原有的基础上降低15M,你是不是就不知道要如何下手了?
不要怕,本节将通过解决内存泄漏的问题,来让大家对内存优化有一个简单的认识。
预备知识
知己知彼才能胜利,因此“想优化,就得先了解”,我们只有先了解现有进程的内存占用情况,才能制定出相应的优化方案。
1、进程占了多少内存?
通常我们会通过Android Studio(以后简称AS)里的Android Monitor或者DDMS来查看某个进程所占的内存值,一般情况下是没问题的,但是它不是很精确。
推荐使用adb命令来查看进程的内存(要把手机连接到电脑上不用我说了吧?):
1 | adb shell dumpsys meminfo com.android.systemui |
下图是输出的内容摘要:
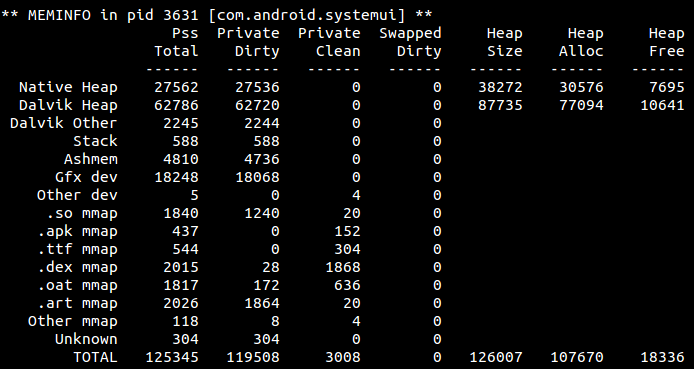
这些字段的含义为:
- Native Heap行和Dalvik Heap行,分别表示当前进程的Native堆和Dalvik堆的大小,这些数字的单位都是KB。
- Heap Size列表示堆的总大小,它与后两者的关系是 Heap Size = Heap Alloc + Heap Free。其实AS和DDMS中所显示的堆大小、已分配、空闲内存,就是这三个字段的值。
- Pss Total列表示实际占用的内存值,比如Dalvik Heap的Pss Total占了62M,即Heap Alloc并不是堆的实际内存大小,Pss Total才是(具体后述)。
- 最后一行就是一个合计,它的Pss Total就是表示当前进程最终占据的实际内存大小,即125M。
2、手机总内存
整个系统的已用内存就是各进程的Total Pss的总和,执行如下命令可以查看所有进程的内存和系统总内存:
1 | adb shell dumpsys meminfo |
下图是输出的内容摘要:

这些字段的含义为:
- Total RAM表示手机的总内存,我的手机是3G的;另外三项也很容易理解,分别是:空闲内存、已使用内存、丢失内存。
- 上面四者的关系是:Total = Free + Used + Lost。
- 其中Used RAM就是由当前系统中所有正在运行的进程的Pss Total的值加在一起得到的。
3、堆转储文件
既然是内存优化,那最容易想到的方法就是,检测并修复进程中存在的泄漏。
因此,除了要知道进程占了多少内存外,还得去获取进程的详细内存log,有了log之后,就可以通过分析log,来知道进程的内存都被什么对象占据了。
堆转储文件(Heap Dump)就是我们说的log文件。
它是某个时刻对一个Java进程所使用的堆内存情况的一次快照,也就是在某个时刻把Java进程的内存以某种格式持久化到了磁盘上,通常以.hprof为后缀名。
- 不同厂家的JVM所生成的堆转储文件在数据存储格式以及数据存储内容上有很多区别。
- 比如Oracle、HP、IBM等。
