第一节 设计模式
在应用开发过程中,最难的不是完成应用的开发工作,而是在后续的升级、维护过程中让应用系统能够在满足需求且不破坏系统稳定性的前提下,保持高可扩展性、高内聚、低耦合,在经历了各版本的变更后依然保持清晰、灵活、稳定。
当然,这是一个比较理想的情况,但我们必须要朝着这个方向去努力。
本章主要参考《Android 源码设计模式解析与实战》,感谢二位作者的无私奉献。
问题起源
什么是设计模式?
按照百度百科的介绍:
设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。
简单的说,设计模式就是一些写代码的套路,按照这些前人总结出来的套路去写代码,写出的代码质量更高。
为什么要学设计模式?
就像一开始说的,软件开发并不难,难的是后期的维护,下面说一个笔者亲身经历的事情:
- 机缘巧合下,我需要去维护一个nodejs+python开发的网站(但之前根本没学过这两者)。
- 而且由于时间紧迫,草草学完python基础语法后,也没去深入理解现有代码的逻辑,看个大概就开始干了。
- 但是老项目的代码乱的不行,搞的我晕头转向,废了不少功夫在上面。
- 就像老话说的那样,“你觉悟的有多深,伤害就有多深”,我做为一个后来者,在亲身体验过杂乱的代码后,才下定决心去学习设计模式。
也就是说,学习设计模式是为了提高编码技巧,从而写出更容易维护和扩展的软件。
只涨工龄不涨技术
在行业内很多初、中级工程师甚至高级工程师由于某些原因都还停留在功能实现层面,甚至对设计模式、面向对象知之甚少,因此也就很少去考虑代码的设计问题,这是很不妥的,希望各位居安思危,引以为戒。
本节参考阅读:
六大原则
我们知道“面向对象”的三大特性是“封装”、“继承”、“多态”,其实在这三个特性之上,还可以延伸出六大原则,这些原则是学习设计模式所必需的知识,本节就来详细介绍一下它们。
单一职责原则
单一职责原则要求,一个类应该是一组相关性很高的函数、数据的封装;简单的说就是“一个类只做一件事”,那相应的这个类也只应该因为它做的那件事需要修改而被修改。
比如领导让我们写一个图片加载库,要求能在内存中缓存图片,于是写出如下第一版代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public class ImageLoader {
// 图片缓存
LruCache<String, Bitmap> mImageCache;
// 线程池,线程数量为CPU的数量
ExecutorService mExecutorService
= Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public ImageLoader() {
initImageCache();
}
// 此方法用来初始化mImageCache缓存对象,比如设计缓存区的大小等。
// 之所以不把方法的具体实现给写出来,是想让大家把关注的重心放到代码的结构上。
private void initImageCache() { }
// 此方法由外界调用,用来执行图片加载的操作。
public void displayImage(final String url, final ImageView imageView) {
// 在子线程中执行操作
mExecutorService.submit(new Runnable() {
public void run() {
// 下载图片
Bitmap bitmap = downloadImage(url);
// 通知主线程将Bitmap设置到ImageView中。
// ...
// 将Bitmap加入到缓存。
mImageCache.put(url, bitmap);
}
});
}
// 此方法只负责在当前线程中执行网络请求,接收一个url,返回一个Bitmap对象。
private Bitmap downloadImage(String imageUrl) { }
}
语句解释:
- 如果你看不出这段代码的问题,那么本文将要介绍的知识就十分适合你了。
- 其实这个ImageLoader根本就没有设计可言,更不要说扩展性、灵活性了,因为它把所有的功能都写在一个类,即图片的加载和图片的缓存是两件很大的事情,每一件事情都需要处理各种异常情况、写很多代码,因此它们不应该由一个类来承担,随着时间的推移这个类将越来越难维护。
修改的方法也很简单,将图片加载和图片缓存分别交给两个类去做,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// 负责内存缓存
public class ImageCache {
// 图片LRU缓存
LruCache<String, Bitmap> mImageCache;
public ImageCache() {
initImageCache();
}
private void initImageCache() {
}
public void put(String url, Bitmap bitmap) {
mImageCache.put(url, bitmap) ;
}
public Bitmap get(String url) {
return mImageCache.get(url) ;
}
}
// 负责图片加载
public class ImageLoader {
private ImageCache mImageCache = new ImageCache();
// 线程池,线程数量为CPU的数量
ExecutorService mExecutorService =
Executors.newFixedThreadPool (Runtime.getRuntime().availableProcessors());
// 此方法只负责执行网络请求,接收一个url,返回一个Bitmap对象。
private Bitmap downloadImage(String imageUrl) { }
// 此方法由外界调用,用来执行图片加载的操作。
public void displayImage(final String url, final ImageView imageView) { }
}
语句解释:
- 修改之后情况变的好一些了,但是依然存在不少问题,后面会一一指出。
其实大家也可以看出来,单一职责的划分界限并不是总是那么清晰,很多时候都是需要靠个人经验来界定。当然最大的问题就是对职责的定义,什么是类的职责,以及怎么划分类的职责。
开闭原则
开闭原则的定义是:软件中的对象(类、模块、函数等)应该对于扩展是开放的,对于修改是封闭的。
开闭原则认为一旦完成,一个类只应该因错误而修改,新的或者改变的特性应该通过新建不同的类实现。
- 在实际工作中,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会将错误引入原本已经经过测试的旧代码中,破坏原有系统。因此,我们应该尽量让代码事先就支持通过扩展(也就是继承)的方式来实现变化,而不是当问题发生时,再修改已有的代码。
- 当然,在现实开发中,只通过继承的方式来升级、维护原有系统只是一个理想化的愿景,在实际的开发过程中,修改原有代码、扩展代码往往是同时存在的。
也就是说,我们应该尽量让一个实体在不改变自身的源代码的前提下变更自己的行为。
接着上面的图片加载库的例子,它现在只支持内存缓存,当进程关闭后缓存也就丢失了,再次启动时用户还得花流量从服务器端重新下载,因此领导要求再增加一个磁盘缓存,一开始我们写的代码可能是这样的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67// 内存缓存类
public class ImageCache {
LruCache<String, Bitmap> mImageCache;
public void put(String url, Bitmap bitmap) { }
public Bitmap get(String url) { }
}
// 磁盘缓存类
public class DiskCache {
// 为了简单起见临时写个路径,在开发中请避免这种写法。
static String cacheDir = "sdcard/cache/";
// 从缓存中获取图片
public Bitmap get(String url) { }
// 将图片缓存到内存中
public void put(String url, Bitmap bmp) { }
}
// 内存+磁盘缓存类
public class DoubleCache {
ImageCache mMemoryCache = new ImageCache();
DiskCache mDiskCache = new DiskCache();
// 先从内存缓存中获取图片,如果没有,再从SD卡中获取
public Bitmap get(String url) {
Bitmap bitmap = mMemoryCache.get(url);
if (bitmap == null) {
bitmap = mDiskCache.get(url);
}
return bitmap;
}
// 将图片缓存到内存和SD卡中
public void put(String url, Bitmap bmp) {
mMemoryCache.put(url, bmp);
mDiskCache.put(url, bmp);
}
}
// 图片加载类
public class ImageLoader {
// 内存缓存
ImageCache mImageCache = new ImageCache();
// SD卡缓存
DiskCache mDiskCache = new DiskCache();
// 双缓存
DoubleCache mDoubleCache = new DoubleCache() ;
// 使用SD卡缓存
boolean isUseDiskCache = false;
// 使用双缓存
boolean isUseDoubleCache = false;
// 线程池,线程数量为CPU的数量
ExecutorService mExecutorService =
Executors.newFixedThreadPool (Runtime.getRuntime().availableProcessors());
public void displayImage(final String url, final ImageView imageView) {
Bitmap bmp = null;
if (isUseDoubleCache) {
bmp = mDoubleCache.get(url);
} else if (isUseDiskCache) {
bmp = mDiskCache.get(url);
} else {
bmp = mImageCache.get(url);
}
if ( bmp != null ) {
imageView.setImageBitmap(bmp);
}
// 没有缓存,则提交给线程池进行异步下载图片
}
// ...
}
语句解释:
- 上面代码有如下几个缺点:
- 增加新的缓存策略时要修改ImageLoader类,这样很可能会引入Bug。
- 用户无法自定义缓存策略,只能在内存、磁盘、双缓存三者选其一,即可扩展性差,而可扩展性可是框架最重要的特性之一。
- 在displayImage方法中出现过多的if判断。
上面说的那三个缺点都可以通过一个接口来解决,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 定义一个缓存接口,所有缓存策略都实现它
public interface ImageCache {
public Bitmap get(String url);
public void put(String url, Bitmap bmp);
}
public class MemoryCache implements ImageCache { }
public class DiskCache implements ImageCache { }
public class DoubleCache implements ImageCache{ }
public class ImageLoader {
// 默认使用内存缓存
ImageCache mImageCache = new MemoryCache();
// 用户可以动态的修改缓存方案
public void setImageCache(ImageCache cache) {
mImageCache = cache;
}
// 省略其它代码
}
语句解释:
- 本范例就可以在不修改ImageLoader任何代码的基础上,实现各类缓存策略的更换,同时也解决了上面说的三个问题了。
- 本范例虽然仅仅是增加一个接口,但是却玄妙无比,各位客观可要看仔细了。
里氏替换原则
这个原则主要是为了体现面向对象的“继承”特征来提出的。
- 通俗点讲,我们在写代码时,要保证只要父类能出现的地方子类都可以出现,而且替换为子类也不会产生任何错误或异常,使用者可能根本就不需要知道是父类还是子类。
- 因此,为了保证这种透明的无差别的使用,子类不应该随意的重写父类已经定义好的非抽象的方法。
- 因为这些非抽象方法,类似于某种职能或契约,当父类保持这种约定时,子类也应该遵循并保证该特性,而非修改该特性。

依赖倒置原则
传统的依赖关系中,上层调用下层,上层依赖于下层,当下层剧烈变动时上层也要跟着变动。
依赖倒置原则就是一种特定的解耦方式,它可以让上层不依赖于下层的实现:
一般情况下抽象(就把抽象理解成java里的接口)的变化概率很小,基于这个特点,我们可以在上层和下层之间创建一个中间层(即一个接口)。
让高层的模块和下层的模块都依赖于这个中间层,这样一来即使实现细节不断变动,只要抽象不变,高层的模块就不需要变化。
简单的说,就是模块之间不应该直接产生调用关系,在上层和下层模块之间,增加一个接口,让上层和下层分别依赖这个接口编程。
依赖倒置原则的特点:
- 高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。
- 抽象不应该依赖于具体实现,具体实现应该依赖于抽象。
- 对于两个各自拥有自己抽象的模块,模块间的依赖通过抽象发生,它们的实现类之间不发生直接的依赖关系。
换到前面的图片加载的例子中,最初的时候,在ImageLoader中会持有各种类型缓存的强引用,代码为:1
2
3
4
5
6
7
8public class ImageLoader {
// 内存缓存
ImageCache mImageCache = new ImageCache();
// SD卡缓存
DiskCache mDiskCache = new DiskCache();
// 双缓存
DoubleCache mDoubleCache = new DoubleCache() ;
}
语句解释:
- 这就是典型的上层与下层直接通信的场景,二者耦合度太高,当缓存策略发生变化时,不可避免的就得去修改ImageLoader类。
- 所以后来我们在上层和下层之间新增了一个ImageCache接口,通过它来解耦ImageLoader与具体的缓存策略。
接口隔离原则
这个原则的定义是:客户端不应该被迫重写它不使用的方法,说白了就是,让客户端依赖的接口尽可能地小。
- 如果一个接口定义了过多的抽象方法,则意味着它的每一个实现类都要实现这些方法,这就无形中增加了实现类的负担。
- 因此接口定义的要小(即抽象方法少),但是要有限度,对接口细化可以增加灵活性,但是过度细化则会使设计复杂化。
- 接口隔离原则和单一职责原则的关系:
- 共同点:都是尽可能的缩小涉及的范围。
- 不同点:单一原则主要是指封装性,它更偏向对一个类的要求。而接口隔离原则更偏向对一个接口的要求。
在JDK6之前,我们需要写很多工具方法,去关闭那些可关闭的对象(输入/输出流、Cursor),比如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public static void closeInputStream(InputStream input) {
if (input != null) {
try {
input.close();
} catch (IOException e) { }
}
}
public static void closeOutputStream(OutputStream output) {
if (output != null) {
try {
output.close();
} catch (IOException e) { }
}
}
语句解释:
- 上面这段代码重复代码太多,严重影响代码的可读性。
其实Java中有一个Closeable接口,它只有一个close方法,但拥有100多个子类,各种流都是它的子类,所以可以改为:1
2
3
4
5
6
7
8
9public static void closeQuietly(Closeable closeable) {
if (null != closeable) {
try {
closeable.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
语句解释:
- 这个方法基本原理就是依赖于Closeable抽象而不是具体实现,即依赖倒置原则。
- 并且建立在最小化依赖原则的基础,它只需要知道这个对象是可关闭,其他的一概不关心,也就是这里的接口隔离原则。
以上五条原则就是著名的SOLID(单一功能、开闭原则、里氏替换、接口隔离以及依赖倒置)原则。
最少知识原则
这个原则有如下特点:
- 每个单元对于其他的单元只能拥有有限的知识,只是与当前单元紧密联系的单元。
- 每个单元只能和它的朋友交谈,不能和陌生单元交谈。
- 只和自己直接的朋友交谈。
下面我们就以租房为例来讲讲最少知道原则,我们设定的情境为:我只要求房间的面积和租金,其他的一概不管,中介将符合我要求的房子提供给我就可以。一开始我们可能写出这样的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44// 房间
public class Room {
public float area;
public float price;
public Room(float area, float price) {
this.area = area;
this.price = price;
}
}
// 中介
public class Mediator {
List<Room> mRooms = new ArrayList<Room>();
public Mediator() {
for (inti = 0; i < 5; i++) {
mRooms.add(new Room(14 + i, (14 + i) * 150));
}
}
public List<Room>getAllRooms() {
return mRooms;
}
}
// 租户
public class Tenant {
public float roomArea;
public float roomPrice;
public static final float diffPrice = 100.0001f;
public static final float diffArea = 0.00001f;
public void rentRoom(Mediator mediator) {
List<Room>rooms = mediator.getAllRooms();
for (Room room : rooms) {
if (isSuitable(room)) {
System.out.println("租到房间啦! " + room);
break;
}
}
}
private boolean isSuitable(Room room) {
return Math.abs(room.price - roomPrice) < diffPrice
&&Math.abs(room.area - roomArea) < diffArea;
}
}
语句解释:
- 从上面的代码中可以看到,Tenant不仅依赖了Mediator类,还需要频繁地与Room类打交道。
- 租户想通过中介找到一间适合自己的房间,上面代码中,中介把n个房屋的信息给了租户,然后让租户自己去匹配房屋,这尼玛逗爹呢。
- 此时中介类的功能被弱化了,导致Tenant与Room的耦合较高,因为Tenant必须知道许多关于Room的细节。
既然是耦合太严重,那就需要解耦了,首先要明确地是“我们只和我们的朋友通信”,这里就是指Mediator对象。必须将Room相关的操作从Tenant中移除,而这些操作案例应该属于Mediator,我们进行如下重构:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// 中介
public class Mediator {
List<Room> mRooms = new ArrayList<Room>();
public Mediator() {
for (inti = 0; i < 5; i++) {
mRooms.add(new Room(14 + i, (14 + i) * 150));
}
}
public Room rentOut(float area, float price) {
for (Room room : mRooms) {
if (isSuitable(area, price, room)) {
return room;
}
}
return null;
}
private boolean isSuitable(float area, float price, Room room) {
return Math.abs(room.price - price) < Tenant.diffPrice
&& Math.abs(room.area - area) < Tenant.diffPrice;
}
}
// 租户
public class Tenant {
public float roomArea;
public float roomPrice;
public static final float diffPrice = 100.0001f;
public static final float diffArea = 0.00001f;
public void rentRoom(Mediator mediator) {
System.out.println("租到房啦 " + mediator.rentOut(roomArea, roomPrice));
}
}
语句解释:
- 现在租户并不需要知道太多关于Room的细节,比如与房东签合同、维修等,所有的事情租户直接与中介沟通就好了,房东、维修师傅等这些角色并不是我们直接的“朋友”。
- “只与直接的朋友通信”这简单的几个字就能够将我们从乱七八糟的关系网中抽离出来,使我们的耦合度更低、稳定性更好。
很多面向对象程序设计语言用“.”来调用对象的属性和方法(比如Java),基于此我们可以得出如下结论:
- 最小知道原则可以理解为“只使用一个.算符”,比如a.b.Method()违反了此定律,而a.Method()不违反此定律。
- 一个简单例子是,人可以命令一条狗行走(walk),但是不应该直接指挥狗的腿行走,应该由狗去指挥控制它的腿如何行走。
- 它与单一职责的区别在于,单一职责是对类的定义提出要求,而它是对在何处使用这个类的对象提出要求。
小结
最后我们来总结一下六大原则的特点:
- 单一职责:每个类只做一件事,同时就这个类而言,应该仅有一个引起它变化的原因。
- 开闭原则:对扩展开放,对于修改封闭,这意味着一个实体是允许在不改变它的源代码的前提下变更它的行为。
- 里氏替换:保证只要父类能出现的地方子类都可以出现,而且替换为子类也不会产生任何错误或异常。
- 依赖倒置:模块之间不应该直接产生调用关系,应该通过增加一个中间层(即接口)来解耦。
- 接口隔离:多个小的接口要好于一个宽泛用途的接口。
- 最少知道:人可以命令一条狗行走,但是不应该直接指挥狗的腿行走。
等各位学到了后面章节里介绍的设计模式时,就会发现其中不少模式都借鉴了这六大原则,所以想学会、学懂设计模式,必须要彻底搞懂六大原则。
本节参考阅读:
模式概述
发展历史
建筑师克里斯托佛·亚历山大在1977/79年编制了一本汇集设计模式的书,但是这种设计模式的思想在建筑设计领域里的影响远没有后来在软件开发领域里传播的广泛。
肯特·贝克和沃德·坎宁安在1987年,利用克里斯托佛·亚历山大在建筑设计领域里的思想开发了设计模式并把此思想应用在Smalltalk中的图形用户接口(GUI)的生成中。
一年后埃里希·伽玛在他的苏黎世大学博士毕业论文中开始尝试把这种思想改写为适用于软件开发。Erich Gamma 得到了博士学位后去了美国,在那与Richard Helm, Ralph Johnson ,John Vlissides 合作出版了《设计模式:可复用面向对象软件的基础》(Design Patterns - Elements of Reusable Object-Oriented Software) 一书,在此书中共收录了23个设计模式。
这四位作者在软件开发领域里以“四人帮”(英语,Gang of Four,简称GoF)而闻名,并且他们在此书中的协作导致了软件设计模式的突破。有时,GoF也会用于代指《设计模式》这本书。
类型划分
《设计模式》一书把23种设计模式分为“创建型模式”、“结构型模式”、“行为型模式”三大类。
创建型模式:
- 我们知道在Java中使用new关键字就可以创建一个对象,但是可不要小瞧对象创建这件事,它有很多大学问。
- 创建型设计模式就是用来解决对象创建时遇到的各类问题的,让对象以适应工作环境的方式被创建。
- 属于创建模式的是:单例、建造者(Builder)、原型、工厂方法、抽象工厂。
结构型模式:
- 结构型设计模式是从程序的结构上解决模块之间的耦合问题,该模式有助于在系统的某一部分发生改变的时候,整个系统结构不需要改变。
- 属于结构模式的是:
- 桥接、组合、修饰、外观、享元、代理。
行为型模式:
- 行为型设计模式用来识别对象之间的常用交流模式并加以实现,可在进行这些交流活动时增强弹性。
- 属于行为模式的是:
- 责任连、命令、解释器、迭代器、中介者、备忘录、观察者、状态、策略、模板方法、访问者。
限于篇幅原因,本文只会介绍笔者认为的、开发中常用的模式,未介绍的请您自行搜索学习。
本节参考阅读:
创建型模式
单例模式
所谓的单例(Singleton)设计模式,就是指一个类只允许有一个对象。如果我们的某个类不需要存在多个对象,那么就可以考虑把这个类写成单例模式的。
单例设计模式的实施步骤:
1、使用private修饰构造方法,这样外界就不可以通过new关键字来创建该类的对象了,但本类中的代码仍然可以创建。
2、在本类中建立一个静态的本类的对象。
3、建立一个静态方法用来返回此对象的引用。
范例1:最简单的单例模式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class SingleClass {
private static SingleClass instance = new SingleClass();
private SingleClass() {
// 默认提供的构造方法是public的,因此在此需要自定义一个无参的构造。
// 将访问权限该为private的。
}
public static SingleClass getInstance() {
return instance;
}
// 定义一个实例方法,以供外界调用。
public void getInfo() {
System.out.println("single");
}
}
上面就是一个最简单的单例模式的写法,不过它并不是最优的写法,后面我们会继续完善它。
当程序运行的时候,我们可以通过下面的代码来调用SingleClass类的getInfo方法:1
2// 不需要创建任何SingleClass类的对象,就可以在程序的任何地方调用getInfo()方法。
SingleClass.getInstance().getInfo();
单例与静态的抉择
在设计程序经常有这种需求,某个类里的方法能够全局访问,在这种情况下有两种实现方案:
- 单例模式(Singleton)
- 静态方法
但是,我们应该如何选择使用哪种方式呢?