- 但总的来说,Heap Dump一般都包含了一些堆中的Java Objects,Class等基本信息。当你在执行一个转储(dump)操作时,往往会触发一次GC,所以你转储得到的文件里包含的信息通常是有效的内容(包含比较少,或没有垃圾对象了)。
大家可以在 DDMS 或 Android Studio 中自己 dump 出 hprof 文件(具体方法请自行搜索)。
接下来需要知道的是,hprof文件不是普通的文件,得需要专业的软件才能查看它的内容,目前比较常见的、用来查看hprof的软件就是MAT(稍后详述)。
这里强调一下,如果你直接使用MAT打开刚 dump 的堆转储文件的话,那么MAT通常会报如下错误:
1 | Error opening heap dump 'com.android.systemui.hprof'. Check the error log for further details. |
原因是: Android的虚拟机导出的hprof文件格式与标准的java hprof文件格式标准不一样,根本原因两者的虚拟机不一致导致的。解决方法:使用sdk\platform-tools\hprof-conv.exe工具转换就可以了:
1 | hprof-conv 源文件 目标文件 |
MAT入门
网上关于MAT的教程有很多,也很容易搜到,所以笔者就不重复造轮子了,下面主要介绍一些经验性的总结。
Memory Analyzer(MAT)是一个功能丰富的JAVA堆转储文件分析工具,可以帮助你发现内存漏洞和减少内存消耗。
通常内存泄露分析被认为是一件很有难度的工作,一般由团队中的资深人士进行。
不过,今天我们要介绍的MAT被认为是一个“傻瓜式”的堆转储文件分析工具,你只需要轻轻点击一下鼠标就可以生成一个专业的分析报告。
和其他内存泄露分析工具相比,MAT的使用非常容易,基本可以实现一键到位,即使是新手也能够很快上手使用。
先来看看MAT工具的预览界面:
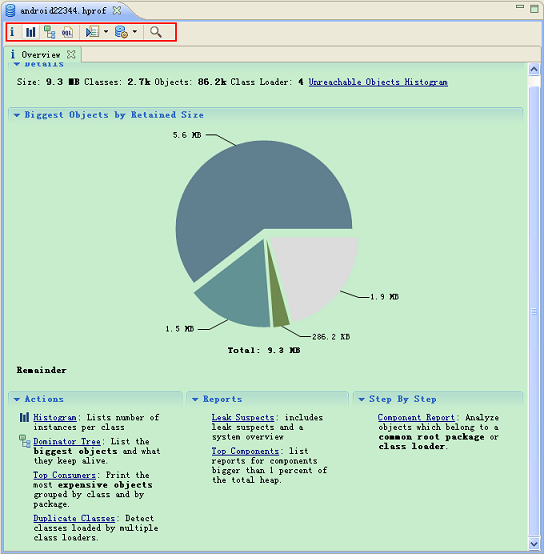
红框括起来了是一些快捷键和功能按钮,如果不小心把某个窗口给关掉后,可以通过这些按钮重新打开对应的界面。
接下来我们有两个任务要做:
第一,写一个内存泄漏的代码。
第二,导出一个堆转储文件,然后使用MAT工具来分析这个文件。
问题代码
前面说过Thread一旦被启动,那么直到它运行结束都不会被回收(当然若进程被操作系统杀掉了那么线程会中止),你可能会不信,那么咱们现在就创建一个范例,完成后面知识的讲解。
范例1:内存泄漏代码。
1 | public class MainActivity extends Activity { |
语句解释:
- 每当新建立一个Activity的时候就开启一个线程,并让这个线程运行600秒。
发现问题
若我们的项目运行一段时间后就变得很慢,那么不出意外的话是有内存泄漏了,但是由于不知道具体在哪里泄漏的,所以可能无从下手,应该怎么办呢?