- 如果你的类不维持任何状态,仅仅是提供全局的访问,这个时候就适合用静态类,比如java.lang.Math类的实现方式,Math类就是用过静态方法来实现的,而不是单例来实现的。
- 如果你的类需要维持一些状态,或者需要从线程安全、兼容性上来考虑一些问题,那么选用单例为宜。
单例的各种写法
上面的范例的写法有个缺点,当SingleClass类被加载的时候就会立刻实例化单例对象。
这意味着如果单例对象里包含了很多属性,那这个对象就会占有很多内存空间,而这块空间我们一时半会可能用不到。因此可以改造一下代码,只有在我们需要使用单例对象的时候才去创建这个单例对象。
范例1:懒汉式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class SingleClass {
private static SingleClass instance;
private SingleClass() { }
public static SingleClass getInstance() {
if(instance == null){
instance = new SingleClass();
}
return instance;
}
// 定义一个实例方法,以供外界调用。
public void getInfo() {
System.out.println("single");
}
}
不过懒汉式的写法依然存在问题,当多个线程同时访问getInstance方法时,会导致创建多个SingleClass类的对象,每个线程操作不同的单例对象,会导致数据错乱。
范例2:懒汉式(线程安全)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class SingleClass {
private static SingleClass instance;
private SingleClass() { }
public static SingleClass getInstance() {
if(instance == null){
// 此处加个线程同步。
synchronized (SingleClass.class) {
if(instance == null){
instance = new SingleClass();
}
}
}
return instance;
}
// 定义一个实例方法,以供外界调用。
public void getInfo() {
System.out.println("single");
}
}
语句解释:
- 此种方式也被称为双重校验锁。
- 也有人将synchronized关键字直接修饰在getInstance()方法上,缺点是每次调用getInstance()方法都需要进行线程同步操作。
范例3:静态内部类。1
2
3
4
5
6
7
8
9public class SingleClass {
private static class SingletonHolder {
private static final SingleClass INSTANCE = new SingleClass ();
}
private SingleClass(){}
public static final SingleClass getInstance() {
return SingletonHolder.INSTANCE;
}
}
语句解释:
- 此种方式利用了静态内部类的特点,即实现了懒加载又不用担心多线程问题。
- 但是由于双重校验锁更直观容易理解,因而比此种方式常见。
有三个问题需要注意:
1、如果单例由不同的类装载器装入,那便有可能存在多个单例类的实例。
2、如果Singleton实现了java.io.Serializable接口,那么这个类的实例就可能被序列化和复原。不管怎样,如果你序列化一个单例类的对象,接下来复原多个那个对象,那你就会有多个单例类的实例。
3、如果你在Manifest中配置某个组件单独运行在新进程中,那么主进程和子进程中会各有一份单例对象。
范例4:通过反序列化来创建多个对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32import java.io.*;
public class Main {
public static void main(String[] args) throws Exception {
// 先输出两遍单例对象,结果它们输出的内存地址是一样的。
System.out.println(SingleClass.getInstance());
System.out.println(SingleClass.getInstance());
File file = new File("a.txt");
// 将单例对象序列化到a.txt文件中。
write(file);
// 反序列化4次,程序每次输出的内存地址都是不一样的。
System.out.println(read(file));
System.out.println(read(file));
System.out.println(read(file));
System.out.println(read(file));
}
private static void write(File file) throws Exception {
ObjectOutputStream output = new ObjectOutputStream(new FileOutputStream(file));
output.writeObject(SingleClass.getInstance());
output.close();
}
private static SingleClass read(File file) throws Exception{
ObjectInputStream input = new ObjectInputStream(new FileInputStream(file));
SingleClass inst = (SingleClass)input.readObject();
input.close();
return inst;
}
}
语句解释:
- 在执行本范例之前,请先让SingleClass实现Serializable接口。
解决方案请自行搜索,不过笔者认为,开发的时候使用“双重校验锁”方式就够用的了。
另外,如果你担心别人通过反射的方式来调用你的私有构造器,那么可以在里面加上检测,一旦存在了单例对象,则直接抛出异常。
参考阅读:
建造者模式
问题描述
假设我们有一个Person类,类中有id、age、sex、name四个必须的属性,并且还会有若干个可选的属性(比如address、phone等)。
对于这样的类,它的构造方法通常我们会这么写:1
2
3
4
5
6
7
8
9
10
11
12
13public class Person {
private int id;
private int age;
private String sex;
private String name;
public Person(int id, int age, String sex, String name) {
this.id = id;
this.age = age;
this.sex = sex;
this.name = name;
}
// 此处省略若干get、set方法。
}
语句解释:
- 猛地一看没有任何问题,但是当Person类不断的增加字段时,你可能需要重载多个构造方法,客户端的代码就会变得很难编写以及阅读。
- 如果客户端不小心颠倒了其中两个同类型参数的顺序,编译也不会报错,但运行的时候会出现错误的行为。
此问题可以通过在Person类中get、set方法来解决,同时客户端的代码读起来也很舒服:1
2
3
4
5Person p = new Person();
p.setId(1);
p.setAge(30);
p.setName("Tome");
p.setSex("M");
遗憾的是,上面的代码有着很严重的缺点,因为构造过程被分到几个调用过程中,在构造过程中JavaBean可能处于不一致状态(需要线程同步安全)。
不过还有另一种替代方法,既能保证构造方法那样的安全性,也能保证JavaBean模式的可读性,这就是建造者(Builder)模式。
模式介绍
Build模式在Android开发中也比较常用,通常作为配置类的构建器将配置的构建和表示分离开来,同时也是将配置从目标类中隔离出来。
咱们还是以ImageLoader库为例,实际开发中还会有更多的需求,比如设置图片在加载时ImageView显示的图片,加载失败时显示的图片,加载时最大使用的线程数等。
通常情况下,新手写出来的代码可能是这样的:1
2
3
4
5
6
7
8
9public class ImageLoader {
// 正在加载和加载失败的图片
int mLoadingImageId;
int mLoadingFailedImageId;
// 此处省略上面两个属性的get、set方法。
// 省略其它代码
}
语句解释:
- 直接在ImageLoader增加字段有好几个缺点:
- 随着配置项不断增加,ImageLoader类中的代码和get、set也会越来越多,有违单一职责原则。
- 用户的使用成本变大,方法增多,每次使用的时候都需要仔细选择。
- 新增的这些配置可以实时修改,那么当用户修改最大允许线程数时,岂不是得关掉之前的线程池,然后重新新开一个?那如果新开一个,是不是还得考虑把老池中的未执行任务转移到新池中?
- 针对这个场景最好的做法就是专门分配一个类去管理这些配置项,同时只允许ImageLoader在初始化的时候修改这些配置,初始化之后则不能再改。
下面是使用Builder模式之后的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public class ImageLoaderConfig {
// 正在加载和加载失败的图片
int mLoadingImageId;
int mLoadingFailedImageId;
// 私有化构造器,本类的对象只能通过Builder类创建。
private ImageLoaderConfig(){}
// 静态内部类,Builder模式
public static class Builder{
int mLoadingImageId;
int mLoadingFailedImageId;
public Builder setLoadingImageId(int id){
this.mLoadingImageId = id;
return this;
}
public Builder setLoadingFailedImageId(int id){
this.mLoadingFailedImageId = id;
return this;
}
public ImageLoaderConfig build(){
ImageLoaderConfig config = new ImageLoaderConfig();
config.mLoadingImageId = this.mLoadingImageId;
config.mLoadingFailedImageId = this.mLoadingFailedImageId;
return config;
}
}
}
public class ImageLoader {
private ImageLoaderConfig mConfig;
public void init(ImageLoaderConfig config){
this.mConfig = config;
}
// ……
}
此时客户端的代码为:1
2
3
4
5
6private void initImageLoader(){
ImageLoaderConfig config = new ImageLoaderConfig.Builder()
.setLoadingImageId(R.drawable.loading)
.setLoadingFailedImageId(R.drawable.not_found).builder();
ImageLoader.getInstance().init(config)
}
简而言之,如果类的构造器中有多个参数,设计这种类时,Builder模式就是种不错的选择,特别的是当大多数参数都是可选的时候。
提示:Android中的AlertDialog、NotificationCompat等类都是使用了Builder模式。
本节参考阅读:
原型模式
原型模式(Prototype)是创建型模式的一种,其特点在于通过“复制”一个已经存在的实例来返回新的实例,而不是新建实例,被复制的实例就是我们所称的“原型”。
应用场景:
1、创建复杂的或者耗时的实例。因为这种情况下,复制一个已经存在的实例使程序运行更高效。
2、你的对象需要提供给他人访问,为了防止访问者修改你的对象,可以复制出一个新的对象交给外界访问,即保护型拷贝。
原型模式在Java中可以很容易的实现,就是利用Cloneable接口即可,假设我们有如下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public class Person implements Cloneable {
private int age;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Person [age=" + age + ", name=" + name + "]";
}
// 注意,默认情况下clone方法是protected,为了让外界可以访问,需要将其改为public的。
public Person clone() throws CloneNotSupportedException {
return (Person) super.clone();
}
}
// 客户端代码
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
Person p1 = new Person(12, "Tom");
Person p2 = p1.clone();
System.out.println(p1); //输出 Person [age=12, name=Tom]
System.out.println(p2); //输出 Person [age=12, name=Tom]
p2.setAge(30);
System.out.println(p1); //输出 Person [age=12, name=Tom]
System.out.println(p2); //输出 Person [age=30, name=Tom]
}
}
语句解释:
- 首先要知道的是,Cloneable接口中没有任何方法,它只是起到一个标识作用,某个类实现了此接口就相当于告诉系统它启用了clone功能,其实clone方法是在Object定义的,对于未实现Cloneable接口的类来说,调用clone方法会抛异常。
上面的代码表面上看一切正常,但其实有一个隐藏的问题,现在我们给Person加一个属性:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class Person implements Cloneable {
private int age;
private String name;
private ArrayList<String> images;
public Person(int age, String name) {
this.age = age;
this.name = name;
this.images = new ArrayList<String>();
}
public String toString() {
return "Person [age=" + age + ", name=" + name + ", images=" + images + "]";
}
public void addImage(String img) {
this.images.add(img);
}
public Person clone() throws CloneNotSupportedException {
return (Person) super.clone();
}
}
// 客户端代码
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
Person p1 = new Person(12, "Tom");
Person p2 = p1.clone();
System.out.println(p1); //输出 Person [age=12, name=Tom, images=[]]
System.out.println(p2); //输出 Person [age=12, name=Tom, images=[]]
p2.addImage("c.jpg");
System.out.println(p1); //输出 Person [age=12, name=Tom, images=[c.jpg]]
System.out.println(p2); //输出 Person [age=12, name=Tom, images=[c.jpg]]
}
}
语句解释:
- 从代码中可以发现,我们往p2中加的字符串也出现在了p1中,原因是clone方法默认是进行“浅复制”,即只会复制属性的值。
解决的方法也很简单,修改一下clone方法即可:1
2
3
4
5
6
7public Person clone() throws CloneNotSupportedException {
// 先调用Object类的clone方法,复制当前对象。
Person p = (Person) super.clone();
// 再调用列表的clone方法。
p.images = (ArrayList<String>) this.images.clone();
return p;
}
语句解释:
- 上面的代码就是在进行深度复制。
本节参考阅读:
工厂模式
工厂模式(Factory)是创建型模式的一种,其特点在于“代理”,即实例化对象时除了创建对象本身外,可能还需要执行其它操作(比如先创建辅助对象、初始化对象属性等),同时这些操作不是一两行代码就能完成的,基于代码重用等原因,我们会把创建对象的任务交给一个工厂,每当需要创建对象时调用工厂即可。
工厂模式根据抽象程度的不同,按照从低到高分为三种:简单工厂模式、工厂方法模式、抽象工厂模式,它们各自都有自己的应用场景,接下来就来依次介绍它们。
简单工厂模式
简单工厂又叫做静态工厂方法(Static Factory Method)模式,但不属于23种GOF设计模式之一,算是工厂方法模式的特殊实现。
假设现在有两辆车(奥迪和宝马),作为司机,如果要开其中一种车比如AodiCar,最直接的做法是直接创建AodiCar对象,并调用其drive方法,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 遵循开闭原则,定义一个Car接口
public interface Car {
public void drive();
}
// 奥迪车
class AodiCar implements Car {
public void drive() {
System.out.println("奥迪开车");
}
}
// 宝马车
class BaomaCar implements Car {
public void drive() {
System.out.println("宝马开车");
}
}
// 客户端代码
public class Driver {
public static void main(String[] args) {
Car car = new AodiCar();
car.drive();
}
}
语句解释:
- 这么写代码最大的问题就是,当需要司机想换车或者有新车时,需要修改客户端的代码。
- 以Android为例,客户端其实就是一个APK文件,如果需要修改客户端代码,那就得发布新版本,成本有点大。
为了解决这个问题,我们可以新增一个专门用来创建Car对象的类,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class CarFactory {
public static Car getCar() {
Car car = null;
// 从本地配置文件中读取类名。
String name = getCarNameFromFile();
switch (name) {
case "Aodi":
car = new AodiCar();
break;
case "Baoma":
car = new BaomaCar();
break;
default:
car = null;
break;
}
return car;
}
// 读取本地配置文件
private String getCarNameFromFile() { }
}
语句解释:
- 在上面的代码中,当需要换车或新增车时,客户端的代码也不需要改动,只需要修改配置文件就行。
还可以通过反射技术来进一步优化:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// 汽车工厂
public class CarFactory {
public static Car getCar() {
Car car = null;
// 从本地配置文件中读取类名,然后通过反射的方式动态实例化出对应的Car。
String name = getCarNameFromFile();
try {
car = (Car) Class.forName(name).newInstance();
} catch (InstantiationException | IllegalAccessException | ClassNotFoundException e) { }
return car;
}
// 读取本地配置文件
private String getCarNameFromFile() { }
}
// 客户端代码
public class Driver {
public static void main(String[] args) {
CarFactory.getCar().drive();
}
}
语句解释:
- 这样一来,如果只是换车的话,不需要修改任何代码,只修改配置文件就行。
上面写的代码就是运用了简单工厂模式,也就是说:
如果对于一个任务,你提供了多种解决方案供客户端选择,那么最好不要让客户端直接去实例化这些方案的对象。应该在客户端和解决方案之间增加一个中间层(工厂类),比如上面就是通过简单工厂模式来让客户端与具体业务解耦。
简单工厂模式角色划分:
- 工厂角色(CarFactory类),由它负责创建所有的类的内部逻辑,一般而言其内部会提供一个静态方法,外部程序通过该方法创建所需对象。
- 抽象产品角色(Car类),简单工厂模式所创建的是所有对象的父类,它可以是接口也可以是抽象类,它负责描述所创建实例共有的公共接口。
- 具体产品角色(AodiCar、BaomaCar类),简单工厂所创建的具体实例对象。
简单工厂模式缺点:
由于工厂类集中了所有实例的创建逻辑,这就直接导致一旦这个工厂出了问题,所有的客户端都会受到牵连。
由于简单工厂模式的产品是基于一个共同的抽象类或者接口,这样一来,产品的种类增加的时候(比如新增了飞机类),工厂类就需要判断何时创建何种接口的产品,这就和创建何种种类的产品相互混淆在了一起,违背了单一职责原则,导致系统丧失灵活性和可维护性。
工厂方法模式
要说明工厂方法模式的优点,可能没有比组装汽车更合适的例子了。场景是这样的:汽车由发动机、轮、底盘组成,现在需要组装一辆车交给调用者。假如不使用工厂模式,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Engine {
public void getStyle(){
System.out.println("这是汽车的发动机");
}
}
class Underpan {
public void getStyle(){
System.out.println("这是汽车的底盘");
}
}
class Wheel {
public void getStyle(){
System.out.println("这是汽车的轮胎");
}
}
public class Client {
public static void main(String[] args) {
Engine engine = new Engine();
Underpan underpan = new Underpan();
Wheel wheel = new Wheel();
ICar car = new Car(underpan, wheel, engine);
car.show();
}
}
语句解释:
- 可以看到,调用者为了组装汽车还需要另外实例化发动机、底盘和轮胎,而这些汽车的组件是与调用者无关的,严重违反了最少知道法则,耦合度太高,非常不利于扩展。
- 另外,本例中发动机、底盘和轮胎还是比较具体的,在实际应用中,可能这些产品的组件也都是抽象的,调用者根本不知道怎样组装产品。
假如使用工厂方法的话,整个架构就显得清晰了许多:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22interface IFactory {
public ICar createCar();
}
class AudiCar implements ICar {
public void show(){ }
}
class AudiFactory implements IFactory {
public ICar createCar() {
Engine engine = new Engine();
Underpan underpan = new Underpan();
Wheel wheel = new Wheel();
ICar car = new AudiCar(underpan, wheel, engine);
return car;
}
}
public class Client {
public static void main(String[] args) {
IFactory factory = new AudiFactory();
ICar car = factory.createCar();
car.show();
}
}
语句解释:
- 对于工厂方法模式来说,每个类型的工厂只对应一个车型,如果还想生产宝马车,那么就创建一个BMWFactory,这样就遵循了开闭原则,当新增车型时不会影响老代码。
工厂方法模式角色划分:
- 工厂接口(IFactory),工厂接口是工厂方法模式的核心,与调用者直接交互用来提供产品。
- 工厂实现(AudiFactory),决定如何实例化产品,需要有多少种产品,就需要有多少个具体的工厂实现。
- 产品接口(ICar),定义产品的规范,所有的产品实现都必须遵循产品接口定义的规范。
- 产品实现(AudiCar),实现产品接口的具体类,决定了产品在客户端中的具体行为。
工厂方法主要优点有:
1、可以使代码结构清晰,有效地封装变化,使得调用者根本无需关心产品的实例化过程,只需依赖工厂即可得到自己想要的产品。
2、降低耦合度。客户端不需要知道除了Car以外的任何其它类。
抽象工厂模式
在工厂方法模式中,每一个具体工厂对应一种具体产品,一般情况下,一个具体工厂中只有一个工厂方法。但是有时候我们需要一个工厂可以提供多个产品对象,而不是单一的产品对象。
比如我们想要一个工厂,让它不仅能创建汽车,还能生产手机和pad。
我们来模拟一个场景来说明一下这其中的关系吧。
富士康公司给两个品牌作代工产品:苹果和三星。众所周知,这两个品牌都有手机和平板产品,由于生产工艺的不同,富士康开设了两条生产线,一条线只生产手机,另一条线只生产平板。
我们可以使用如下代码来实现:
1 | // 手机和Pad类 |
语句解释:
- 这种写法就是抽象工厂模式。
- 优点是分离接口与实现,客户端使用抽象工厂来创建对象,而客户端根本就不知道具体的实现是谁,客户端只是面向接口编程而已。
- 缺点是类文件的爆炸性增长,同时当新增加产品类时(比如增加笔记本电脑类)需要修改抽象工厂,从而导致所有具体的工厂均会被修改。
- 抽象工厂模式在Android开发中使用的并不多,主要是因为开发中很少出现多个产品种类的情况,大部分情况使用另外两种工厂模式即可解决问题。
总结一下:
简单工厂模式:一个工厂类,工厂里依据参数来创建不同的对象,抽象的是对象。
工厂方法模式:多个工厂类,每个工厂里只创建一个对象,抽象的是工厂。
抽象工厂模式:多个工厂类,每个工厂内提供多个创建对象方法,各个方法创建不同的对象,抽象的是工厂。
三种工厂模式在形式和特点上是极为相似的,它们最终目的都是为了解耦,在使用时我们不必去在意这个模式到底工厂方法模式还是抽象工厂模式,因为他们之间的演变常常是令人琢磨不透的。经常你会发现,明明使用的工厂方法模式,当新需求来临,稍加修改,加入了一个新方法后,由于类中的产品构成了不同等级结构中的产品族,它就变成抽象工厂模式了;而对于抽象工厂模式,当减少一个方法使的提供的产品不再构成产品族之后,它就演变成了工厂方法模式。
本节参考阅读:
行为型模式
策略模式
模式介绍
在软件开发中也常常遇到这样的情况:
实现某一个功能可以有多种算法或策略,我们根据实际情况选择不同的算法或者策略来完成任务。例如,排序算法,可以使用插入排序、归并排序、冒泡排序等。
针对这种情况,一种常规的方法是将多种算法写在一个工具类中,每个方法对应一个算法,这种方式我们可以称为硬编码。然后当很多个算法集中在一个类中时,这个类就会变得很臃肿,维护成本变高,也容易引发错误,同时当需要新增一种排序算法时,需要修改那个工具类的源代码,违反了我们之前说的单一职责和开闭原则。
如果将这些算法或者策略抽象出来,提供一个统一的接口,不同的算法或策略有不同的实现类,这样在程序客户端就可以通过注入不同的实现对象来实现算法或者策略的动态替换,这种模式的可扩展性、可维护性也就更高,也就是我们本节要说的策略模式。
UML类图
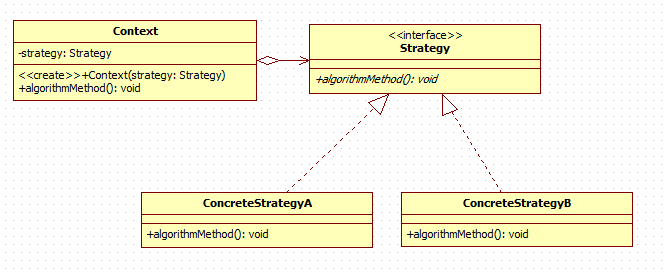
角色介绍:
- Context:用来操作策略的上下文环境。
- Stragety:策略的抽象。
- ConcreteStragetyA、ConcreteStragetyB:具体的策略实现。
应用范例
这里以简单的计算操作(+、-、*、/)作为示例,如果不使用策略模式,写出的代码通常是这样的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public static double calc(String op, double paramA, double paramB) {
if ("+".equals(op)) {
System.out.println("执行加法...");
return paramA + paramB;
} else if ("-".equals(op)) {
System.out.println("执行减法...");
return paramA - paramB;
} else if ("*".equals(op)) {
System.out.println("执行乘法...");
return paramA * paramB;
} else if ("/".equals(op)) {
System.out.println("执行除法...");
if (paramB == 0) {
throw new IllegalArgumentException("除数不能为0!");
}
return paramA / paramB;
} else {
throw new IllegalArgumentException("未找到计算方法!");
}
}
使用策略模式,则是:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62//针对操作进行抽象
public interface Strategy {
public double calc(double paramA, double paramB);
}
//加法的具体实现策略
public class AddStrategy implements Strategy {
public double calc(double paramA, double paramB) {
return paramA + paramB;
}
}
//减法的具体实现策略
public class SubStrategy implements Strategy {
public double calc(double paramA, double paramB) {
return paramA - paramB;
}
}
//乘法的具体实现策略
public class MultiStrategy implements Strategy {
public double calc(double paramA, double paramB) {
return paramA * paramB;
}
}
//除法的具体实现策略
public class DivStrategy implements Strategy {
public double calc(double paramA, double paramB) {
if (paramB == 0) {
throw new IllegalArgumentException("除数不能为0!");
}
return paramA / paramB;
}
}
//上下文环境的实现
public class Calc {
private Strategy strategy;
public void setStrategy(Strategy strategy) {
this.strategy = strategy;
}
public double calc(double paramA, double paramB) {
if (this.strategy == null) {
throw new IllegalStateException("你还没有设置计算的策略");
}
return this.strategy.calc(paramA, paramB);
}
}
//执行方法
public static double calc(Strategy strategy, double paramA, double paramB) {
Calc calc = new Calc();
calc.setStrategy(strategy);
return calc.calc(paramA, paramB);
}
语句解释:
- 上面的代码看起来是不是很熟悉,其实咱们一开始说ImageLoader的缓存模块就是使用了策略模式。
- 策略模式中的Context类其实就对应ImageLoader类,它们都有setXxxx方法。
- 举一反三的话,还可以举一个范例,比如我们出行时可以乘坐地铁或者打的,我们需要依据用户输出的距离长度,计算出这两种方式的金额,这个问题就比四则运算要复杂一些。
总结
策略模式的优缺点:
- 优点:结构清晰, 消除了一些if else条件语句,耦合度相对于if-else判断来说要低,数据的封装也更为彻底,数据更安全,完美诠释开闭原则。
- 缺点是随着策略的增加,子类会变多(这都不是事),客户端必须知道所有的策略类,并自行决定使用哪一个策略类。
状态模式
模式介绍
状态模式中的行为是由状态来决定的,不同的状态下有不同的行为。状态模式和策略模式的结构几乎完全一样,但它们的目的、本质却完全不一样。状态模式的行为是平行的、不可替换的,策略模式的行为是彼此独立、可相互替换的。用一句话来表述,状态模式把对象的行为包装在不同的状态对象里,每一个状态对象都有一个共同抽象状态基类。状态模式的意图是让一个对象在其内部状态改变的时候,其行为也随之改变。
UML类图
与策略模式一样,略。
应用范例
下面我们就以电视遥控器为例来演示一下状态模式的实现。我们首先将电视的状态简单分为开机和关机两个状态,且只有在开机状态下才可以进行频道切换、调整音量等操作,我们看看第一版的代码实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
public class TvController {
private final static int POWER_ON = 1;
private final static int POWER_OFF = 2;
private int mState = POWER_OFF;
public void powerOn() {
if (mState == POWER_OFF) {
System.out.println("开机啦");
}
mState = POWER_ON;
}
public void powerOff() {
if (mState == POWER_ON) {
System.out.println("关机啦");
}
mState = POWER_OFF;
}
public void nextChannel() {
if (mState == POWER_ON) {
System.out.println("下一频道");
} else {
System.out.println("没有开机");
}
}
public void prevChannel() {
if (mState == POWER_ON) {
System.out.println("上一频道");
} else {
System.out.println("没有开机");
}
}
public void turnUp() {
if (mState == POWER_ON) {
System.out.println("调高音量");
} else {
System.out.println("没有开机");
}
}
public void turnDown() {
if (mState == POWER_ON) {
System.out.println("调低音量");
} else {
System.out.println("没有开机");
}
}
}
语句解释:
- 本范例通过mState字段来存储电视的状态,每个功能中都需要使用if-else,代码重复、相对较为混乱,这还只是有2个状态的情况下,当有5个状态就能乱了。
状态模式就是为了解决这类问题而出现的,我们将这些状态用对象来代替,将这些行为封装到对象中,使得在不同的状态下有不同的实现,这样就将这些if-else从TvController类中去掉,整个结构也变的清晰起来。我们来看看实现代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54public interface TvState {
void nextChannel();
void prevChannel();
void turnUp();
void turnDown();
}
public class PowerOffState implements TvState {
public void nextChannel() {
}
public void prevChannel() {
}
public void turnUp() {
}
public void turnDown() {
}
}
public class PowerOnState implements TvState {
public void nextChannel() {
System.out.println("下一频道");
}
public void prevChannel() {
System.out.println("上一频道");
}
public void turnUp() {
System.out.println("调高音量");
}
public void turnDown() {
System.out.println("调低音量");
}
}
语句解释:
- 状态模式将这些行为封装到状态类中,在进行操作时将这些功能转发给状态对象,不同的状态有不同 的实现,这样就通过多态的形式去除了重复、杂乱的if-else语句,这也正式状态模式的精髓所在。
总结
状态模式的优缺点:
- 优点:将所有与一个特定的状态相关的行为都放入一个状态对象中,它提供了一个更好的方法来组织与特定状态相关的代码,将繁琐的状态转换成结构清晰的状态类族,在避免代码膨胀的同时也保证了可扩展性与可维护性。
- 缺点:状态模式的使用必然会增加类和对象的个数。
状态模式和策略模式:
- 策略模式的每一个策略相互独立,相互替换,策略的个数可以是无限的。
- 状态模式描述某个对象的所有状态,对象某一时间只能处于一种状态,对象可以在有限的几个状态之间切换,但状态切换时并不是任意的两个状态之间都可以100%切换的,比如人有吃饭、拉屎、睡觉、死亡、跑步几个状态,显然正常情况下死亡状态不能直接切换到吃饭、拉屎等状态。
- 策略模式服务于算法族,而状态模式服务于某个对象。
责任链模式
模式介绍
责任链模式(Chain of Responsibility)中维护了一个链表,链表里的每个元素都是一个可以处理特定事件的对象,当某个事件发生时,会从表头元素开始检测是否能处理该事件,若能则处理,若不能则将事件传递给下一个节点,以此类推,直到有对象处理这个请求为止。
UML类图
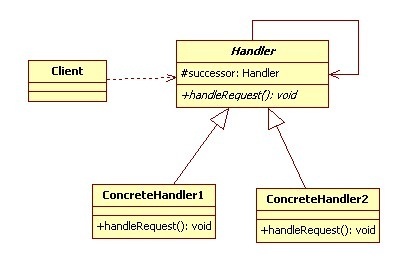
角色介绍:
- Handler:抽象处理者角色,声明一个处理请求的方法,并在其中持有下一个Handler对象的引用。
- ConcreteHandler:具体的处理者角色,对请求进行处理,如果不能处理则将该请求转发给下一个Handler。
- Client:使用责任链模式的客户端。
应用范例
张三代表公司出国培训,来回一趟花了5万元,回来上班第一天就向组长申请报销费用,组长一看是笔不小的数目,他没有权限审批,于是组长又去找部门主管,主管一看要报这么多钱,自己的权限内只能批五千,于是主管又去找经理,经理一看二话不说直接拿着票据奔向了老板的办公室,因为他的权限也只是一万。
我们来用代码来模拟一下这个过程,第一版本的代码可能是这样的:
1 | float money = 50000; |
语句解释:
- 这么写虽然很容易理解,但是有如下两个问题:
- 代码臃肿:实际应用中的判定条件通常不是这么简单地判断是否为1或者是否为2,也许需要复杂的计算,也许需要查询数据库等等,这就会有很多额外的代码,如果判断条件再比较多,那么这个if…else…语句基本上就没法看了。
- 耦合度高:如果我们想继续添加处理请求的类,那么就要继续添加else if判定条件;另外,这个条件判定的顺序也是写死的,如果想改变顺序,那么也只能修改这个条件语句。
既然缺点我们已经清楚了,就要想办法来解决。这个场景的业务逻辑很简单:如果满足条件1,则由Handler1来处理,不满足则向下传递;如果满足条件2,则由Handler2来处理,不满足则继续向下传递,以此类推,直到条件结束。其实改进的方法也很简单,就是把判定条件的部分放到处理类中,这就是责任连模式的原理。
1 | //首先是Handler的定义 |
语句解释:
- 可以看到此时Client不会依赖具体的业务类(GroupLeader、Boss等)。
总结
责任链模式优缺点:
- 优点:消除某类if-else语句,让请求者和处理者解耦,满足开闭原则(新增一个leader不会影响client)。
- 缺点:链表元素比较多时,处理请求会很耗时,因为对于每个请求都需要遍历链表中的每一个元素,直到请求被处理。
其它介绍:
- 实际使用中,责任链模式分为纯和不纯两种,一个纯的责任链模式要求一个具体的处理者对象只能在两个行为中选择一个:一是处理请求,二是把请求推给下家。不允许出现某一个具体处理者对象在处理了请求后又把请求向下传的情况,而不纯的则可以又处理又推给下家。
- 在实际开发中,责任链模式用的比较少,纯的责任链模式的实际例子很难找到,一般看到的例子均是不纯的责任链模式的实现。
- 在java中switch、try-catch语句都有责任链模式的影子。
- 客户端发送一个请求,有多个对象都有机会来处理这个请求,但客户端不知道究竟谁来处理。此时可以使用责任链模式。
本节参考阅读:
命令模式
模式介绍
命令模式(Command Pattern)的定义为:
将一个请求封装成一个对象,从而让用户使用不同的请求把客户端参数化,对请求排队或者记录请求日志,以及支持可撤销的操作。
假设有一个Document类,它提供了加粗字体和粘贴两个方法,一般情况下可能会这么写代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class Document {
public void bold() {
}
public void paste() {
}
}
public class Cilent {
public static void main(String[] args){
Document document = new Document();
document.bold();
document.paste();
}
}
语句解释:
- 就是直接在客户端中调用具体的方法。这么做有两个问题:
- 违反开闭原则,如果这两个方法的名字发生改变,则需要修改Client类。
- 如果需要增加“撤销”操作,则就无法完成。
接下来我们先来解决第一个问题,按照前面的学习,可以在Client和Document类之间加一个抽象层,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public interface Command {
void execute();
}
public class BoldCommand implements Command {
Document document;
public BoldCommand(Document document) {
this.document = document;
}
public void execute() {
document.bold();
}
}
public class PasteCommand implements Command {
Document document;
public PasteCommand(Document document) {
this.document = document;
}
public void execute() {
document.paste();
}
}
public class Cilent {
public static void main(String[] args){
Document document = new Document();
BoldCommand boldCommand = new BoldCommand(document);
PasteCommand pasteCommand = new PasteCommand(document);
boldCommand.execute();
pasteCommand.execute();
}
}
语句解释:
- 这样一来当底层Document对象的方法名改变时,最多我们会修改PasteCommand和BoldCommand里的代码,而Client则不会变。也就是说,对于客户端来说,他只需要知道系统提供了哪些操作就可以,但是当系统中新增了操作时,还是得修改客户端的。
接着在来让它支持“撤销”操作,既然说道撤销,那么肯定得有个记录机制,我们得把所有执行过的操作都给记录下来,才能在稍后的时候,支持撤销操作。因此我们专门创建一个类来完成此工作:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// 首先每个命令除了执行方法外,还应该有一个撤销方法。相应的PasteCommand和BoldCommand需要重写该方法,此处就省了。
public interface Command {
void execute();
void undo();
}
// 新增一个调用者类,客户端不再直接调用某个命令的execute方法了,而是通过Invoker来调用
// 这么做是用来统一记录客户端执行了哪些命令,以便后续执行撤销操作。
public class Invoker {
List<Command> commandList = new ArrayList<Command>();
public void execute(Command command) {
commandList.add(command);
command.execute();
}
public void undo() {
if(canUndo()){
Command command = commandList.get(commandList.size()-1);
commandList.remove(command);
command.undo();
}
}
public boolean canUndo() {
return commandList.size() > 0;
}
}
语句解释:
- 至此我们就完成了需求,同时这个代码就是传说中的命令模式。
UML类图
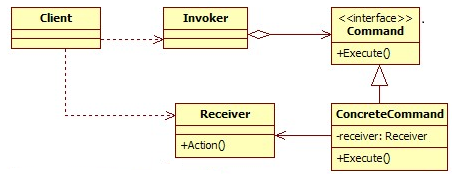
角色介绍:
- Invoke:维护一个命令列表,用于执行撤销等操作。
- Command:命令角色。
- ConcreteCommand:具体的命令角色。
- Receiver:最终执行命令的人,也就是Document对象。
- Client:使用责任链模式的客户端。
总结
命令模式优缺点:
- 优点:让客户端和具体业务解耦,从上面我们也可以得知,何时去使用命令模式了,即存在撤销操作时,命令模式是首选。
- 缺点:充分体现了设计模式的通病,就是类的膨胀,大量衍生类的创建,这是不可避免的问题。
本节参考阅读:
观察者模式
模式介绍
观察者模式定义对象间一种一对多的依赖关系,使得每当一个对象改变状态,则所有依赖于它的对象都会接到通知并自动更新。
问题描述
假设我们有一个User对象(包含姓名、签名、性别等)以及A、B、C三个界面,A界面用来显示用户信息,B界面用来编辑信息,C界面用来编辑用户签名,它们三者的跳转关系是A->B->C,很显然当我们在C界面修改了用户签名后,需要同时更新A和B界面的内容。
常见的解决这个问题的方法有如下三种(但不限于):
- 使用广播机制。
- 先在A界面动态注册广播接收者,然后在C界面更新数据后就发送一个广播,A界面接到广播后执行刷新界面。
- 使用文件存储。
- 在C界面中把最新的数据写到本地文件中,当A界面onResume时再从本地读取数据。
- 使用Application对象。
- 首先,程序得自定义一个Application对象。
- 然后,在Application中创建一个Map对象专门保存全局变量,C界面修改完数据后就将数据放入到Map中。
- 最后,当A界面onResume时再从Map中读取数据。
这三种解决方法各有缺点:
- 使用广播机制的缺点:
- 代码混乱,各个界面都得动态注册和销毁接收者,不利于维护。
- 注册和发送广播是系统级别的操作,如果连续开启多个界面,每个界面都动态注册接收者,很占系统资源。
- 使用文件存储的缺点:
- 如果有多个线程同时执行任务时,无法保证文件里保存的内容是最新的。
- 文件存储涉及到IO操作,相比之下要消耗不少资源。
- 使用Application对象的缺点: 如果处理不当,Map中的对象会不断累积,导致内存泄露。
其实,这个问题本质上就是“一对多的问题”(一就是User对象,多就是ABC三个界面),我们可以使用“观察者模式”来解决数据刷新的问题,同时不会存在上面这三种方案带来的弊端。
UML类图
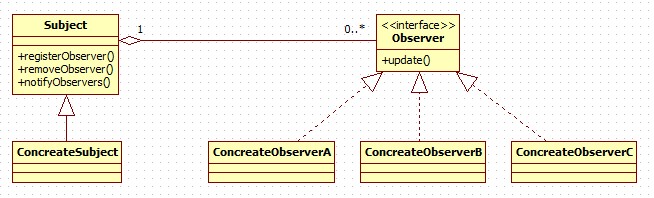
角色介绍:
- Subject:抽象的主题类,也就是被观察(Observable)的对象,其内维护一个被观察的数据(如User对象)以及一个观察者列表,当数据发生变化时,就去通知列表中的所有观察者。
- ConcreteSubject:具体主题,除了继承了Subject的特性外,还依据自身维护的数据的不同(如果User等),而提供不同的操作。
- Observer:抽象的观察者,它定义了一个观察者所应该具备的接口,以便当数据更新时,主题可以通知观察者。
- ConcreteObserver:具体的观察者,当数据发送改变时,每个具体的观察者都会做出不同的处理。
应用范例
假设项目有一个登录功能,当登录成功后会依据服务端返回的数据来创建一个User对象。
需求是:登陆成功后,在项目的任何界面都可以访问和修改该User对象。
范例1:为了实现这个需求,我们先创建一个com.cutler.demo.model.user.User类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class User {
private int id;
private String nickname;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getNickname() {
return nickname;
}
public void setNickname(String nickname) {
this.nickname = nickname;
}
}
语句解释:
- 也是不多说。
然后定义一个观察者接口。
范例2:com.cutler.demo.common.entity.Observer类。1
2
3
4
5
6
7
8
9public interface Observer<T> {
/**
* 当数据被改变时,观察者的此方法会被回调。
* 注意:此方法会在ui线程中被调用。
* @param data 新数据。
*/
public void onDataLoaded(T data);
}
语句解释:
- T是泛型,不懂请自己查去。
接着,再创建一个名为的EntityManager类,用来管理观察者。
范例3:com.cutler.demo.common.entity.EntityManager类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65public class EntityManager<T> {
// 保存所有注册到本Manager中的观察者。
private List<Observer<T>> observers = new ArrayList<Observer<T>>();
// 本类所管理的数据。
private T data;
// 用于将当前流程,从子线程切换到主线程。
private Handler mHandler = new Handler(Looper.getMainLooper());
/**
* 添加一个观察者。
*/
public void addObserver(final Observer<T> observer) {
if(observer == null) {
throw new NullPointerException();
}
// 同步块,防止并发修改observers对象。
synchronized(observers){
observers.remove(observer);
observers.add(observer);
}
}
/**
* 删除一个观察者。
*/
public void removeObserver(Observer<T> observer) {
synchronized(observers) {
observers.remove(observer);
}
}
/**
* 通知Manager中已注册的所有观察者,数据已经更新了。
*/
protected void notifyObservers() {
mHandler.post(new Runnable() {
public void run() {
for (Observer<T> observer : observers) {
observer.onDataLoaded(data);
}
}
});
}
/**
* 返回当前Manager的观察者个数。
*/
public int getObserverCount(){
return observers.size();
}
/**
* @return 返回当前Manager当前管理的数据。
*/
public T getData() {
return data;
}
/**
* @return 設置当前Manager当前管理的数据。
*/
public void setData(T data) {
this.data = data;
}
}
语句解释:
- EntityManager类就是上面说的Subject类。
EntityManager类用来保存共用代码,还需要创建一个单例的类来管理User对象,该类继承自EntityManager类。
范例4:com.cutler.demo.model.user.LoginUserEntityManager类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56public class LoginUserEntityManager extends EntityManager<User> {
/**
* 当用户登录成功后调用此方法,将User对象设置到LoginUserEntityManager中。
* @param user
*/
public void login(User user) {
if (user != null) {
setData(user);
// TODO 如果需要,你可以在这里将User对象持久化到本地文件中。
}
}
/**
* 当用户登出时,调用此方法清除本地缓存。
*/
public void logout() {
setData(null);
// TODO 如果需要,你可以在这里将本地缓存的文件给删除。
}
/**
* 修改用户的昵称。
* @param newName
*/
public void setName(String newName) {
if(getData() != null){
getData().setNickname(newName);
// 通知各个界面进行数据更新。
notifyObservers();
// TODO 如果需要,你可以在这里将User对象持久化到本地文件中。
}
}
// 单例对象
private static LoginUserEntityManager inst;
private LoginUserEntityManager() {
// TODO 如果需要,你可以在这里从本地文件中读取一个User对象。
}
/**
* 返回单例对象
* @return
*/
public static LoginUserEntityManager getInstance() {
if (inst == null) {
synchronized (LoginUserEntityManager.class) {
if (inst == null) {
inst = new LoginUserEntityManager();
}
}
}
return inst;
}
}
语句解释:
- LoginUserEntityManager类就是上面说的ConcreteObserver类。
最后,就可以让Activity实现接口:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class LoginActivity extends Activity implements Observer<User> {
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 添加观察者
LoginUserEntityManager.getInstance().addObserver(this);
}
public void onDataLoaded(User data) {
if(data != null){
// 进行界面数据回填。
System.out.println(data.getNickname());
}
}
protected void onDestroy() {
super.onDestroy();
// 移除观察者
LoginUserEntityManager.getInstance().removeObserver(this);
}
}
语句解释:
- 这样一来,不论开启了几个Activity,只要在其中一个Activity中更新了User的昵称,那么在其它界面中就会立刻更新。
与广播接收者对比:
咱们上面是通过单例+观察者的模式来管理Model数据:
- 单例模式,让数据可以全局唯一,方便读写。
- 观察者模式,当数据被更新时,能及时反映到其他所有界面或者类中。
使用观察者模式和广播接收者有什么不同?