在DDMS视图中的Heap选项卡中部有一个Type叫做data object,即数据对象。
在data object一行中有一列是“Total Size”,其值就是当前进程中所有Java数据对象的内存总量,一般情况下,这个值的大小决定了是否会有内存泄漏。
以我们上面的问题代码为例,程序刚启动时内存的信息为:

然后我们不断的横竖屏切换5~10次后,内存的信息为:

很明显可以看到,随着我们横竖屏切换的次数增加,“Count”和“Total Size”两列下的数值也不断的增加,并且不会减少。这基本就可以断定这个界面存在内存泄漏了。
因此我们可以这样判断是否存在内存泄漏:
- 首先,不断打开和关闭应用中的某个界面,同时注意观察data object的Total Size值。
- 然后,正常情况下Total Size值都会稳定在一个有限的范围内。
- 也就是说若程序中的代码写的很好,即便不断的操作会不断的生成很多对象,而在虚拟机不断的进行GC的过程中,这些对象都被回收了,内存占用量会会落到一个稳定的水平。
- 反之如果代码中存在没有释放对象引用的情况,则data object的Total Size值在每次GC后不会有明显的回落,随着操作次数的增多Total Size的值会越来越大,直到到达一个上限后导致进程被kill掉。
- 提示:我们可以点击DDMS视图里的“Cause GC”按钮来手动触发GC。
上面的方法是我几年前写的,现在都用AS开发,也不再会使用DDMS了,不过最新版本的AS提供了“profiler”工具,可以查看当前App的内存状态,我们可以依据App当前的内存大小来做判断。
Leak Suspects
现在,我们已经确定程序存在内存泄漏的问题了,并且也知道是哪个界面存在泄漏了,为了进一步确定是哪块代码出的问题,我们需要将该进程的内存信息导出来,生成一个.hprof文件,并加以分析。
再次提示:
- 如果你是使用MAT单机版(而不是AS或者Eclipse插件),那么你需要手动把hprof转换一下格式。
当使用MAT打开.hprof文件时,会默认打开一个名为“Leak suspects”(泄露疑点)的视图,并且生成报告给用户。
“泄露疑点”会列出当前内存中的个头大的对象,在这里列出的对象并不一定是真正的内存泄露,但它仍然是检查内存泄露的一个绝佳起点。
如下图所示:
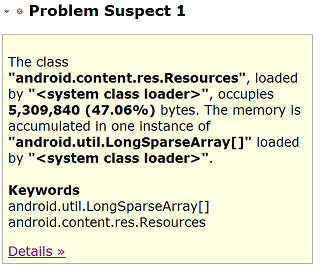
图释:
- android.content.res.Resources:类名称。
- <system class loader>:加载该类的加载器。
- 5,309,840 (47.06%):该类所有对象所占用的内存。
我们可以点击上图中的“Details »”按钮来查看详细信息。在继续向下讲解之前,还需要再插一个知识点。
浅堆和保留堆
MAT可以根据堆转储文件,以可视化的方式告诉我们哪个类,哪个对象分配了多少内存。不过要想看懂它们,则需要掌握2个概念:Shallow heap(浅堆)和Retained heap(保留堆)。
Shallow Heap是指该对象占用了多少内存(字节),不包含对其他对象的引用,也就是对象头加成员变量的头的总和。如:
1 | public class Person { // 头部8字节 |
语句解释:
- 一个对象的头部往往需要32或64比特(bit)(基于不同的平台实现,该值也会不同),在32位系统上,对象头占用8字节,int占用4字节。这些是JVM规范里规定,但不同JVM实现可以按照自己方式来存储数据。另外,基于不同的Heap Dump格式,这些值也可能会有变化,但往往会更加真实地反应出内存的占用量。
- 因此这个Person对象的浅堆大小大约为56字节。
Retained Set指的是一个对象集合。假定一些对象会由于对象X被垃圾回收(GC)后,也同时需要被GC掉,那么这些对象就属于X的Retained Set。注意,Retained Set是包含X本身的。
Retained Heap可以简单地理解为对象的Retained Set中的对象所占用的内存的总和。换句话说,Retained Heap是该对象自己的shallow size,加上从该对象能直接或间接访问到对象的shallow size之和。
1 | public class Person2 { // 头部8字节 |
笔者计算Person2对象的浅堆是36字节,就算在你的机器上计算的值与笔者计算的有偏差也不必在乎它们,因为误差不是我们关注重点。事实上,我们只是借助Person2类来理解浅堆和保留堆的概念,至于Person2类会占多少字节Who cares?,只要不是很离谱就可以了。
如果程序中有这样的代码:
1 | public class MainActivity extends Activity { |
则计算出Person和Person2的浅堆与保留堆的大小如图所示:

若是有如下代码:
1 | public class MainActivity extends Activity { |
则计算出Person和Person2的浅堆与保留堆的大小如图所示:

即Person2的保留堆为:Person2的浅堆+Person的浅堆。
这里要说一下的是,Retained Heap并不总是那么有效:
- 例如,我们new了一块内存,赋值给A的一个成员变量,同时让B也指向这块内存。
- 这样一来,由于A和B都引用到这块内存,所以当A释放时,该内存不会被释放。
- 所以这块内存不会被计算到A或者B的Retained Heap中。
- 因此我们应当只把它当作一个参考值,而不是精确的追求它的每一个字节对应的内容是什么。
话说回来
介绍完浅堆和保留堆的概念后,咱们回到“Leak suspects”上来。
不过需要说明的是,通常我们从“Leak suspects”中是没法直接得到有用的信息的,它只是一个参考界面,在很多时候是没多大屌用的,不过不要慌。
分析.hprof文件的起点有多个:
- 第一,我们确实会从“Leak suspects”开始查看,如果它没直观的提供出有用的信息,那也没关系,再换其他方法。
- 第二,使用Dominator Tree视图来继续追踪。
- 第三,使用Histogram视图来继续追踪。
Dominator Tree
MAT提供了一个称为支配树(Dominator Tree)的对象图。支配树体现了对象实例间的支配关系。在对象引用图中,所有指向对象B的路径都经过对象A,则认为对象A支配对象B。
简单的说,之所以提出支配树这个概念,就是为了计算对象的Retained Heap。
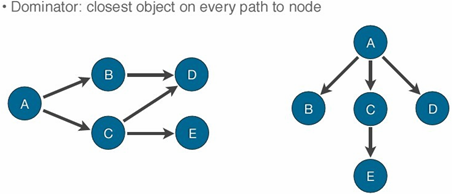
比如我们可以从上图左侧的引用图(对象A引用B和C,B和C又都引用到D)构造出右侧的Dominator Tree,计算出来的Retained Memory为:
- A的Retained Heap包括A本身和B,C,D,E。
- B和C因为共同引用D,所以B的Retained Memory只是它本身。
- C是自己和E。
- D、E当然也只是自己。
支配树有以下重要属性:
- X的子树中的所有元素表示X的保留对象集合。
- 如果X是Y的持有者,那么X的持有者也是Y的持有者。
- 在支配树中表示持有关系的边并不是和代码中对象之间的关系直接对应,比如代码中X持有Y,Y持有Z,在支配树中,X的直接子节点中会有Z。
这三个属性对于理解支配树而言非常重要,一个熟练的开发人员可以通过这个工具快速的找出持有对象中哪些是不需要的以及每个对象的保留堆。
界面介绍
支配树可以算是MAT中第二有用的工具,它依据我们设置的关键字来列出符合条件的、堆中较大的(不是所有的)对象以及它们之间的引用关系,我们可以直接在“Overview”选项页中点击“Dominator Tree”进入该工具,或者从菜单栏中也可以进入。
支配树的界面如下图所示:

表头依次代表:类名、浅堆大小、保留堆大小、百分比,可以通过点击某个表头来按特定的字段进行排序。
第一行用于输入查找条件,支持正则表达式,如需要查找出MainActivity相关的类,则可以在ClassName列的第一行输入“MainActivity”关键字。
检索出相关对象
如果你泄漏的对象所占据的内存比较大的话,那么通常在打开Dominator Tree时就可以看到它被排在前列。
但是,由于前面的范例中只是在onCreate方法里创建了线程,并没有执行显示图片等耗内存的操作,因此即便是运行时多执行几次横竖屏切换,泄漏的内存也不会很大,还不至于在Dominator Tree视图打开的时候就被列出来,所以我们得通过输入关键字“MainActivity”查找后才能看到。
如下图所示:
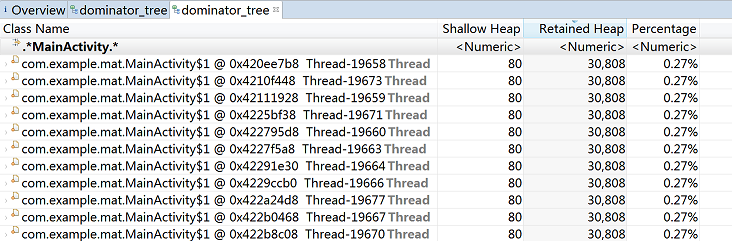
上图列出了当前内存中存在的、所有符合筛选条件(*.MainActivity.*)的对象,可以看出明显存在多个Thread对象,这显然是不正常的。
当然,在实际操作的时候情况肯定会比上面的要复杂的多。比如我们有这样一段代码:
1 | public class MainActivity extends Activity { |
语句解释:
- 本范例是通过Leaky泄露了MainActivity对象,并且我们在MainActivity中显示了一些图片。
- 接下来我们就演示一下如何通过Bitmap对象来定位出内存泄露的根源。
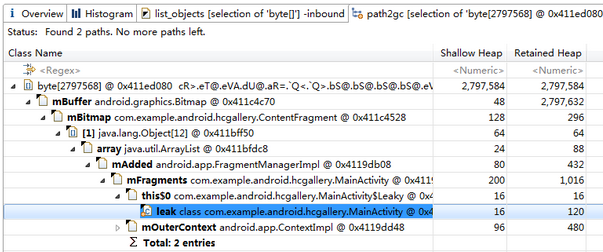
依然是打开Dominator Tree视图,由于Bitmap比较大,所以在打开Dominator Tree的第一眼就能看到它,于是我们按照下图所示的操作,来查看Bitmap的引用连:
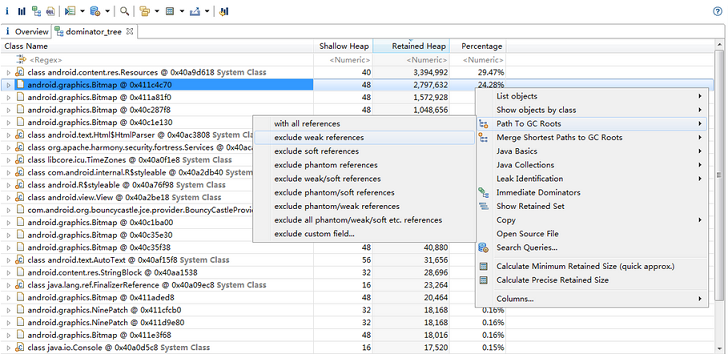
上图中排在第一的是Resources类型对象,由于一般是系统用于加载资源的,所以Retained heap较大是个比较正常的情况。但我们注意到下面有一个Retained heap很大的Bitmap对象,为了防止存在内存泄露的问题,我们就去看看它被谁引用了(如果没人引用,那这个Bitmap就被回收了,不会出现在hprof中)。