事实上,广播机制内部就是通过观察者模式来实现的,它们都是事先注册、事后注销,所以广播接收者和观察者不是对立关系,可以相互替代。
那为什么不使用单例+广播接收者模式呢?
广播接收者是为更大的场景而设计的,所以它提供了Action等特性,而这些特性是笔者所用不到的。在管理Model数据这个问题上,笔者直接用观察者模式反而更灵活(占内存少、代码更简单)。
同时在观察者模式的基础上加入了单例模式,让结构变的清晰了,还可以加上原型模式。观察者在Android比较常用,主要用于GUI。
本节参考阅读:
备忘录模式
模式介绍
下面是备忘录模式的定义:
在不破坏封闭的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以后就可将该对象恢复到原先保存的状态。
其实这个模式很简单,我们先不管上面的描述,假设现在要做一个记事本的App,要拥有保存、撤销两个功能,我们第一版的代码可能是这样的:
1 | public class MainActivity extends AppCompatActivity { |
语句解释:
- 使用EditText来实现记事本,并提供两个按钮,当点击保存时就把内容存到ArrayList中。
通过前面的学习,我们很容易就能看出来这么写代码如下问题:
- MainActivity职责太多,即要负责View部分的逻辑,还要负责管理记事本保存和还原操作,长此以往就会导致代码膨胀,难以维护。
- 如果除了要保存文本外,还需要保存光标的位置等其他信息,则现有代码需要改动很大。
解决的方法很简单,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70// 首先创建一个JavaBean用来封装要保存的数据。
public class Memento {
public String text;
public int cursor;
}
// 然后自定义EditText,让它自己处理数据的备份和还原。
public class NoteEditText extends EditText {
public NoteEditText(Context context) {
super(context);
}
public NoteEditText(Context context, AttributeSet attrs) {
super(context, attrs);
}
public Memento createMemento(){
Memento memento = new Memento();
memento.text = getText().toString();
memento.cursor = getSelectionStart();
return memento;
}
public void restore(Memento memento){
setText(memento.text);
setSelection(memento.cursor);
}
}
// 创建一个管理类,负责维护记录列表。
public class NoteCaretaker {
private final int MAX = 10;
private ArrayList<Memento> mContentList = new ArrayList<Memento>();
public void appendMemento(Memento memento) {
if (mContentList.size() > MAX) {
mContentList.remove(0);
}
mContentList.add(memento);
}
public Memento removeMemento() {
Memento memento = null;
if (mContentList.size() > 0) {
memento = mContentList.remove(mContentList.size() - 1);
}
return memento;
}
}
// 最后就是客户端的代码。
public class MainActivity extends AppCompatActivity {
private NoteEditText mEditText;
private NoteCaretaker mCaretaker = new NoteCaretaker();
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
public void onClick(View view) {
switch (view.getId()) {
case R.id.save:
mCaretaker.appendMemento(mEditText.createMemento());
break;
case R.id.undo:
mEditText.restore(mCaretaker.removeMemento());
break;
}
}
}
语句解释:
- 上面每一个类都是不可缺少的,Memento表示一个备份记录,自定义EditText是因为只有它自己才知道要备份哪些东西,NoteCaretaker用来维护备份列表。
- 此时可以看出,Activity的代码变清晰了。
上面代码就是使用了备忘录模式,我们接下来看一下这个模式的UML图。
UML类图
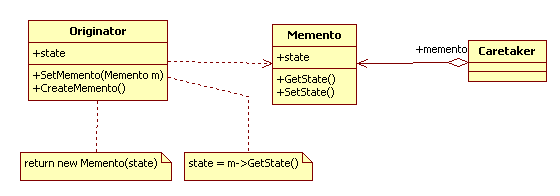
角色介绍:
- Originator:被备份的目标,它需要提供备份和还原数据的方法,比如上面的NoteEditText。
- Memento:备份对象,通常它是Originator的子集,之所以不直接备份Originator是因为很多时候我们只需要备份Originator的某几个字段,而不是全部字段,比如上面的Memento类。
- Caretaker:负责管理备份对象,比如将数据持久化到本地等,就是上面的NoteCaretaker对象。
总结
备忘录模式的扩展:
- 当需要保存一个对象在某一个时刻的状态或部分状态时,就可以使用备忘录模式(比如游戏存档)。
- 其实Activity类的源码就有备忘录模式的影子:
- Activity、Fragment、View、ViewGroup等可被保存状态对象就是Originator对象,因为它们都提供了类似于onSaveInstanceState和onRestoreInstanceState方法。
- Activity还扮演了Caretaker角色。
- Memento则由Bundle类扮演。
- 从Activity的例子可以看出来,设计模式并没有固定的形式,应该活学活用。
备忘录模式的优缺点:
- 优点:给用户提供了一种可以恢复状态的机制,可以使用户能比较方便地回到某个历史的状态。
- 缺点:消耗资源,如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存。
迭代器模式
模式介绍
迭代器(Iterator Pattern)又称为游标(Cursor)模式,是行为型设计模式之一。迭代器模式算是一个比较古老的设计模式,其源于对容器的访问,比如Java中的List、Map、数组等,我们知道对容器对象的访问必然会涉及遍历算法,我们可以将遍历的方法封装在容器中,或者不提供遍历方法。如果将遍历的方法封装到容器中,那么对于容器类来说就承担了过多的功能,容器类不仅要维护自身内部的数据元素而且还要对外提供遍历的接口方法,如果我们不提供遍历方法而让使用者自己去实现,又会让容器的内部细节暴露无遗,正因于此,迭代器模式应运而生,在客户访问类与容器之间插入了一个第三者——迭代器,很好地解决了上面所述的弊端。
因此迭代器模式的定义为:
- 提供一种方法顺序访问一个容器对象中的各个元素,而又不需要暴露该对象的内部表示。
- 很显然,当需要遍历一个容器对象时,就是使用迭代器模式之日。
UML类图
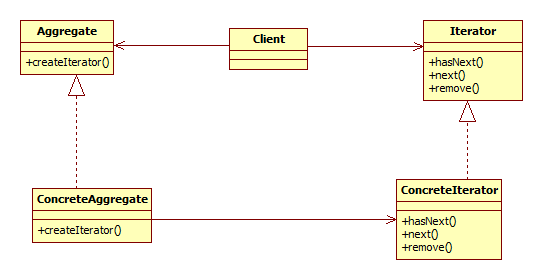
角色介绍:
- Iterator:迭代器接口,定义迭代器所必备的公共方法,如hasNext、next等。
- ConcreteIterator:Iterator的实现类,负责具体的实现。
- Aggregate:容器接口,定义容器应该具有的公共方法,如add、remove等。
- ConcreteAggregate:具体的容器类。
应用范例
1 | // 它的相当于java.util.Iterator类。 |
语句解释:
- 对于迭代器模式来说,其自身的有点很明显也很单一,支持以不同的方式去遍历一个容器对象,也可以有多个遍历,弱化了容器类与遍历算法之间的关系,而其缺点就是对类文件的增加,另外我们通常会把Iterator做为容器的内部类来写。
- 大家也可能会想到其他的语言,如C++、Python、PHP等,它们内部也有众多容器体的定义,当然也有相应的迭代器。迭代器模式发展至今,几乎每一种高级语言都有相应的内置实现,对于开发者而言,已经极少会去由自己来实现迭代器了,因此,对于本节的内容更多的是在于了解而非应用。
模版方法模式
模式介绍
模版方法模式的定义为:
定义一个操作中的算法的框架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可以重定义该算法的某些特定步骤。
举个办银行卡例子,其实银行已经将开户的所有流程给规定好了(填表、排号、交身份证、交手续费等),虽然流程固定好了,但是每个步骤中需要我们客户参与到其中,比如填表时每个客户填自己的信息,交本人的身份证等,每个客户的信息银行是无法预知的,只能让客户来提供。这个场景换算到程序中就是模板设计模式,所谓的模版就是我们事先把能考虑到的、重用的代码放到父类中,而将一些不可预知的、需要用户提供的数据定义成抽象方法,并交给子类去重写。
假设有一个Person类,它有学生和工人两个子类,学生和工人都可以说话,只不过内容不同。
1 | public abstract class Person { |
语句解释:
- 从本范例可以看出来,模版设计模式就是把共用的代码提取到父类中,并定义若干方法供子类重写,这些方法不一定要是抽象的。
UML类图
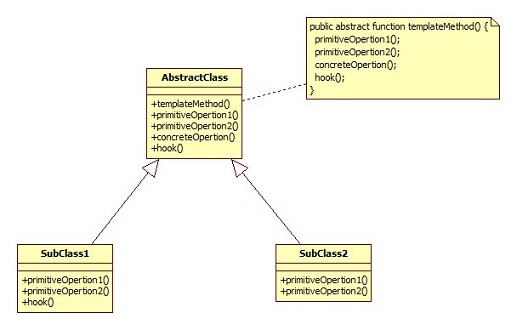
角色介绍:
- AbstractClass:模版类,其内封装公用的代码。
- SubClass1:子类1。
- SubClass2:子类2。
总结
模版设计模式:
- 在Android中AsyncTask就是模版设计模式的应用典范。
- 优点:封装不变部分,扩展可变部分,便于维护。
- 缺点:对于初级工程师来说,代码阅读难度增加。
中介者模式
模式介绍
有时候在一个系统中对象之间的联系呈现为网状结构(如下图左所示),对象之间存在大量的多对多联系,将导致系统非常复杂。在网状结构中,几乎每个对象都需要与其他对象发生相互作用,而这种相互作用表现为一个对象与另外一个对象的直接耦合,这将导致一个过度耦合的系统。
此时我们就可以使用中介者模式,它能够使对象之间的依赖关系如下图右所示,即让各对象只依赖于中介者(Mediator),并由该中介者进行统一协调,这样对象之间多对多的复杂关系就转化为相对简单的一对多关系。通过引入中介者来简化对象之间的复杂交互,中介者模式是“迪米特法则”的一个典型应用。
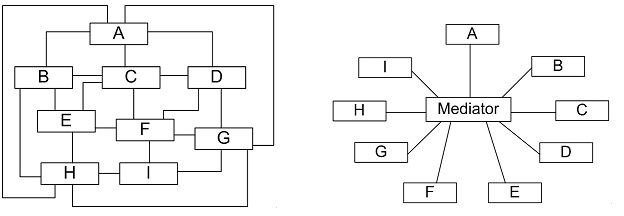
应用范例
我们使用一个例子来说明一下什么是同事类:有A和B两个类,类中各有一个数字,并且要保证类B中的数字永远是类A中数字的100倍。也就是说,当修改类A的数时,将这个数字乘以100赋给类B,而修改类B时,要将数除以100赋给类A。类A类B互相影响,就称为同事类。代码如下:
1 | abstract class AbstractColleague { |
语句解释:
- 上面的代码中,类A类B通过直接的关联发生关系,假如我们要使用中介者模式,类A类B之间则不可以直接关联,他们之间必须要通过一个中介者来达到关联的目的。
修改后的代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80 abstract class AbstractColleague {
protected int number;
public int getNumber() {
return number;
}
public void setNumber(int number){
this.number = number;
}
//注意这里的参数不再是同事类,而是一个中介者
public abstract void setNumber(int number, AbstractMediator am);
}
class ColleagueA extends AbstractColleague{
public void setNumber(int number, AbstractMediator am) {
this.number = number;
am.AaffectB();
}
}
class ColleagueB extends AbstractColleague{
public void setNumber(int number, AbstractMediator am) {
this.number = number;
am.BaffectA();
}
}
abstract class AbstractMediator {
protected AbstractColleague A;
protected AbstractColleague B;
public AbstractMediator(AbstractColleague a, AbstractColleague b) {
A = a;
B = b;
}
public abstract void AaffectB();
public abstract void BaffectA();
}
class Mediator extends AbstractMediator {
public Mediator(AbstractColleague a, AbstractColleague b) {
super(a, b);
}
//处理A对B的影响
public void AaffectB() {
int number = A.getNumber();
B.setNumber(number*100);
}
//处理B对A的影响
public void BaffectA() {
int number = B.getNumber();
A.setNumber(number/100);
}
}
public class Client {
public static void main(String[] args){
AbstractColleague collA = new ColleagueA();
AbstractColleague collB = new ColleagueB();
AbstractMediator am = new Mediator(collA, collB);
System.out.println("==========通过设置A影响B==========");
collA.setNumber(1000, am);
System.out.println("collA的number值为:"+collA.getNumber());
System.out.println("collB的number值为A的10倍:"+collB.getNumber());
System.out.println("==========通过设置B影响A==========");
collB.setNumber(1000, am);
System.out.println("collB的number值为:"+collB.getNumber());
System.out.println("collA的number值为B的0.1倍:"+collA.getNumber());
}
}
语句解释:
- 复杂的网状结构,是一种过度耦合的架构,即不利于类的复用,也不稳定。
- 引入中介者模式后,同事类之间的关系将变为星型结构,任何一个类的变动,只会影响的类本身,以及中介者,这样就减小了系统的耦合。
UML类图
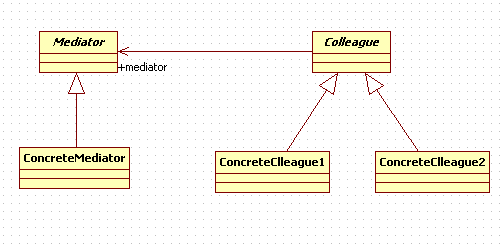
角色介绍:
- Mediator:抽象中介者角色,定义了同事对象到中介者对象的接口,一般以抽象类的方式实现。
- ConcreteMediator:具体的中介者。
- Colleague:抽象同事类。
- ConcreteColleagueA/B:具体的同事类角色。
总结
中介者设计模式:
- 其实在Android中我们经常使用中介者模式,Activity就扮演着Mediator的角色,比如登录界面,只有用户在两个文本框都输入内容时,登录按钮才可以被点击,这样一来文本框和按钮就是同事对象了。
- 优点:将对象间多对多的关系转为一对多,降低耦合。
- 缺点:中介者模式是一种比较常用的模式,也是一种比较容易被滥用的模式。对于大多数的情况,同事类之间的关系不会复杂到混乱不堪的网状结构,因此,大多数情况下,将对象间的依赖关系封装的同事类内部就可以的,没有必要非引入中介者模式。滥用中介者模式,只会让事情变的更复杂。
- 另外,中介者需要对外界提供所有同事类的接口,以供其它同事类调用,因此中介者里的代码会有很多。
本节参考阅读:
结构型模式
代理模式
代理是什么?为什么需要代理呢?
其实程序里的代理与日常生活中的“代理”,“中介”差不多;比如你想海淘买东西,不可能亲自飞到国外去购物,这时候我们使用第三方海淘服务比如考拉海购等;
代理其实是有两面性的:
- 好处是:方便、省时间。
- 坏处是:由于我们不是和最终商家沟通,而是和代理者沟通,因此代理可以提高商品的价格、或者将购买的正品留下,换成次品再发给我们等。
在程序中也有很多场景会用到“代理”的概念,接下来先来学习一下代理模式的基本写法。
UML类图
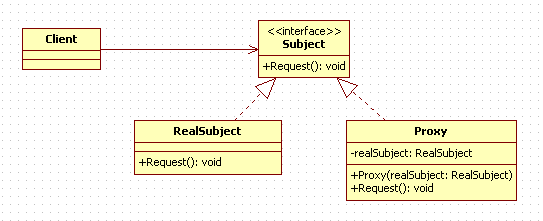
角色介绍:
- Subject:抽象主题类,其内定义了公共的抽象方法。
- RealSubject:真是的主题类。
- ProxySubject:代理主题类,它不会真正执行业务逻辑,而是会转调用RealSubject去执行。
通常每个项目都会有自己的Http模块,我们来模拟一下请求过程,先定义一个接口:1
2
3
4public interface HttpRequest {
// 传递url和参数,执行请求。
String doRequest(String url, Map<String,String> params);
}
它有一个原始的实现,代码如下:1
2
3
4
5
6
7
8
9public class RealHttpRequest implements HttpRequest {
public String doRequest(String url, Map<String,String> params) {
// 用伪代码来模拟一下,执行网络请求
HttpResponse response = ...;
String json = response.getResult();
return json;
}
}
上面的代码看起来没有问题,但是有一天新来个需求:
在任何接口的返回值中,如果状态吗返回了20003,则就让程序跳转到登录界面,让用户登录。
此时新手可能会这么写代码:1
2
3
4
5
6
7
8
9
10
11
12
13public class RealHttpRequest implements HttpRequest {
public String doRequest(String url, Map<String,String> params) {
// 用伪代码来模拟一下,执行网络请求
HttpResponse response = ...;
String json = response.getResult();
// 判断状态码
if(new JSONObject(json).getInt("code") == 20003){
startActivity(...);
}
return json;
}
}
语句解释:
- 这么做确实能解决问题,但是违反了单一指责原则,RealHttpRequest应该只负责执行网络请求,对状态码的判断应该在另外的地方,若这种情况都去修改RealHttpRequest类的话,以后再来新需求,还可能会去修改它。
此时可以使用代理模式,定义一个ProxyHttpRequest类,在其内部转调用RealHttpRequest:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class ProxyHttpRequest implements HttpRequest {
// 真正去执行请求的对象。
HttpRequest real;
ProxyHttpRequest(HttpRequest real) {
this.real = real;
}
public String doRequest(String url, Map<String,String> params) {
// 请求执行之前的预处理操作
// ……
// 调用正主执行请求
String json = real.doRequest(url, params);
// 判断状态码
if(new JSONObject(json).getInt("code") == 20003){
startActivity(...);
}
// 返回数据
return json;
}
}
语句解释:
- 代理模式其实就是在真正的任务的开头或末尾加上一些操作,最终执行任务的,仍然是客户本人。
再举个例子:假设现在有A、C两个对象,但是A和C不在一个服务器上,且A会频繁的调用C。
此时就可以做一个代理类Proxy,把访问C的工作交给Proxy(处理网络请求等),这样对于A来说,就好像在直接访问C的对象,在对A的开发中我们可以把注意力完全放在业务的实现上。如下图所示:
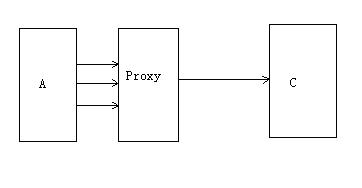
另外,在《Framework篇》中也可以看到代理模式的应用范例,在IPC时客户端和服务端分别存在一个Proxy对象,用来帮助对象在跨进程传递时的封包和拆包。
动态代理
上面的介绍代理模式被称为静态代理,静态代理要为每一个需要代理的类写一个代理类。
- 如果需要代理的类有几百个,那就很蛋疼了;而且在使用的时候会发现,每个代理方法里的内容相似度很高(都是先在方法的开头或结尾做一些事情,然后再调用真正的业务类的方法)。
- 为此Java提供了动态代理方式,可以简单理解为,在运行时虚拟机会帮我们动态生成一系列的代理类,这样我们就不需要手写每一个静态的代理类了。
其实JDK本身就支持动态代理,依然以Http请求为例,用动态代理实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public void onClick(View view) {
final HttpRequest real = new RealHttpRequest();
// 创建代理对象
HttpRequest proxy = (HttpRequest) Proxy.newProxyInstance(
HttpRequest.class.getClassLoader(),
real.getClass().getInterfaces(), new InvocationHandler() {
public Object invoke(Object proxy,
Method method, Object[] args) throws Throwable {
if ("doRequest".equals(method.getName())) {
// 调用正主执行请求
String json = method.invoke(real, args);
// 判断状态码
if(new JSONObject(json).getInt("code") == 20003){
startActivity(...);
}
return json;
}
return null;
}
});
// 执行网络请求
System.out.println(proxy.doRequest("http://xxxxx", new HashMap<String,String>()));
}
语句解释:
- 动态代理只能作用在接口上,不能动态代理类。
总结
代理模式:
- 代理模式应用很广泛,后面我们讲到的其它结构型模式中,你都可以看到代理模式的影子。
- 一言以蔽之,代理类的任务就是处理真实主题类所不愿意处理的事情,最终任务的执行还是由真是主题类去做。
本节参考阅读:
适配器模式
模式介绍
有时,现有的类可以满足客户类的功能需要,但是它所提供的接口不一定是客户类所期望的,这可能是因为现有类中方法名与客户端期望的方法名不一致等原因所导致的。
在这种情况下,现有的接口需要转化为客户类期望的接口,这样保证了对现有类的重用。
适配器模式的定义为:
- 适配器模式把一个类的接口变成客户端所期望的另一个接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。
UML类图
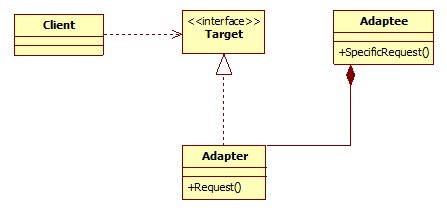
角色介绍:
- Target:目标角色,也就是客户端所期望的接口。
- Adaptee:现有的类,也就是需要被适配的接口。
- Apdater:适配器类。
应用范例
下面是Adapter模式的简单实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// 已存在的、具有特殊功能、但不符合我们既有的标准接口的类
public class Adaptee {
public void specificRequest() {
System.out.println("被适配的类,具有特殊功能...");
}
}
// 客户端期望的接口,或称为标准接口
public interface Target {
public void request();
}
// 具体目标类,只提供普通功能
public class Adapter implements Target {
Adaptee base;
public Adapter(Adaptee base){
this.base = base;
}
public void request() {
base.specificRequest();
}
}
public class Client {
public static void main(String[] args) {
// 使用普通功能类
Target adapter = new Adapter(new Adaptee());
adapter.request();
}
}
语句解释:
- 从上面的代码中可以看到,在Adapter模式中存在了代理模式的影子。
- 不同的是,代理模式会在request方法中添加一些代码,而适配器模式只是转调用。
还有一种情况,现有的类提供了相同的方法,但是却因为继承关系不匹配导致客户端无法使用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 已存在的、具有特殊功能、但不符合我们既有的标准接口的类
public class Adaptee {
public void request() {
System.out.println("被适配类具有 特殊功能...");
}
}
// 目标接口,或称为标准接口
public interface Target {
public void request();
}
// 具体目标类,只提供普通功能
public class Adapter extends Adaptee implements Target {
}
public class Client {
public static void main(String[] args) {
// 使用普通功能类
Target adapter = new Adapter();
adapter.request();
}
}
语句解释:
- 这种写法被称为类适配器,上面的被称为对象适配器。
- 如果你手上有一个对象,且没有办法去实例化一个新对象的话,就可以用对象适配器。
还有一种情况,适配器做为外抛给客户端的接口:
比如ListView用来显示一个列表,但是它并不知道每个Item长什么样。于是通过一个BaseAdapter类来告诉客户端(开发者)要提供哪些数据,此时BaseAdapter就处于ListView和开发者之间,扮演转接的角色。
装饰模式
继承可以让一个类拥有其父类的行为,但是有些场景下继承并不总合适。比如我们开了家咖啡馆,有4种咖啡豆,同时用户购买咖啡时还可以搭配一些调料(比如牛奶、糖等),假设我们有5种调料,那么最终至少就需要20个类来表示所有的咖啡(还不算复合咖啡,就是同时加牛奶和糖)。而且如果牛奶的价格发生改变,那么至少得修改4个类的代码,显然是不可取的的。 此时我们就可以使用装饰模式。
装饰模式(Decorator)也称为包装模式(Wrapper),是结构型设计模式之一,它可以动态的给一个对象添加一些额外的职责,就增加功能来说,装饰模式相比生成子类更为灵活。
UML类图
我们先来看看装饰模式的UML图,然后去学习一下装饰模式的基础写法,最后再去看它的应用场景。
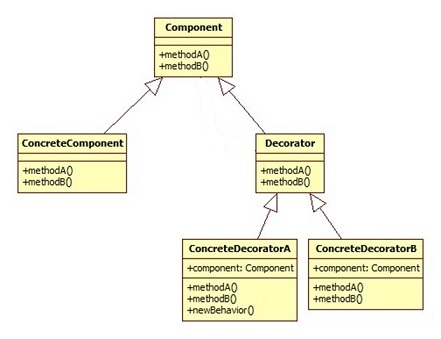
角色介绍:
- Component:抽象组件,就是被装饰的对象所实现的接口。
- ConcreteComponent:具体组件,也就是被装饰的对象。
- Decorator:抽象的装饰器。
- ConcreteDecoratorA:具体的装饰器。
接下来给出一个最简单的装饰器模式的写法:
1 | public abstract class Coffee { |
语句解释:
- 其实从写法上来说,Decorator是可以不继承Coffee类的,之所以让它继承,是因为装饰器必须和被装饰类拥有相同的接口。这样才能让客户端感觉到,使用装饰器和使用具体组件是没有区别的。
- 这样一来,假设用户选择了“加糖加牛奶加冰毒”我们的代码也能完成。
应用范例1
装饰模式在Java语言中的最著名的应用莫过于Java I/O标准库的设计了。
由于Java I/O库需要很多性能的各种组合,如果这些性能都是用继承的方法实现的,那么每一种组合都需要一个类,这样就会造成大量性能重复的类出现。而如果采用装饰模式,那么类的数目就会大大减少,性能的重复也可以减至最少。因此装饰模式是Java I/O库的基本模式。
Java I/O库的对象结构图如下,由于Java I/O的对象众多,因此只画出InputStream的部分。
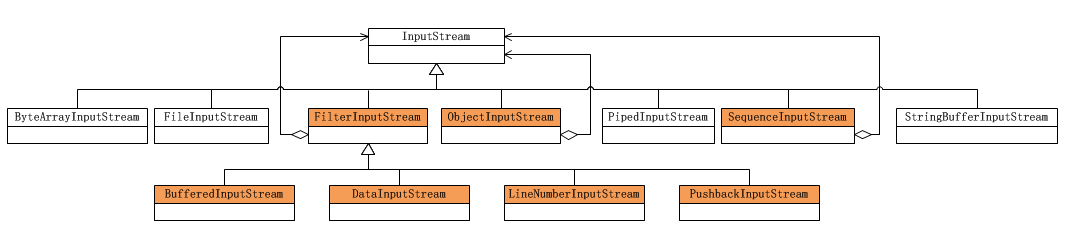
根据上图可以看出:
- Component:由InputStream扮演。这是一个抽象类,为各种子类型提供统一的接口。
- ConcreteComponent:由FileInputStream等类扮演,它们实现了抽象构件角色所规定的接口。
- Decorator:由FilterInputStream扮演,它实现了InputStream所规定的接口。
- ConcreteDecoratorA:由BufferedInputStream等类扮演。
应用范例2
我们都知道Context是Android开发中的上帝对象,很多地方都会用到这个类里定义的方法,而且Activity、Service都是该类的间接子类,但是当我们查看它们的继承树时就会发现,它们并不是直接继承Context类的,而是继承一个名为ContextWrapper的类。
很显然,ContextWrapper就是我们本节介绍的装饰模式里的装饰器,它内部持有一个mBase属性,它定义的所有方法都是转调用mBase的,原因可能是:
- 第一,Activity的使命是UI的展示,如果把startActivity等方法定义在其内话,违反单一指责原则。
- 第二,Service中也需要执行startActivity等方法,将这些方法放到ContextImpl类中可以方法代码重用。
本节参考阅读:
享元模式
模式介绍
享元模式(Flyweight)听起来很牛逼,其实在咱们一开始那个图片加载器中就已经使用到它了,简单地说,享元模式就是对象缓存的技术。
下面以买火车票为例,第一版的代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public interface Ticket {
public void showTicketInfo(String bunk);
}
public class TrainTicket implements Ticket {
public String from; // 始发地
public String to; // 目的地
public TrainTicket(String from, String to) {
this.from = from;
this.to = to;
}
public void showTicketInfo(String bunk) {
System.out.println("TrainTicket{" +
"from='" + from + '\'' +
", to='" + to + '\'' +
'}');
}
}
public class TicketFactory {
public static Ticket getTicket(String from, String to) {
return new TrainTicket(from, to);
}
}
语句解释:
- 猛地一看好像没什么问题,但是如果短时间内getTicket方法被调用10000次呢?每次查询的参数都是一样的,但是频繁创建了大量对象。
为了减少对象的创建,我们就可以使用享元模式,对一些常用的对象进行缓存,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13public class TicketFactory {
static Map<String, Ticket> cache = new HashMap<>();
public static Ticket getTicket(String from, String to) {
String key = from + "-" + to;
Ticket ticket = cache.get(key);
if (ticket == null) {
ticket = new TrainTicket(from, to);
cache.put(key, ticket);
}
return ticket;
}
}
语句解释:
- 当然,本范例只是为了演示模式的用法,正式使用的时候,还可以在这基础上加一个超时机制,超过1分钟对象即便被缓存,也应该重新请求。
第二节 Jetpack
在 Google I/O 2018 开发者大会上,谷歌推出了Jetpack组件,它是一个库的集合,使用这些库可帮助您:
1、消除样板代码:帮你管理繁琐 Activity(如后台任务、导航和生命周期管理)等
2、构建高质量的强大应用:围绕现代化设计实践构建而成,具有向后兼容性,可以减少崩溃和内存泄漏
遵循最佳做法、让您摆脱编写样板代码的工作并简化复杂任务,以便您将精力放在编写更重要的代码上。
概述
从 Jetpack官网 上可以看出,谷歌将 Jetpack 组件按照功效的不同,划分为四种类型的子组件:

每个子组件里又包含了若干个具体的库 :
基础组件:Android KTX、AppCompat、Auto、多dex处理等。
架构组件:数据绑定、Lifecycles、LiveData、Paging、ViewModel、Room等。
行为组件:媒体和播放、权限、通知、分享、下载管理器等。
界面组件:动画和过度、表情符号、布局、Fragment等。
其实从上面列出来的库名就可以看出,Jetpack组件里除了添加新的库外,也将一些老技术放到了其内。
架构组件
本节我们就来介绍一下架构组件里的各个库。
什么是软件架构
在回答这个问题之前,我们先来思考另一个问题:软件的本质是什么?
本质就是程序员给用户一堆按钮列表,让用户执行相应的操作,然后将产生的数据持久化。
也就是说我们可以将软件开发,拆分成“绘制用户界面” 和 “处理与保存用户的数据”两大部分,即“输入/输出”。
再来看另一个问题:为什么要进行软件架构?
复杂的软件必须有清晰合理的架构,否则无法长久的开发和维护。
虽然都知道软件架构的重要性,但是我们到底要架构什么?
让软件以更合理的方式,完成输入/输出,并可以高效的长久开发和维护下去。
三种软件架构方式
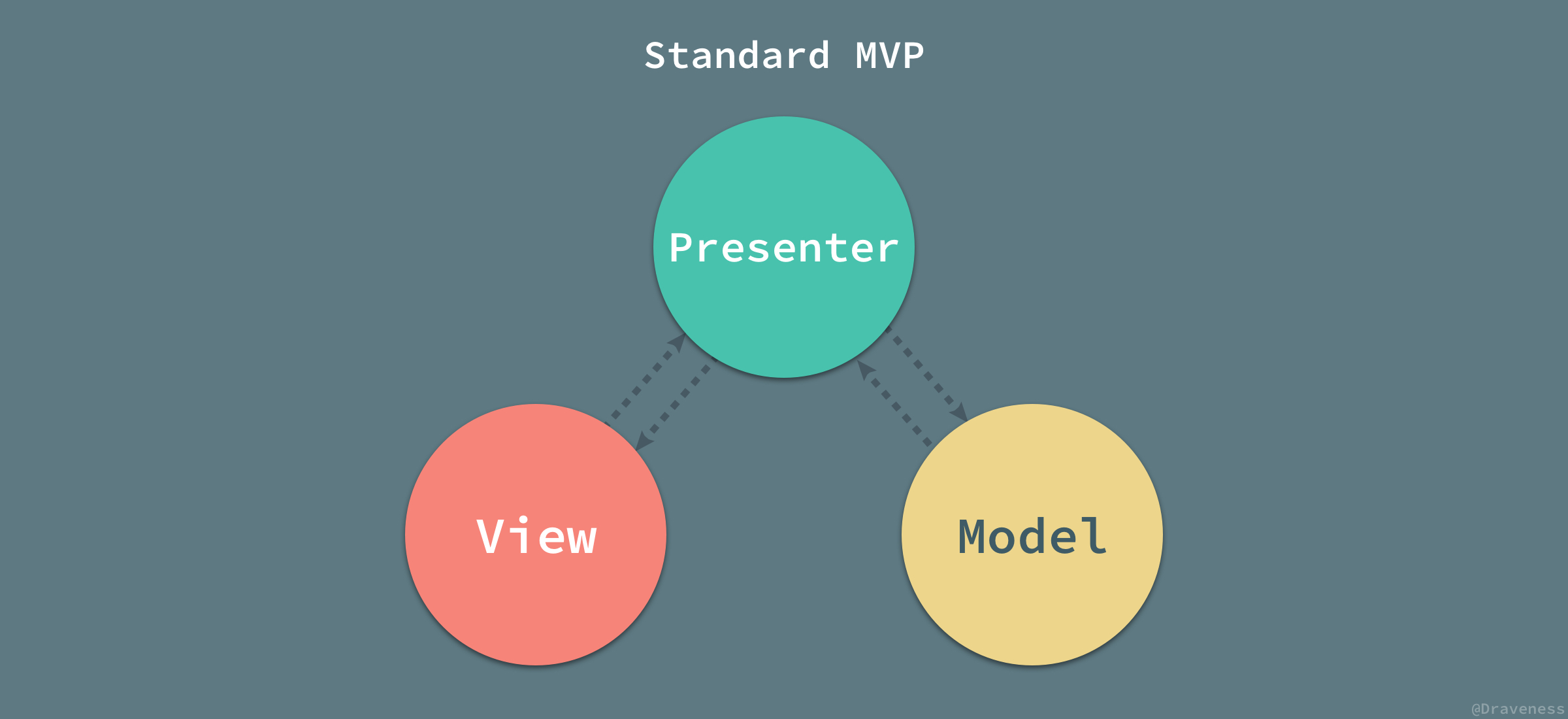
MVC
在MVC架构模式中,软件被分成如下三个部分:
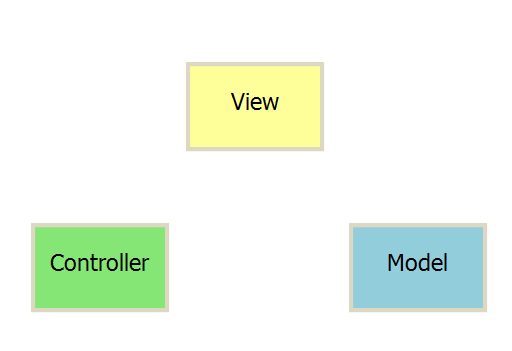
上图中各个部分的作用“大致为”:
视图(View):用户界面;对应着上面提到的“用户输入”。
模型(Model):数据处理与持久化;对应着上面提到的“用户输出”。
控制器(Controller):业务逻辑和业务转发
为什么要说“大致为”呢?
因为虽然 MVC 已经拥有将近 50 年的历史了,且也是一个应用很广泛的架构模式了,但 MVC 并没有一个明确的定义,网上流传的 MVC 架构图也是形态各异,各有各的道理。
感兴趣的朋友可以去看看这篇《浅谈 MVC、MVP 和 MVVM 架构模式》文章。
总而言之,在这些年中 MVC 产生了很多的变种,不同的平台对 MVC 的使用也各有特色。笔者不打算也没有能力给出 MVC 的明确定义,只能在这里简单的分享一下自己的理解,如果和您的理解不同,请多包涵。
以下是个人理解
阮一峰 在自己的博客中画了一张图,图中列出了 MVC 各部分之间的通信方式。
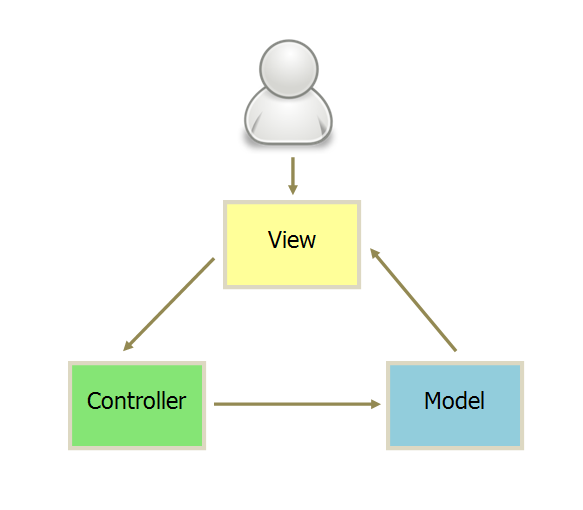
1、用户通过View来与软件交互
2、View 被操作后,会传送指令到 Controller
3、Controller 接到请求后,会依据情况,来将请求转发给对应的 Model 进行处理
4、Model 处理完毕后,将新的数据发送到 View,用户得到反馈
需要注意的是,在上图中所有通信都是单向的,峰哥的这张图与笔者对 MVC 理解比较相近,但不够详细。
笔者以 Android 为例,具体的介绍一下三个模块的职责:
View:负责绘制用户界面。它包括Activity、Fragment、Dialog、各类Adapter和自定义控件。
Model:负责处理与持久化数据。它提供一些数据处理的方法给外界使用(包括但不限于:联网请求数据、数据库CRUD等等),Model 一直是被动的响应请求,它感知不到 View 和 Controller 的存在。
Controller:负责处理业务逻辑和业务转发。它依据 View 传递过来的请求,调用一个或者多个 Model 响应。
此时你可能会有一个问题: 既然 Model 无法感知到 View ,那当它处理完数据后,如何通知 View 更新呢?