所以我们右键点击这行,选择Path To GC Roots -> exclude weak references:
- Path To GC Roots 选项用来告诉MAT将当前对象到某个GC根对象之间的所有引用链给列出来。
- exclude weak references选项用来告诉MAT,不用列出weak类型的引用,如果你只想查看强引用的话,可以直接选倒数第二项。
然后可以看到下图的情形:
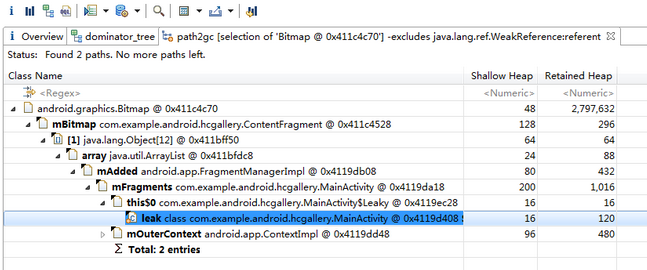
Bitmap最终被leak变量引用到,这应该是一种不正常的现象,内存泄漏很可能就在这里了。
也就是说,MAT不会告诉哪里是内存泄漏,需要你自行分析,由于这是Demo,是我们特意造成的内存泄漏,因此比较容易就能看出来,真实的应用场景可能需要你仔细的进行分析。
如果我们Path To GC Roots -> with all references,我们可以看到下图的情形:
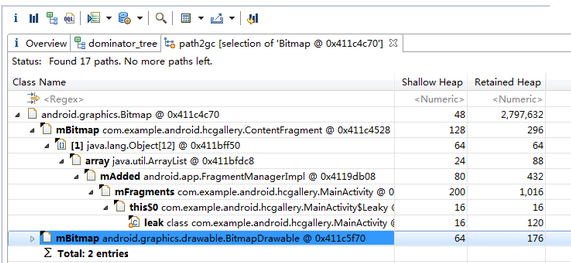
可以看到还有另外一个对象在引用着这个Bitmap对象,了解weak references的同学应该知道GC是如何处理weak references,因此在内存泄漏分析的时候我们可以把weak references排除掉。
Histogram
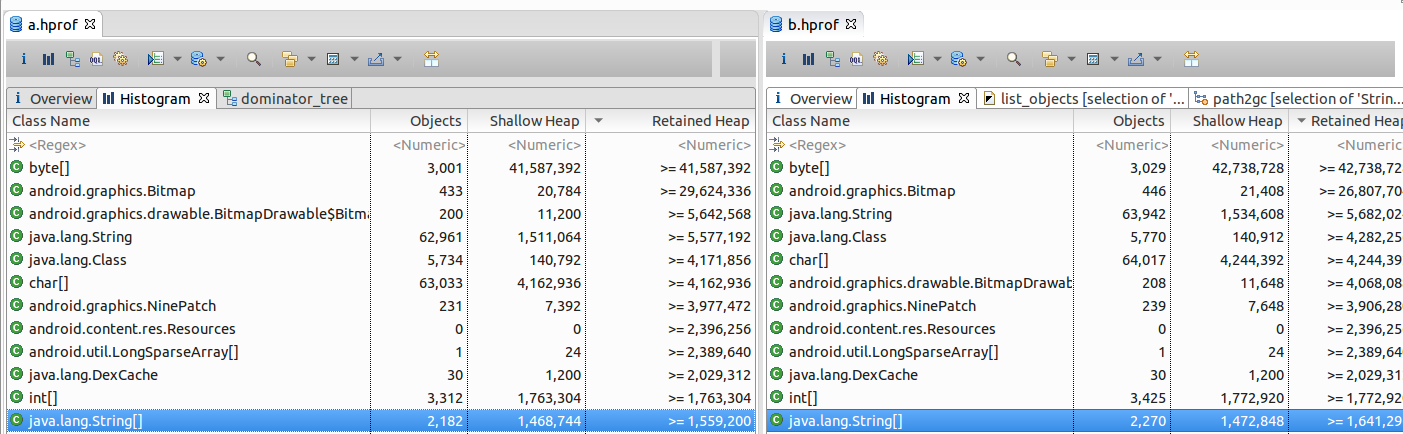
支配树用来把当前内存中的、符合筛选条件的对象,按照保留堆从大到小的顺序列出来。如果你希望根据某种类型的对象个数来分析内存泄漏,则可以使用Histogram视图。
与Dominator Tree一样,较小的对象可以通过在第一行的“ClassName”列中输入关键字进行查找。
我们在Overview视图中选择Actions -> Histogram,可以看到类似下图的情形:
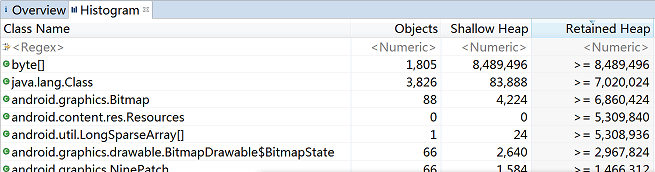
在上图中,Objects列表示内存中该类型的对象个数。
我们看到byte[]占用Shallow heap最多,那是因为Honeycomb之后Bitmap Pixel Data的内存分配在Dalvik heap中。
接下来,我们右键选中byte[]数组,选择List Objects -> with incoming references,然后可以看到byte[]具体的对象列表:
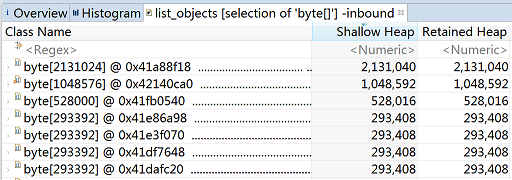
提示:
- With Outgoing References表示该对象的出节点(被该对象引用的对象)。
- With Incoming References表示该对象的入节点(引用到该对象的对象)。
从上图中我们发现第一个byte[]的Retained heap较大,内存泄漏的可能性较大。
右键选中这行,Path To GC Roots -> exclude weak references,同样可以看到上文所提到的情况,我们的Bitmap对象被leak所引用到(如下图所示),这里存在着内存泄漏。
也可以在Histogram视图中第一行输入MainActivity,来过滤出我们自己应用中的类型。
本章参考阅读:
- Memory Analyzer (MAT)
- 使用 Eclipse Memory Analyzer 进行堆转储文件分析
- Android内存泄漏研究
- Android内存泄露开篇
- Java程序内存分析:使用mat工具分析内存占用
内存泄露分析技巧
1、导出Bitmap对象。
在《 查看MAT中的bitmap》中介绍了如何把 hprof 文件里的 Bitmap 给导出来,然后查看内容。
2、sPreloadDrawables属性。
在查看hprof文件时,经常会发现一些Bitmap最终会被Resources的sPreloadDrawables属性所引用,如果导出这些图片查看的话,会发现咱们根本没用到它们,既然如此,那如果能将它们给释放掉,岂不是能降低不少内存?
其实不需要,这些图片是整个系统所有进程共有的,如果这些图片总共占25M内存的话,那这25M内存是由所有进程均摊的,所以说就算咱们把它给清了,最多也就能降低1M左右的内存。
这里 有个哥们去清理了,而且从DDMS上看内存也确实被清了,人家的结果和我说的不一样的原因是:
- 前面说过,进程真正占多少内存是由其Pss Total的值决定的,而不是Heap Size的值。
- 这是因为Heap Size是一个有点虚高的值,它也将sPreloadDrawables里的图片的一起统计了。
- 但是由于sPreloadDrawables里的图片所占的内存并不是当前进程一人承担,所以说它不是精确的值。
- 同时,从AS和DDMS中看到的其实是Heap Size的值,所以肉眼上看起来内存降低了很多,但实际上则不多。
- 如果各位不相信,可以按照他的方法清理试试,看看在清理之前和之后进程的Total Pss是否有很大差距。
第3、遍历功能。
最常见的定位内存泄露的方法就是,手动遍历进程的所有界面,一边操作一边查看进程的内存信息,观察是否存在内存泄露。比如,如果我们想测试MiuiHome进程是否存在泄露,则可以往桌面上加Widgets,具体测试步骤为:
1、先把手机重启,让手机恢复到最低的内存状态(因为Home是系统进程没法杀,只有重启手机才能让Home重置内存)。
2、起来之后,在AS或DDMS中为Home进程手动触发几次GC,然后就不要做任何操作了。
3、接着使用dumpsys meminfo命令获取com.miui.home进程的内存信息,假设它叫log1,同时也导出Home进程的hprof文件,假设它叫hprof1,这两个文件稍后会用到。
4、在桌面多放置几个大一点尺寸的Widgets,接着再把它们都给删了。
5、手动触发几次GC,确保Home进程中此时包含尽可能少的垃圾对象。
6、再次dump出com.miui.home的内存信息log2和hprof2,并让log2和log1进行比较。
7、如果log2明显比log1多出很多内存,则就接着去比较hprof2比hprof1中多了哪些东西。
8、所谓的比较两个hprof,主要就是看看它们的Histogram列出的类,比如是否多了Bitmap等(至于如何比较,后面会有范例)。
4、比较两个hprof文件。
假设我们有如下图所示的两个hprof文件,a是初始内存,b是执行N次操作后的内存:
通过观察可以发现,b里的String[]对象的个数多出了将近100个,我们接着使用“with incoming references”,去看看多出了哪些String[]。
- 你可能会说String对象还多1000呢,你怎么不看?