通过观察者模式,我们可以实现 Model 和 View 之间的通讯和解耦。
对应到 MVC 中,Model 是被观察的对象,View 是观察者,Model 层一旦发生变化,View 层即被通知更新。
只靠嘴说可能有点难以理解,请看下面的类图(点击可以放大图片):
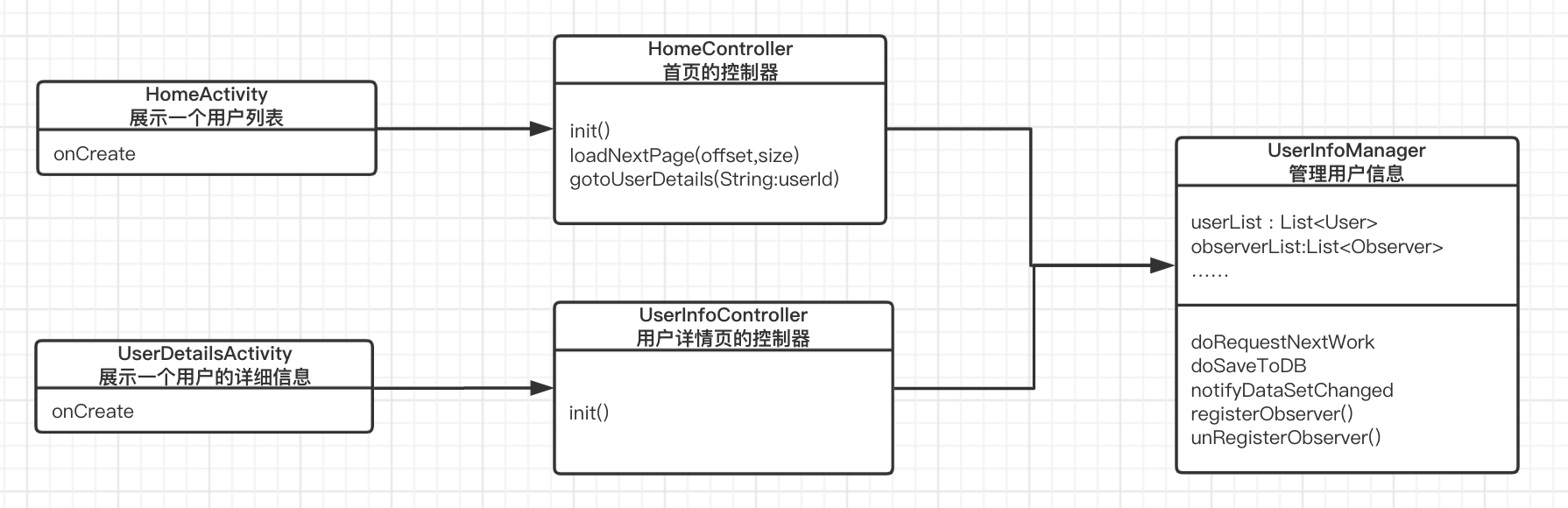
图释:
1、图中有两个 Activity 类,它们各自拥有自己的 Controller 类。
2、图中只有一个 Model 类(UserInfoManager),但是它却可以服务于多个 Activity 类,相应的一个 Activity 如果足够复杂的话,是可以使用多个 Model 类所管理的数据的。
3、在 Activity 被创建后,除了会调用 Controller 的init方法获取初始化数据外,还需要调用 Model 类提供的 regster 将自己注册成为观察者,以便接收数据的改变回调。
4、如果你想为“网络请求”和“数据存储”提供多种实现方式(比如数据存储不一定要用数据库),改动范围就只涉及到 Model 类了。
有一个建议:在 MVC 程序中,View 的设计要‘傻’,Controller 要‘轻’,Model 要‘重’。
View 里面不要写复杂的逻辑,这样就不好维护,一般只是数据的展示,UI 和 交互。
Controller 就调用 Model 里面的方法,做一些的逻辑转发的事情。
Model 里写各种业务逻辑的方法,数据的CRUD。
另外,笔者在面试的时候通常会问候选人“MVP是为了解决什么问题而诞生的?”,得到的答案一般都是:
我们以前是用 MVC 模式的,但是会导致 Activity 的代码特别多,不利于维护,所以我们就用了 MVP 模式,代码结构就清晰好多,虽然会产生大量的接口。
其实不是 MVC 导致 Activity 代码臃肿,而是他们根本没理解 MVC 应该怎么写。
他们把 Activity 视为 Controller ,自然会把 Controller 的代码写到 Activity 中,甚至于如果心情不好偷懒的话,Activity 还会承担部分 Model 的工作,自然会越写越臃肿。
退一步说,Activity 最多只能算是 View 层内部的 Controller ,负责控制界面里的所有 View 的。
最后,你可能还会有一个问题,按照前面说的,软件的本质就是输入和输出,而 View 表示输入, Model 表示输出,既然 Controller 只是用来转发,那么直接让 View 和 Model 交互就好了,为什么还要有 Controller 呢?
如果让 View 和 Model 直接通讯的话,缺点显而易见:
1、Controller 原来的工作势必由 View 来承担,导致 View 代码臃肿。
2、Model 和 View 的代码势必穿插在各个类里,任何一方的改变,通常都会伴随着大量的代码修改。
记住一个经验:
如果两个人需要通信,那么最好不要让他们直接通讯,而应该加入一个中间层,用来转发通信。
这么做就大大提高了灵活度,当 V 发生变化时不会影响CM,当 M 发生变化时,只稍微修改一下 C 就可以了,而 C 的代码量并不多,大头都在 V 和 M 上了。
本节参考阅读:
MVP
MVP 架构模式是 MVC 的一个变种,它们之间的区别其实并不明显,笔者认为两者之间最大的区别就是 MVP 中使用 Presenter 对视图和模型进行了解耦,它们彼此都对对方一无所知,沟通都通过 Presenter 进行。
MVP 架构模式的交互流程为:
1、用户通过View来与软件交互
2、View 被操作后,会传送指令到 Presenter
3、Presenter 接到请求后,会依据情况,来将请求转发给对应的 Model 进行处理
4、Model 处理完毕后,通知 Presenter , Presenter 再将新的数据发送到 View ,用户得到反馈
虽然看起来变化不大,但是代码的写法上却有明显的区别,我们同样来看一个例子:
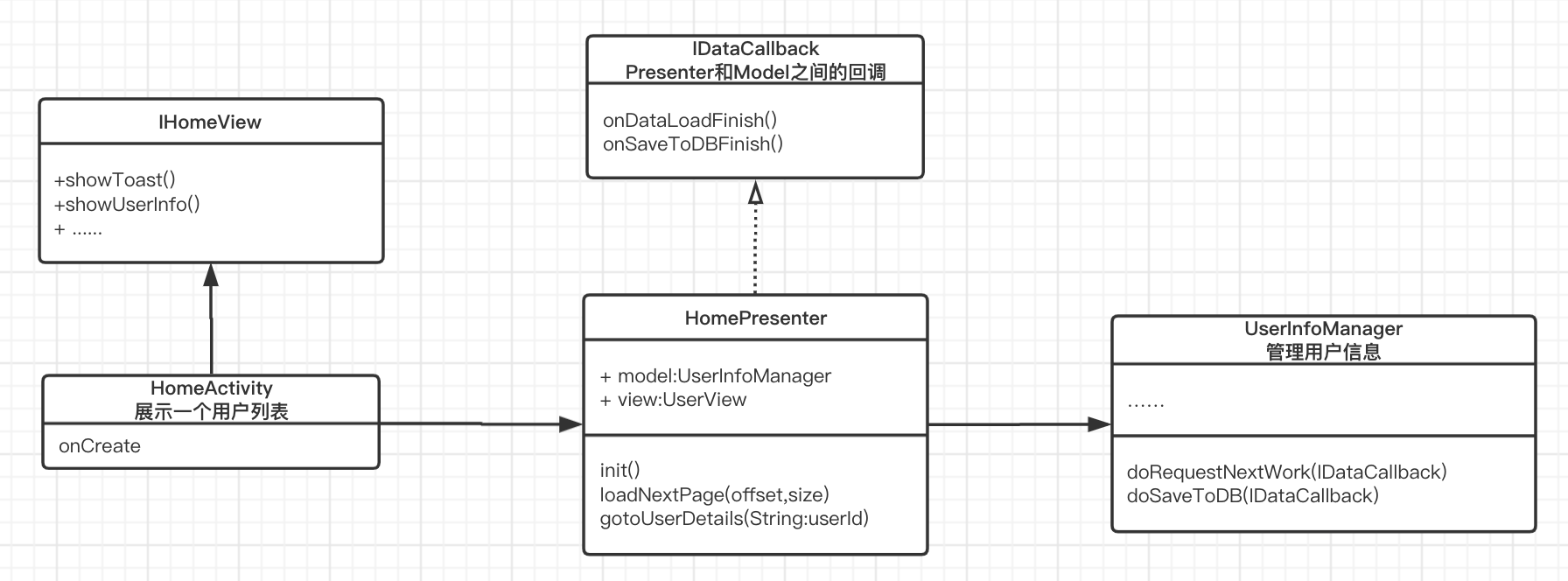
1、HomeActivity 和 UserInfoManager 依然表示 View 和 Model ,但 HomeController 却被替换为三个类。
2、与 MVC 的流程类似: View -> Presenter -> Model ,而 IDataCallback是一个接口,当 Presenter 调用 Model 执行具体业务时,会传递此对象给Model,当做回调对象。
3、IHomeView也是一个接口,当 Presenter 接到 Model 的回调后,会调用此接口的方法去操作 View ,因此让 HomeActivity 去实现此接口。
也就是说, MVP 相比于 MVC 产生了如下变化:
1、彻底断开了 View 和 Model 之间的观察者连接,让 Presenter 和 Model 通过回调接口的方式建立连接。
2、在 Presenter 中同时持有 View 和 Model 的引用。
另外, Google 早已经提供了一个官方的 MVP Demo :TODO - MVP,有兴趣的同学可以去看看。最后以笔者目前有限的眼界总结一下: MVP 模式引入的大量的类与接口,却带不来明显的好处。
本节参考阅读:
MVVM
MVVM 是 Model - View - ViewModel 的简写。
MVVM 其实是 MVP 的改进版,它将 MVP 中的 Presenter 替换成了 ViewModel 。
MVVM 架构模式的交互流程为:
1、首先在 View 和 ViewModel 之间使用“数据绑定”技术,让二者建立双向绑定,一旦某一方被修改,“数据绑定”就会立刻通知另一方
2、当 View 被用户操作后,会传送指令到 ViewModel
3、ViewModel 接到请求后,会依据情况,来将请求转发给对应的 Model 进行处理
4、Model 处理完毕后,通知 ViewModel 更新数据,此时由于“数据绑定”的存在,View 也会立刻更新
也就是说, MVVM 相比于 MVP 的改动有:
1、将 Presenter 替换成了 ViewModel 。
2、在 View 和 ViewModel 之间,添加了一个“数据绑定”技术,这个技术就消除了 MVP 模式中 View 和 Presenter 之间的接口。
Android 中的 MVVM
事实上, MVVM 是目前 Google 官方比较推崇的架构模式,Jetpack 里提供的 DataBinding 、 ViewModel 等库都非常适用于实现 MVVM ,本节会着重介绍这些库的用法。
首先来看一下下面这张图,该图显示了基于 MVVM 架构的项目应该是什么样的:
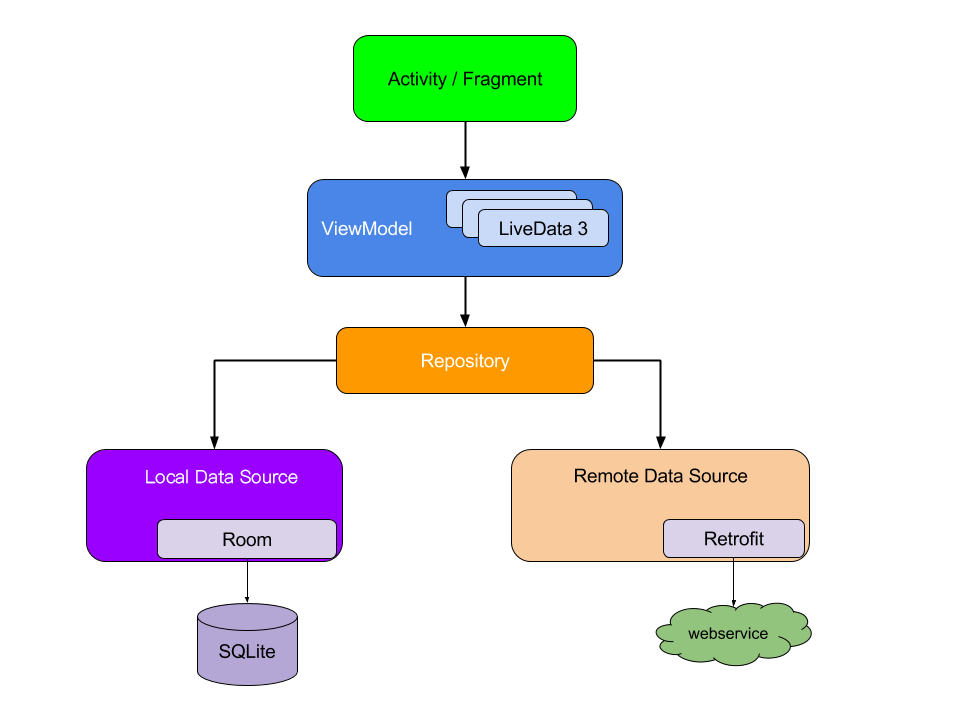
请注意,每个组件仅依赖于其下一级的组件。例如,Activity 和 Fragment 仅依赖于视图模型, Repository 是唯一依赖于其他多个类的类。
小提示:
上面的架构图不可能适合所有项目,但这个架构是我们学习 MVVM 的一个不错的起点。
ViewModel
在正式介绍 ViewModel 的作用之前,我们先来看一下三个问题。
问题1:数据存储
我们知道 Android 框架可以管理界面控制器(如 Activity 和 Fragment)的生命周期,同时它也会依据用户的操作来决定销毁或重新创建界面控制器。
如果系统销毁或重新创建界面控制器,则存储在其中的任何临时性界面相关数据都会丢失。对于简单的数据,Activity 可以使用 onSaveInstanceState() 方法从 onCreate() 中的捆绑包恢复其数据,但此方法仅适合少量数据,而不适合数量可能较大的数据。
问题2:异步请求
界面控制器经常需要进行异步调用,因此需要确保在控制器销毁后及时清理这些调用,以避免潜在的内存泄露。此项管理需要大量的维护工作,并且若用户切换了一下屏幕,默认会导致 Activity 重建,如果此时触发清理操作,会造成资源的浪费,因为对象需要重新发起异步调用。
问题3:数据共享
如果一个 Activity 里存在多个 Fragment ,那么多个 Fragment 之间就可能需要进行数据通信,为了实现这个需求,同样需要写不少代码。
不论你之前是用 MVC 还是 MVP ,你都需要直面这三个问题,虽然解决它们并不难,但在 Jetpack 中已经帮我们处理好了,它就是 ViewModel 库。
范例1:创建一个 ViewModel 类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 创建一个类继承 androidx.lifecycle.ViewModel 即可。
public class UserViewModel extends ViewModel {
private User user;
public UserViewModel() {
// 姓名和年龄
user = new User("Hello", 20);
}
public User getUser() {
return user;
}
// 当 ViewModel 需要被销毁的时候会回调此方法。
protected void onCleared() {
}
}
范例2:实例化 ViewModel 类。1
2// 下面的 this 可以是 FragmentActivity 或 Fragment 的子类。
UserViewModel model = new ViewModelProvider(this).get(UserViewModel.class);
语句解释:
- 需要注意的是不同版本的 ViewModel 库实例化的方法不一样,本范例是基于 viewmodel-2.2.0 版本的。
下图展示了 ViewModel 与 Activity 之间的生命周期对应关系。
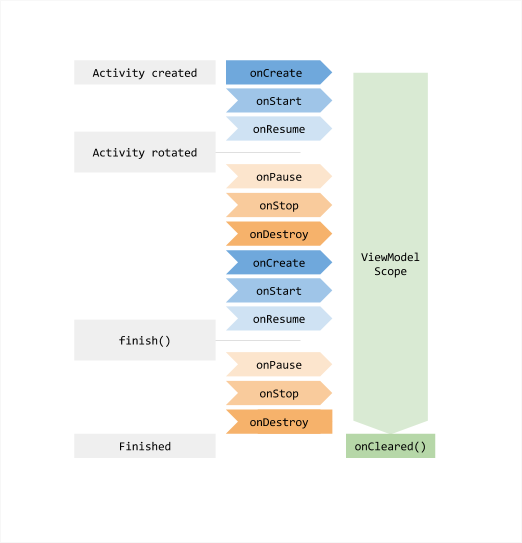
也就是说 Activity 因为配置改变(比如屏幕旋转)而导致的销毁重建并不会让 ViewModel 销毁。另外,如果你想在多个 Fragment 中共享数据的话,可以在 Fragment 中这么写代码:
1 | UserViewModel model = new ViewModelProvider(getActivity()).get(UserViewModel.class); |
最后总结一下:
1、ViewModel 主要的任务就是建立 View 和 Model 之间的链接,它内部通常会保存着从 Model 层获取到的 JavaBean 对象,以供 View 层使用。
2、ViewModel 已经帮我们监听了 Activity 和 Fragment 的生命周期,防止不必要的资源浪费和内存泄漏。
3、ViewModel 可以实现多个 Fragment 之间的数据共享。
如果你想知道 ViewModel 的更多信息,请阅读 《ViewModel 概览》 。
Lifecycle
Lifecycle 直译过来的意思是“生命周期”,通常我们用它来监听“界面控制器”的生命周期。
此时你可能会有一个疑问, Activity 和 Fragment 本身已经提供了生命周期方法,直接在对应的方法里写代码就好了,为什么还要搞一个 Lifecycle 呢?
其实前面笔者一直在强调 “要简化Activity中的代码” , “View层要傻” ,如果在生命周期方法里写了太多代码,会导致 Activity 越来越臃肿。
假设我们有一个 Activity 需要实时显示用户手机的方向和地理位置,你可能会这么写代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class MainActivity extends AppCompatActivity implements SensorEventListener, LocationListener {
private SensorManager mSensorManager;
private LocationManager mLocationManager;
protected void onResume() {
super.onResume();
// 方向传感器
mSensorManager.registerListener(this,
mSensorManager.getDefaultSensor(Sensor.TYPE_ORIENTATION),
SensorManager.SENSOR_DELAY_GAME);
mSensorManager.registerListener(this, mSensorManager.getDefaultSensor(Sensor.TYPE_PRESSURE),
SensorManager.SENSOR_DELAY_NORMAL);
// 获取位置信息。注意执行此代码需要权限,为了方便阅读,本范例就省略了。
mLocationManager.requestLocationUpdates(LocationManager.NETWORK_PROVIDER, 1000, 0, this);
}
// 此处省略 SensorEventListener 和 LocationListener 接口里的若干方法
protected void onPause() {
super.onPause();
mSensorManager.unregisterListener(this);
mSensorManager.unregisterListener(this);
mLocationManager.removeUpdates(this);
}
}
稍微优化一点的话,代码可能是这样的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class MainActivity extends AppCompatActivity {
// 将它们定义成单独的类
private MySensorManager mSensorManager = new MySensorManager();
private MyLocationManager mLocationManager = new MyLocationManager();
protected void onResume() {
super.onResume();
mSensorManager.onResume();
mLocationManager.onResume();
}
protected void onPause() {
super.onPause();
mSensorManager.onPause();
mLocationManager.onPause();
}
}
这样一来 Activity 的代码是少多了,但是也变蠢了,此时如果用 Lifecycle 代码就能优雅很多。
其实 Lifecycle 不是什么高深技术,本质上是“ 观察者模式 + 生命周期管理 ”:
1、在 Fragment 、 Activity 内部维护了一个“被观察者”,调用 getLifecycle() 方法获取“被观察者”的引用。
2、定义了一个 LifecycleObserver 接口,它是个空接口,需要我们去实现。
3、在实现类的方法中加上对应的注解。
具体使用的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public class MainActivity extends AppCompatActivity {
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// 通过 getLifecycle() 方法获取被观察者对象,然后将观察者注册进去。
getLifecycle().addObserver(new MySensorManager());
getLifecycle().addObserver(new MyLocationManager());
}
}
// 每一个观察者都必须实现 LifecycleObserver 接口,它是一个空接口
class MySensorManager implements LifecycleObserver , SensorEventListener {
// 当被观察者切换到 ON_RESUME 状态时,就会调用下面的 onResume 方法
(Lifecycle.Event.ON_RESUME)
public void onResume() {
System.out.println("_______ onResume = " + this);
}
(Lifecycle.Event.ON_PAUSE)
public void onPause() {
System.out.println("_______ onPause = " + this);
}
}
class MyLocationManager implements LifecycleObserver , LocationListener {
(Lifecycle.Event.ON_RESUME)
public void onResume() {
System.out.println("_______ onResume = " + this);
}
(Lifecycle.Event.ON_PAUSE)
public void onPause() {
System.out.println("_______ onPause = " + this);
}
}
简单的说,如果你需要监听组件的生命周期方法,且需要在生命周期方法里编写大量的代码,那么就可以考虑将代码从组件中抽离,并配合 Lifecycle 来实现。
另外,可以通过下面的代码来获取“被观察者”当前的状态:1
lifecycle.getCurrentState().isAtLeast(Lifecycle.State.STARTED);
下图包含了构成 Activity 生命周期的状态和事件:

当然,你也可以自定义自己的“被观察者”,如果你想知道 Lifecycle 的更多用法,请阅读 《使用生命周期感知型组件处理生命周期》 。
小提示:
如果你想知道 Activity 是在何时回调 LifecycleObserver 接口里的方法的,请看 ReportFragment 类源码。
LiveData
在正式介绍 LiveData 的作用之前,我们先来看一个问题:
通过前面的介绍,我们知道 ViewModel 的生命比 Activity 和 Fragment要长,所以我们不应该在 ViewModel 中持有它们的引用。
但是通常 Activity 显示的数据都是从网络上获取的,这就存在一个异步的情况。
那么如果 ViewModel 不持有它们引用的话,当异步回来时, ViewModel 应该怎么更新界面?
答案很明显,就是“观察者模式”:ViewModel 持有的数据是“被观察者”,Activity 是“观察者”。
但是不能使用“传统的观察者模式”,“传统的观察者模式”只是屏蔽了具体类型,其依然存在强引用,依然会有内存泄漏的风险。
LiveData 是 Jetpack 为我们提供的“特殊的观察者模式”,它在“传统的观察者模式”基础上,提供了监听 Activity 生命周期的能力,当 Activity 被销毁(处于 DESTROYED 状态)时,会自动帮助我们断开链接。
范例1:使用 LiveData 。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46public class UserViewModel extends ViewModel {
// LiveData 是一个抽象类,通常我们会使用 MutableLiveData 类。
private MutableLiveData<User> user;
public UserViewModel() {
user = new MutableLiveData<>();
// 模拟异步请求
new Thread() {
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 由于当前是子线程中,所以使用 postValue 方法来更新,主线程的话可以使用 setValue 方法
user.postValue(new User("Cutler", 20));
}
}.start();
}
public LiveData<User> getUser() {
return user;
}
}
public class MainActivity extends AppCompatActivity {
private UserViewModel viewModel;
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
viewModel = new ViewModelProvider(this).get(UserViewModel.class);
final TextView textView = findViewById(R.id.textView);
// 调用 observe 方法注册监听
viewModel.getUser().observe(this, new Observer<User>() {
public void onChanged(User user) {
textView.setText(user.getName());
}
});
}
}
语句解释:
- 程序执行第 39 行代码后,MutableLiveData 就会监听当前 Activity 的生命周期,当 Activity 被切换到 Lifecycle.State.DESTROYED 状态时就会断开链接。
除此之外,LiveData 还有如下三个特点:
1、如果观察者的生命周期处于 STARTED 或 RESUMED 状态,则 LiveData 会认为该观察者处于活跃状态,LiveData 只会将更新通知给活跃的观察者。
2、观察者从非活跃状态更改为活跃状态时也会收到更新。
3、如果观察者第二次从非活跃状态更改为活跃状态,则只有在自上次变为活跃状态以来值发生了更改时,它才会收到更新。
如果你想知道 LiveData 的更多用法,请阅读 《LiveData 概览》 。
通过前面的介绍,我们已经可以搭建出 View 层 和 ViewModel 层的代码了,但是它们本身不负责生产数据,数据是由 Model 层生产的,因此本文后面的内容就来介绍一下如何设计 Model 层的代码。
在大多数情况下, Model 的职责有如下三个:
1、从服务器请求数据
2、读写缓存数据(内存、磁盘)
3、把从本地或者网络上拿到的数据返回给前端代码之前,对数据进行预处理。
为了实现这三个职责,我们会用到 OkHttp、Retrofit、RxJava、Room 四个开源库。
因此在继续向下之前,笔者打算先简单的介绍一下这四个类库,如果您已经会用了则可以跳过。
OkHttp
本节将通过提问的方式来介绍 OkHttp 库的相关基础知识。
1、为什么要用 OkHttp ?
在 Okhttp 库没出现之前,我们使用 HttpURLConnection 或者 HttpClient 进行网络请求,它们的特点是:
- HttpURLConnection 是轻量级的 HTTP 客户端,提供的API比较简单,如果你想执行文件的上传、下载等高级操作,需要自己去实现。
- HttpClient 的功能十分强大,可以方便的进行一些复杂的操作,但是它最初并不是为移动端设计的,且由于庞大的 API 数量使得 Google 很难在不破坏兼容性的情况下对它进行升级和扩展。
上面两个类库和 OkHttp 比起来就弱爆了,因为 OkHttp 不仅具有高效的请求效率,并且提供了很多开箱即用的网络疑难杂症解决方案:
- 支持HTTP/2,HTTP/2通过使用多路复用技术在一个单独的 TCP 连接上支持并发,通过在一个连接上一次性发送多个请求来发送或接收数据
- 如果HTTP/2不可用,连接池复用技术也可以极大减少延时
- 支持 GZIP,可以压缩下载体积,支持文件的上传和下载
- 响应缓存可以直接避免重复请求
- 会从很多常用的连接问题中自动恢复
- 如果您的服务器配置了多个IP地址,当第一个 IP 连接失败的时候,OkHttp 会自动尝试下一个 IP
- OkHttp 还处理了代理服务器问题和SSL握手失败问题
简单的说,你能遇到的和网络请求相关的问题,几乎在 OkHttp 中都能得到解决。
2、如何使用 OkHttp ?
下面笔者将通过几个简单的范例来介绍一下 OkHttp 的用法。
范例1:执行 Get 请求。1
2
3
4
5
6
7
8
9
10
11
12
13
14private void doRequest() {
// 首先创建一个 OkHttpClient 用来执行网络请求
OkHttpClient client = new OkHttpClient();
// 封装一个请求对象
Request request = new Request.Builder().url("http://www.baidu.com").build();
try {
// 在当前线程发起网络请求,然后返回请求结果
Response response = client.newCall(request).execute();
// 通过 response 对象可以获取响应码、响应头、相应内容等数据
System.out.println("___________ response " + response.code() + "," + response.body().string());
} catch (IOException e) {
e.printStackTrace();
}
}
语句解释:
- 通常我们只需要全局创建一个 OkHttpClient 对象即可,不需要每次请求的时候都创建一个。
- 请在子线程中执行上面的代码,因为从 Android 3.0 开始在主线程执行网络请求将会得到 NetworkOnMainThreadException 异常。
范例2:异步执行 Get 请求。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16private void doRequest() {
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder().url("http://www.baidu.com").build();
// 通过 enqueue 方法执行异步请求
client.newCall(request).enqueue(new Callback() {
public void onFailure(@NotNull Call call, @NotNull IOException e) {
}
public void onResponse(@NotNull Call call, @NotNull Response response) throws IOException {
System.out.println("___________ response " + response.code() + "," + response.body().string());
}
});
}
语句解释:
- 当请求成功后会在子线程中回调 onResponse 方法。
3、其它知识在哪学?
由于篇幅有限且 OkHttp 涉及到的知识比较多,笔者就不再继续了,如果你想知道 OkHttp 的更多用法,请参阅下面的链接:
《官方网站》 、《OkHttp使用完全教程》 、《Github - OkHttp》 、《Android OkHttp源码解析入门教程》
RxJava
本节将通过提问的方式来介绍 RxJava 库的相关基础知识。
1、 RxJava 到底是什么?
一个词:异步。它在 GitHub 主页上的自我介绍是:
RxJava – Reactive Extensions for the JVM – a library for composing asynchronous and event-based programs using observable sequences for the Java VM.
翻译:一个在 Java VM 上使用可观测的序列来组成异步的、基于事件的程序的库。
概括得非常精准,然而对于初学者来说,这太难看懂了,因为它是一个『总结』。
简单的说, RxJava 就是一个实现异步操作的库。
此时你可能会有一个问题:异步无非就是开个线程干点事,然后在切换回主线程,或者给控件设置的监听器也可以算是异步操作,但这有什么难的,这点破事还用单独写一个开源库?
其实 RxJava 这个库有两个最明显的特点,它可以让你在执行异步请求时:
1、方便的进行线程切换。
2、方便的执行复杂的、多层次的异步操作。
也就是说,有的人用 RxJava 是看中了它第一个特点,有的人则是看中了第二个。
当项目的业务逻辑足够复杂的时候,可能会需要同时发起多个异步操作、甚至存在嵌套的异步操作,考虑到异步操作在时间上地不确定性,此时再自己处理异步的话,先不说需要自己处理线程切换、 AsyncTask 的版本兼容性等问题,光是随之而来的复杂性就不容忽视了,比如若需求是等所有异步都返回的时候,再对结果统一处理,程序员就需要提供一些额外的逻辑来判断异步操作何时结束以及后续的操作何时开始。
2、为什么还听说过 RxSwitf ?
RxJava 其实是 ReactiveX 的一个具体实现, ReactiveX 是 Reactive Extensions 的缩写,一般简写为 Rx 。
Rx由微软的架构师Erik Meijer领导的团队开发一个项目,它主要是用来帮助开发者更方便的处理异步,事实上Rx只定义了一套编程接口。
既然定义接口,那它就得有具体的实现,事实也确实如此,它在很多语言平台上都有自己的实现。
截止至2020年3月份,从Rx官网上可以看到,Rx库支持.NET、js、java、swift、c++等18种语言,Rx的大部分语言由ReactiveX这个组织维护。
我们上面说的 RxJava 就是 ReactiveX 在 JVM 上的一个实现,帮助我们更方便的处理复杂异步。
3、 RxAndroid又是什么 ?
ReactiveX 这个组织针对 Android 平台还提供了一个适配库,名为 RxAndroid ,这个库是在 RxJava 基础上编写的,它的源码一共也没多少,就是针对Android平台上线程切换等事情做了些适配。
另外,由于在 RxAndroid 的内部就引用的 RxJava 库,所以我们只需要在项目里引用 RxAndroid 库就可以了。
基础用法
本质上来说 RxJava 是基于观察者模式的,在继续往下学习之前,关于这个模式的定义咱们需要先达成共识:
第一,常见的观察者模式里,被观察者内部持有一个观察者者列表,当数据变化时,被观察者会遍历列表,依次通知每一个观察者。
第二,在更广义的观察者模式中,被观察者的内部可以不持有一个观察者列表,而只持有一个观察者的引用,比如我们经常调用 setOnClickListener 方法给 Button 设置回调函数,这个操作也可以理解为观察者模式。
事实上 RxJava 就是基于广义的观察者模式,它创建的被观察者的内部并没有维护一个观察者列表。
范例1:HelloWorld。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41// Observable 类表示被观察者,它的 create 方法用来创建一个被观察者对象。
// ObservableOnSubscribe 是一个回调接口,当有新的观察者绑定到 Observable 上时,就会回调它的 subscribe 方法。
Observable<String> observable = Observable.create(new ObservableOnSubscribe<String>() {
// 我们通常在此方法中执行异步任务。
// ObservableEmitter 类被称为发射器,在执行异步任务时,我们可以通过它来通知观察者当前任务的执行状态。
// 比如:进度更新、发生错误、顺利完成等。
public void subscribe(ObservableEmitter<String> emitter) throws Exception {
System.out.println("__________________ 有新观察者链接进来了 " + this);
}
});
// Observer 接口用来表示观察者。
Observer<String> observer = new Observer<String>() {
// 当观察者与被观察者建立完毕链接时调用此方法,先调用此方法再调用 subscribe 方法。
public void onSubscribe(Disposable d) {
System.out.println("__________________ 订阅成功 " + this);
}
// 当被观察者通过 ObservableEmitter 发送 onNext 事件时,回调此方法。
public void onNext(String s) {
// 这里接收被观察者发出的事件
System.out.println("__________________ 接到新事件 " + this + "," + s);
}
// 当被观察者通过 ObservableEmitter 发送 onError 事件时,回调此方法。
public void onError(Throwable e) {
System.out.println("__________________ onError " + this);
}
// 当被观察者通过 ObservableEmitter 发送 onComplete 事件时,回调此方法。
public void onComplete() {
System.out.println("__________________ onComplete " + this);
}
};
// 让观察者和被观察者建立链接
observable.subscribe(observer);
语句解释:
- Observable 表示被观察者, Observer 表示观察者。
- 我们在 ObservableOnSubscribe 的 subscribe 方法里执行异步操作,并通过 ObservableEmitter 类来与观察者进行沟通。
线程控制
在不指定线程的情况下, RxJava 遵循的是线程不变的原则,即:在哪个线程调用 subscribe(),就在哪个线程生产事件;在哪个线程生产事件,就在哪个线程消费事件,如果需要切换线程,就需要用到 Scheduler(调度器)。
RxJava 已经内置了几个 Scheduler ,它们已经适合大多数的使用场景:
| 代码 | 含义 | 使用场景 |
|---|---|---|
| Schedulers.io() | IO操作线程 | 读写SD卡文件、查询数据库、访问网络等IO密集型等操作 |
| Schedulers.computation() | CPU计算操作线程 | 图片压缩取样、xml、json解析等CPU密集型计算 |
| Schedulers.newThread() | 创建新线程 | 总是启用新线程,并在新线程执行操作 |
| AndroidSchedulers.mainThread() | Android主线程 | 更新UI |
范例1:线程切换方法。1
2
3
4
5
6// 设置被观察者所在的线程,即 ObservableOnSubscribe 的 subscribe 方法应该在哪个线程被调用。
// 如果多次调用此方法,只有第一次有效。
.subscribeOn(Schedulers.io())
// 设置此行代码之后设置的回调,应该在哪个线程中被调用。
// 此方法可以多次调用,调用后就会对后续接收回调的函数生效,具体请看范例2。
.observeOn(AndroidSchedulers.mainThread())
语句解释:
- 需要注意的是,Observer 的 onSubscribe 方法不会受 observeOn 的控制。
- 通过测试发现,你在哪个线程注册观察者, onSubscribe 方法就会在哪个线程被调用。
范例2:线程切换与监听事件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46// 创建一个被观察者
Observable.create(new ObservableOnSubscribe<String>() {
public void subscribe(ObservableEmitter<String> emitter) throws Exception {
// 当前方法会在子线程中被调用
String result = getDataFromNetwork();
// 通过 emitter 对象去调用观察者的 onNext 方法
emitter.onNext(result);
}
})
// 设置被观察者在子线程中执行异步操作
.subscribeOn(Schedulers.io())
// 设置此行代码之后的回调函数在 IO 子线程中执行
.observeOn(Schedulers.io())
// 监听 onNext 事件,在调用 onNext 方法之前会调用 doOnNext 设置的回调
.doOnNext(new Consumer<String>() {
public void accept(String s) throws Exception {
// 在 IO 子线程中调用
System.out.println("__________________ accept 1 " + Thread.currentThread().getName());
}
})
// 设置此行代码之后的回调函数在 computation 子线程中执行
.observeOn(Schedulers.computation())
// 再次设置监听
.doOnNext(new Consumer<String>() {
public void accept(String s) throws Exception {
// 在 computation 子线程中执行
System.out.println("__________________ accept 2 " + Thread.currentThread().getName());
}
})
// 设置此行代码之后的回调函数在主线程中执行
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new MyObserver<String>() {
public void onNext(String s) {
// 在主线程中执行
System.out.println("__________________ 1 onNext " + Thread.currentThread().getName());
}
});
// 程序最终输出:
// __________________ accept 1 RxCachedThreadScheduler-2
// __________________ accept 2 RxComputationThreadPool-1
// __________________ 1 onNext main
语句解释:
- 为了让代码简洁我定义了一个 MyObserver 类,它仅仅是继承了 Observer ,其它什么都没做。
- 设置 doOnNext 监听,通常是为了对被观察者返回的数据进行二次处理,然后将处理过的数据返回给观察者。
- 除了 doOnNext 外,还可以使用 doOnComplete 、 doOnError 等方法。
本节参考阅读:
- 抛物线 - 给 Android 开发者的 RxJava 详解
- Rx概述(RxJava2)
- 极客学院 - ReactiveX
- reactivex.io
- LINQ教程一:LINQ简介
- 所以什么是LINQ
- RxJava 1.x 和 RxJava 2.x 的异同
- RxJava 1.x 和 RxJava 2.x 的异同
- RxJava1 升级到 RxJava2 所踩过的坑
- 这可能是最好的RxJava 2.x 教程(完结版)
- RxJava 从入门到放弃再到不离不弃
- 关于RxJava最友好的文章
- RxJava2入门教程一
- Rxjava2入门教程五:Flowable背压支持——对Flowable最全面而详细的讲解
Retrofit
在 Android 平台中,Retrofit 是当下最热的一个网络请求库。
更准确的说,Retrofit 是对 OkHttp 的二次封装,网络请求的工作本质上仍然是 OkHttp 完成。如下图所示:

1、为什么要用 Retrofit ?
虽然 OkHttp 已经很方便、强大了,但是使用 Retrofit 可以进一步的方便我们进行网络请求。
1、通过接口的封装,方便我们管理 App 内的所有请求。
2、通过对第三方库(rxjava、gson)的支持,可以方便我们发起请求和解析返回值。
2、如何使用 Retrofit ?