- 当然是先挑少的看了,不优先追踪只有2200多个对象的String[],反而去追踪有6W+对象的String?
- 不要搞事情,我跟你讲。
接着继续比较String[],如下图所示:
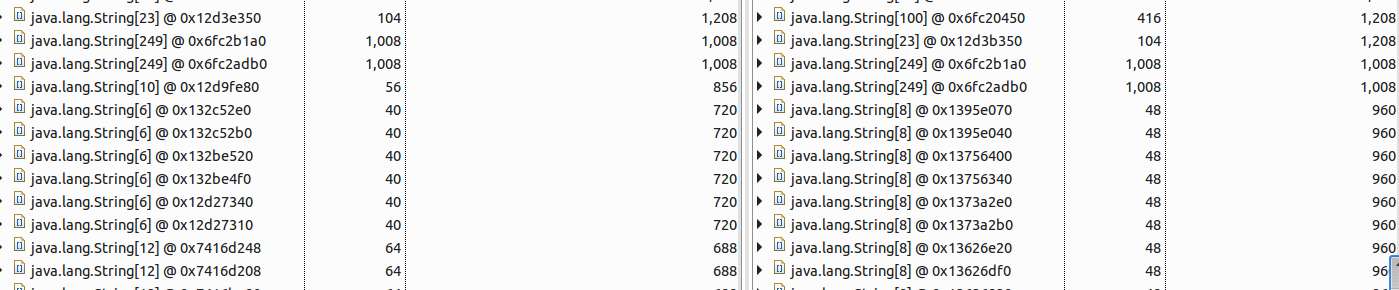
可以发现b(右侧的)里多出一些大小为960字节的String[],而a中并没有,继续追踪下去发现如下引用链:

其实走到这里就可以做出判断了:
- 首先在b.hprof中发现了大量的960字节的String[]数组。
- 然后通过查看String[]的引用链发现,这些String[]并不是共存在某个集合中的,而是一对一的被持有的。
- 因此内存中很有可能存在多个MusicListenerService对象,每个对象会间接引用一个String[]。
于是分别打开两份日志的dominator tree视图,可以看到如下所示:
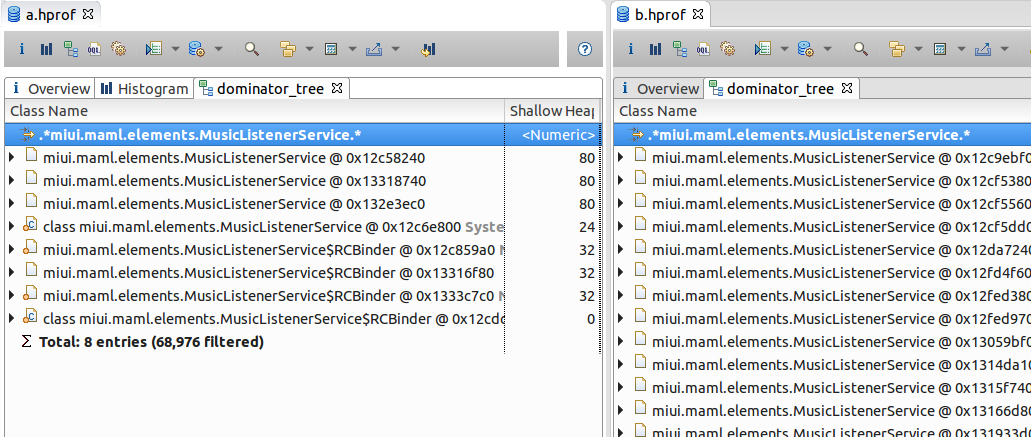
从图中可看出MusicListenerService对象泄漏了,既然找到了问题,那事情就好办了。
上面就是内存分析过程,干货就是定位问题的思路,希望对各位能有所帮助。