使用 Retrofit 的步骤共有如下 7 个:
步骤1:添加 Retrofit 相关的依赖库
步骤2:创建 JavaBean 类
步骤3:创建 用于描述网络请求 的接口
步骤4:创建 Retrofit 实例
步骤5:创建 网络请求接口实例 并 配置网络请求参数
步骤6:发送网络请求(异步 / 同步)
范例1:添加依赖。1
2
3
4
5
6
7
8
9
10// 引入 rxjava 和 okhttp
implementation 'io.reactivex.rxjava2:rxandroid:2.0.2'
implementation("com.squareup.okhttp3:okhttp:4.4.0")
// 引入 retrofit
implementation("com.squareup.retrofit2:retrofit:2.8.1")
// 引入 retrofit 对 gson 和 rxjava 的适配器
implementation 'com.squareup.retrofit2:converter-gson:2.8.1'
implementation 'com.squareup.retrofit2:adapter-rxjava2:2.8.1'
接下来我们以网易有道翻译的接口为例,介绍如何使用 retrofit 进行网络请求。
这是我们的测试接口:
范例2:创建 JavaBean 类。1
2
3
4
5
6
7
8
9
10
11
12
13
14public class TranslationText {
// 翻译的译文
private List<String> translation;
// 翻译的原文
private String query;
public List<String> getTranslation() {
return translation;
}
public String getQuery() {
return query;
}
}
范例3:创建 用于描述网络请求 的接口。1
2
3
4public interface YouDaoApi {
("openapi.do?keyfrom=Yanzhikai&type=data&doctype=json&version=1.1&key=2032414398")
Observable<TranslationText> toTranslation(@Query("q") String q);
}
语句解释:
- @GET注解表示执行get请求,相应的还有POST、PUT等注解,注解内的值是相对路径。
- @Query注解表示请求参数,最终会以“&参数名=参数值”的形式附加到URL后面。
范例4:执行网络请求。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 1、创建 Retrofit 对象
Retrofit retrofit = new Retrofit.Builder()
// 设置网络请求的 host 地址
.baseUrl("http://fanyi.youdao.com/")
// 设置数据解析器为Gson,即当接口返回时, Retrofit 会自动使用 Gson 来将 json 转换成 JavaBean 对象
.addConverterFactory(GsonConverterFactory.create())
// 设置请求适配器,让 Retrofit 通过 RxJava 处理异步
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.build();
// 2、执行网络请求
retrofit
// 创建对应的接口对象
.create(YouDaoApi.class)
// 调用接口的 toTranslation 方法
.toTranslation("car")
.subscribeOn(Schedulers.computation())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new MyObserver<TranslationText>() {
public void onNext(TranslationText translationText) {
System.out.println("___________ " + translationText.getQuery() + " = " + translationText.getTranslation());
}
});
// 程序最终输出:
// ___________ car = [小汽车]
语句解释:
- 默认情况下 Retrofit 内部会自己创建一个 OkHttpClient 对象,当然你可以传递给它一个对象。
- 因此整个进程中只需要一个 Retrofit 对象就可以了。
由于篇幅有限,笔者就不再继续了,如果你想知道 Retrofit 的更多用法,请参阅:《这是一份很详细的 Retrofit 2.0 使用教程(含实例讲解)》
Room
Android 采用 SQLite 作为数据库存储,但 SQLite 提供的 API 很强大也很低级,使用起来麻烦且容易出错,所以开源社区里出现了各种 ORM(Object Relational Mapping )库,常见的有 ORMLite ,GreenDAO 等。
而 Room 数据库就是 Google 做的,本质上来说 Room 是在 SQLite 上提供了一层抽象。
在 Room 中有三个主要的组件,如下图所示:
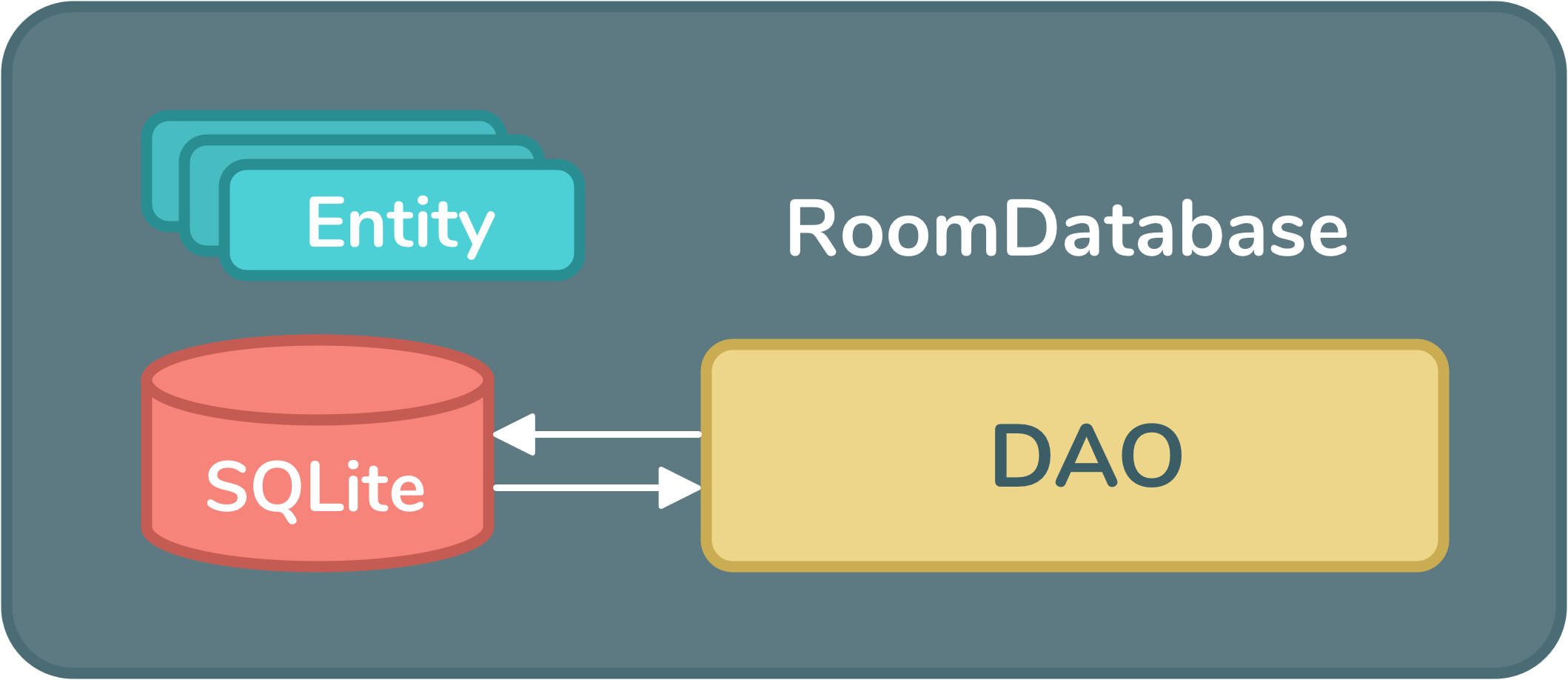
Entity:这是一个 Model 类,对应于数据库中的一张表。Entity 类是 SQLite 表结构在 Java 中的映射。
DAO(Data Access Objects,数据访问对象):负责定义访问数据库的方法,我们可以通过它来访问数据。
RoomDatabase:数据库管理类,通常让它来负责创建数据库、管理各个 DAO 、处理数据库升级等任务,它也是 App 层访问数据库的主要入口类。
范例1:创建实体类 —— User 。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 如果一个类需要写入到数据库中,那么需要在此处加一个 @Entity 的注解
public class User {
// 每一个实体类都需要一个唯一的标识即主键,使用 @PrimaryKey 注解
// 下面将主键设置为自增长,默认false
(autoGenerate = true)
private int uid;
// 默认情况下会用属性名作为表的列名,但是可以通过 @ColumnInfo 注解修改
(name = "name")
private String name;
private int age;
// 使用 @Ignore 注解可以让其修饰的字段不加入数据表中
private String sex;
// 此处省略各个属性的 get 、set 方法,如果将属性设置成 public 的则不需要 get 、 set
}
语句解释:
- 除了上面介绍的知识,你还可以修改表名、建立唯一键、外键、索引。
范例2:创建 Dao 类 —— UserDao 。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// 此处需要使用 @Dao 注解定义一个接口
public interface UserDao {
/**
* 查询所有数据
*/
("Select * from user")
List<User> getAll();
/**
* 依据 uid 从数据库中查找出一个 User 对象
*/
("SELECT * FROM user WHERE uid = :uid")
User findById(String uid);
/**
* 一次插入单条数据 或 多条,如果发生了冲突,则用新数据取代旧数据
*/
(onConflict = OnConflictStrategy.REPLACE)
void insert(User... users);
/**
* 一次删除单条数据 或 多条
*/
void delete(User... users);
/**
* 一次更新单条数据 或 多条
*/
void update(User... users);
}
语句解释:
- 我们不需要去实现这个接口, Room 会自动依据方法上的 SQL 语句(如果你写了的话)帮我们生成实现类 UserDao_Impl 。
范例3:创建 RoomDatabase 类 —— MyRoomDatabase 。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 使用 @Database 注解定义一个统一对外的数据库管理类,此类需要是抽象类
// 参数 entities 用来指出数据库中的表对应的 Java 类
// 参数 version 用来指出当前数据库的版本号
(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
public abstract UserDao getUserDao();
private static MyDatabase appDataBase;
public static MyDatabase getInstance(Context context) {
if (appDataBase == null) {
synchronized (MyDatabase.class) {
if (appDataBase == null) {
// 通过此方法来创建 MyDatabase 对象即可,第三个参数是数据库的名称。
appDataBase = Room.databaseBuilder(context, MyDatabase.class, "myDatabase.db")
// 设置允许在主线程操作数据库,默认情况下是不需要
.allowMainThreadQueries()
.build();
}
}
}
return appDataBase;
}
}
语句解释:
- 我们同样不需要事先 MyDatabase 类, Room 会自动生成一个实现类 MyDatabase_Impl 。
范例4:前端代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class MainActivity extends AppCompatActivity {
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 通过查看 MyDatabase_Impl 源码可以知道,此处获取的 UserDao 是一个单例对象
UserDao userDao = MyDatabase.getInstance(getApplicationContext()).getUserDao();
userDao.insert(new User("Cutler", 20));
userDao.insert(new User("Fucker", 18));
System.out.println("__________________ "+userDao.getAll().size());
}
}
语句解释:
- 默认情况下,系统会在 data/data/package/databases 中生成数据库文件,共包含如下三个文件:
- myDatabase.db
- myDatabase.db-shm
- myDatabase.db-wal
- 您如果想查看数据库里的内容,则必须将这3个文件导出到同一目录中,然后打开 myDatabase.db 即可。
当升级 Android 应用的时候,有时需要更改数据库中表的结构(添加、删除列),但是不能直接在 Entity 对象上删除,而应该使用数据库提供的 Migration 类。
范例5:数据库升级 —— 四步法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// 1、修改 User 类
public class User {
// …… 上面省略其它代码
public String sex;
}
// 2、将数据库的版本号从 1 升级到 2
(entities = {User.class}, version = 2)
public abstract class MyDatabase extends RoomDatabase {
// 3、创建一个Migration 类,每个对象包含数据库的开始版本号和结束版本号
static final Migration MIGRATION_1_2 = new Migration(1, 2) {
public void migrate(SupportSQLiteDatabase database) {
database.execSQL("ALTER TABLE user ADD COLUMN sex TEXT");
}
};
public static MyDatabase getInstance(Context context) {
if (appDataBase == null) {
synchronized (MyDatabase.class) {
if (appDataBase == null) {
appDataBase = Room.databaseBuilder(context, MyDatabase.class, "myDatabase.db")
.allowMainThreadQueries()
// 4、设置 Migrations
.addMigrations(MIGRATION_1_2)
.build();
}
}
}
return appDataBase;
}
}
语句解释:
- 需要注意的是,使用 fallbackToDestructiveMigration() 会清空数据库里的所有数据。
另外,我们可以让 LiveData 与 Room 配合使用。
范例6:实时监听数据库变化。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38// 1、创建一个 UserDao 类
public interface UserDao {
// 注意此方法的返回类型是 LiveData 的,Room 最终会创建一个 RoomTrackingLiveData 类对象。
("SELECT * FROM user WHERE uid=:uid")
LiveData<User> findById(int uid);
(onConflict = OnConflictStrategy.REPLACE)
void insert(User... users);
}
public class MainActivity extends AppCompatActivity {
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
UserDao userDao = MyDatabase.getInstance(getApplicationContext()).getUserDao();
int uid = 10;
// 往数据库插入数据,如果已经存在则执行替换
userDao.insert(new User(uid, "Cutler ", 20));
// 通过查看源码可以发现,我们无法通过调用 RoomTrackingLiveData 的 getValue() 方法获取数据。
// 只能通过 observer 方法设置监听。
userDao.findById(uid).observe(this, new Observer<User>() {
public void onChanged(User user) {
System.out.println("__________________ " + user);
}
});
}
// 当界面中的按钮被点击时会调用此方法
public void onClick(View view) {
UserDao userDao = MyDatabase.getInstance(getApplicationContext()).getUserDao();
int uid = 10;
// 更新用户的名称
userDao.insert(new User(uid, "Fucker ", 20));
}
}
语句解释:
- 程序执行第 36 行代码后,我们就会在第 27 行接受到数据改变的通知。
由于篇幅有限,笔者就不再继续了,如果你想知道 Room 的更多用法,请自行搜索。
本节参考阅读:
DataBinding
数据绑定(DataBinding)可以将你的数据(Model对象)与UI界面进行绑定,从而省去了很多更新 UI 的模板代码。简单的说,数据绑定可以帮你做到:
1、省去 findViewById 的调用。
2、省去 setXxxListener 的调用,比如当用户点击 UI 控件时,可以将事件转调用给相应的 ViewModel 。
3、省去数据更新时手动更新 UI 的操作,比如当 ViewModel 的数据发生变化的时候,可以自动更新 UI 控件。
关于 DataBinding 库 Google 提供了详细的中文教程,且非常容易学习上手,因此本节只会介绍其部分功能,想要完整的学习,请阅读 《DataBinding》 。
范例1:HelloWorld。
第一步,创建一个布局文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<?xml version="1.0" encoding="utf-8"?>
<layout xmlns:android="http://schemas.android.com/apk/res/android">
<data>
<variable name="viewModel" type="com.meevii.myapplication.viewmodel.MainViewModel" />
</data>
<LinearLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical">
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@{viewModel.data.name}"
android:textColor="@android:color/black" />
</LinearLayout>
</layout>
语句解释:
- 根节点必须是 layout ,布局文件中包含一个 data 标签,用来声明当前布局所用到的对象。
- 在数据绑定中对变量的引用要通过“@{}”来实现。
- 上面的代码中创建了一个 TextView ,它的文本是 viewModel.getData.getName 方法的返回值。
第二步,在 MainActivity 中初始化布局。1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MainActivity extends AppCompatActivity {
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// 第一种加载方式:
// ActivityMainBinding binding = ActivityMainBinding.inflate(getLayoutInflater());
// setContentView(binding.getRoot());
// 第二种加载方式:
ActivityMainBinding binding = DataBindingUtil.setContentView(this, R.layout.activity_main);
binding.setLifecycleOwner(this);
binding.setViewModel(new ViewModelProvider(this).get(MainViewModel.class));
}
}
语句解释:
- 默认情况下, DataBinding 库会依据布局文件的名称自动生成一个类,比如上面的 ActivityMainBinding 。
- 加载完毕布局之后,需要创建一个 MainViewModel 对象,注入到 XML 文件中,实现数据绑定。
第三步,创建 MainViewModel 类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public class MainViewModel extends ViewModel {
// 注意本属性是 LiveData 类型的
private MutableLiveData<User> data;
public MainViewModel() {
data = new MutableLiveData<>();
doRequestUserInfoForNetwork();
}
private void doRequestUserInfoForNetwork() {
// 使用 RxJava 来模拟一下网络请求
Observable.create((ObservableOnSubscribe<User>) emitter -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
emitter.onNext(new User(10, "Fucker", 200));
}).subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new MyObserver<User>() {
public void onNext(User user) {
data.setValue(user);
}
});
}
public MutableLiveData<User> getData() {
return data;
}
}
语句解释:
- 由于数据绑定对 LiveData 做了兼容,所以当成功执行第 25 行代码时, TextView 会立刻更新文本。
- 需要注意的是,本范例只是为了演示 DataBinding 的用法,正确的网络请求应该放到 Model 层里,而不是放到 ViewModel 中。
当然,数据绑定的功能肯定不止于此,比如你可以在XML中写出如下表达式:1
2
3
4<TextView
android:text="@{String.valueOf(index + 1)}"
android:visibility="@{age > 13 ? View.GONE : View.VISIBLE}"
android:transitionName='@{"image_" + id}'/>
语句解释:
- 需要注意的是,通常 TextView 的 text 属性接收的是一个字符串类型,所以这里需要把数字使用 String.valueOf 方法转换一下。
如果你想知道更多的 XML 语法,请阅读 《布局和绑定表达式》 。
小结
至此算是介绍完了 MVVM 所需要涉及到的所有库,其实大家可以看出来,笔者对每一个库的介绍都是浅尝辄止,因为只是想告诉大家它们是什么,至于它们的高级用法网上的教程一大堆,不需要笔者在这里吆五和六。
现在再稍微总结一下它们所处的模块:
前端代码:DataBinding、ViewModel、LiveData、Lifecycle
网络请求:OkHttp、Retrofit、RxJava
数据库:Room 、LiveData、RxJava
最后留下一个练习题,题目的要求为:
1、程序从 MainActivity 中跳转到一个新界面 UserDetailsActivity 。
2、新界面需要接收一个参数“ id ”,它依据“ id ”去查询并显示对应的用户信息。
由于篇幅有限,笔者就不提供源码了,下面是笔者画的类图,希望对大家有帮助。
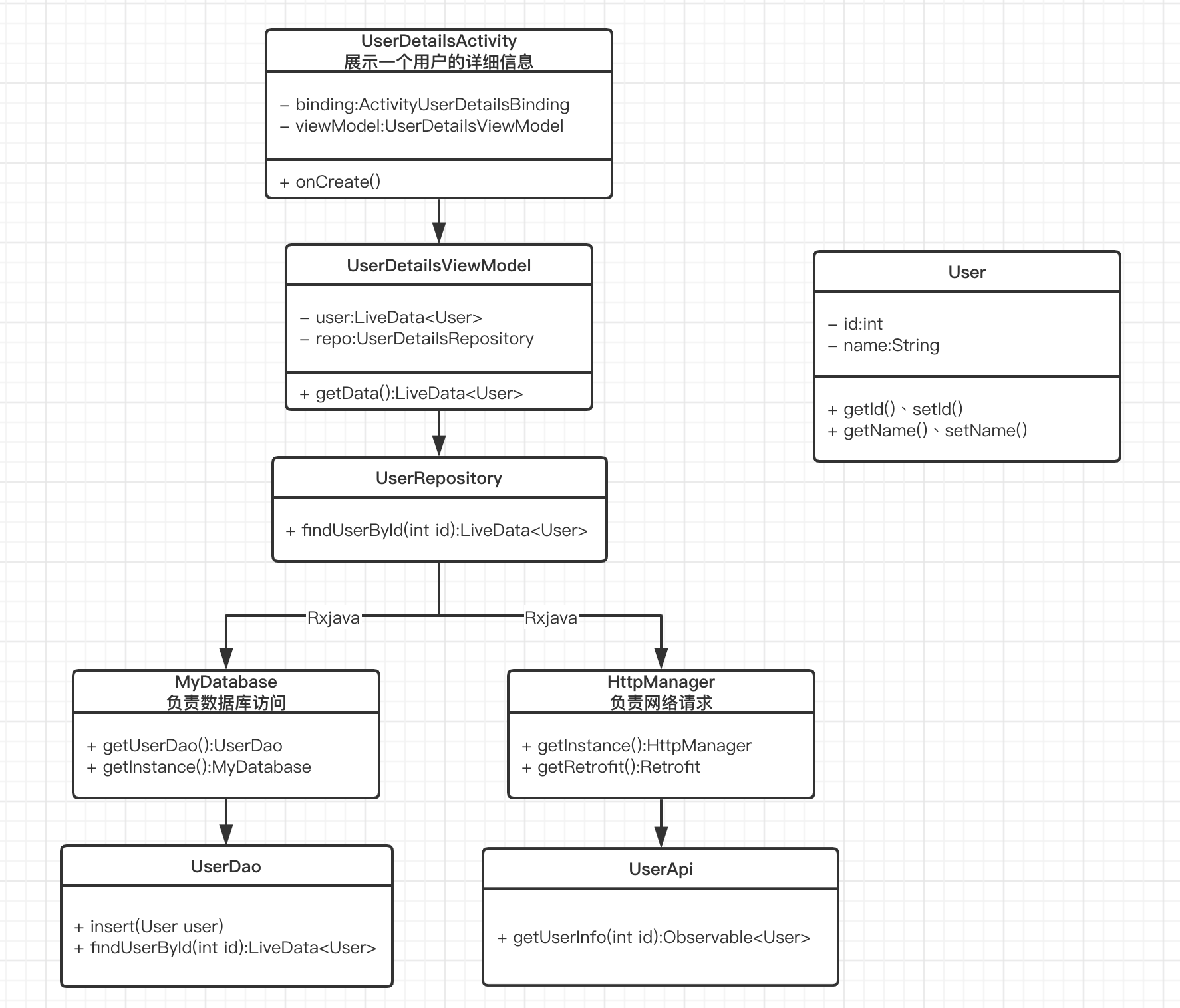
最后笔者需要说一句:要时刻警惕过渡架构!
一个项目通常有多个模块,不是所有模块都适合 MVVM 架构的,比如“设置”模块,我们没必要把简单的问题复杂化。