基础入门
语言概述
Java的3个开发平台: JavaSE、JavaEE、JavaME。
JavaSE(Java标准版),是J2EE和J2ME的基础,本章就是介绍的J2SE。
JavaEE(Java企业版),是面向企业开发的。
JavaME(Java微型版),是面向小型机、等终端设备开发的(如早年的手机游戏等)。
其中Java SE可分为4部分:JVM、JRE、JDK、Java语言。
JVM:Java程序必要使用JVM(Java虚拟机)来解释执行。
JRE(Java Runtime Environment): Java运行环境。如果您只运行Java程序,而不开发程序,则可以只安装JRE,JVM被包括在JRE中。
JDK (Java Development kit):Java开发工具包。如过您打算开发(编译)Java程序,则需要JDK,而且JDK中包含了JRE和其他一些开发过程中可能使用的工具。
Java语言:Java语言只占了J2SE的一部分,除了语言之外Java最重要的就是它提供的功能强大的API类库、数据IO、网络组件等功能。
高级语言
计算机语言的种类非常的多,总的来说可以分成机器语言,汇编语言,高级语言三大类。关于高级程序语言的定义,在上一章“C语言”中已经介绍过了,此处不再冗述。
高级程序语言分为: 编译型语言和解释型语言。
高级程序语言有:C、C++、C#、Java、Python等。
高级程序语言所写的代码被称为“源程序”,但是计算机不能直接识别源程序代码,因此必须将源程序代码翻译成机械语言(0,1代码),只有这样咱们写的代码才能被计算机执行。由此根据将源程序翻译成机器语言的方式将高级语言划分为:编译型语言和解释型语言。
编译型语言
编译器根据当前计算机的配置(如CPU的指令集、操作系统的类型等),将源程序文件一次性编译成当前计算机系统能识别的机器语言,然后再交给CPU去执行,C语言就是编译型语言。
优点: 程序执行速度快。
缺点: 由于编译生成的直接是机器语言(0、1代码),具有与平台有关性,如果程序换到了另一个计算机系统中则就无法执行,且编译速度相对与解释型语言来说要慢一些。
注:直接将源程序转换成机器语言比转换成中间代码耗时要长。
解释型语言
解释器先将源程序翻译成一个中间代码,当程序运行时由解释器解释这个中间代码,解释器每翻译一句,就交给CPU执行一句,Java语言就是解释型语言。
优点: 由于解释器生成的是与平台无关的中间码,执行这些中间代码需要特定解释器,因此只需要根据不同的计算机系统设计相应的解释器,就可以在不改源程序的前提下,使程序跨平台运行。
缺点: 程序执行的速度比编译型语言慢。
注:也有的解释器可以直接执行源程序,当然在这之前同样会进行必要的词法、语法分析。
Java程序从编写到执行会经历如下步骤:
编译程序:使用
JDK提供的“javac”工具可以将源程序文件(.java文件)编译成与平台无关的字节码文件(.class文件)。
运行程序:使用JDK提供的“java”工具,可以将.class文件装入JVM里,由JVM解释执行,使用“java 类名”执行程序。
也就是说Java程序是运行在JVM之上的,JVM才是运行在操作系统上的,另外以Windows为例,每个Java程序执行时都会在操作系统中开一个java.exe的进程,它就是JVM。
编程基础
环境变量
PATH变量
PATH变量是Windows系统用来寻找可执行程序(.exe)的一个环境变量。
若不人为的去设置,则当我们在命令号中输入命令时,Windows默认去C:/windows/system32文件夹下去寻找可执行程序。PATH本质上是一个字符串,其中可以指定多个路径,路径间用分号(;)间隔,在操作系统查找某个可执行程序时,系统会依次查找PATH内的每一个路径。
在JAVA中设置此变量主要为了指明javac.exe和java.exe等程序所在位置,因为JAVA程序的编译和运行就需要这两个程序。
ClassPath变量
类路径,顾名思义是
JVM查找“类”时要使用的变量,一般来说至少要写上一个“.” 代表当前目录,多个路径间同样用分号(;)间隔。当处在如下三种情况时说明此时
JVM是在找类:
1、当程序中出现import语句导入类时。
2、程序中声明了一个未导入的类的对象时。
3、使用java执行某个类的时候,JVM会去ClassPath变量指定的路径上去找这个类。
通用常识
范例1:Hello World。1
2
3
4
5
6
7
8
9
10
11
12
13
14// 每个源程序最多只能有一条package语句,且必须是源程序的第一条非注释语句。
package com.cutler;
// 一个.java文件中只能有一个public修饰类,可以有多个不被public修饰的类。
// 被public修饰的类,类名必须和.java文件的文件名相同。
// 一个.java文件中可以有多个类定义,相应的编译后会产生多个.class文件。
// 执行java程序时,执行的是具有main方法的类。
public class Test {
public static void main(String[] args) {
//输出数据 但不会换行。
System.out.print("ABC");
//输出数据 并且换行。 此方法可以不输出任何数据 单独当作换行使用。
System.out.println("Hello World!");
}
}
范例2:标识符命名规范。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 所谓的标识符,说白了就是指程序中:变量、方法、类、接口等对象的名称。
// 标识符名称必须由“大小写字母”、“下划线”、“数字”、“$”符号组成 且不能以数字开头。
// 最好也别用$符号开头,因为匿名内部类的名称前会有一个$符号应尽量避免混淆,可以有中文。
// Java中标识符区分大小写。变量a和变量A是不同的两个变量。
// 标识符不能使用Java保留字。
/*
通常我们会按照如下规范来命名:
包名:全部用小写字母。
类名:各单词首字母大写。
局部变量名:全小写
成员变量名:第一个单词首字母小写,其他单词首字母大写。
方法名:第一个单词首字母小写,其他单词首字母大写。
常量名:全部大写,每个单词之间用“_”连接。
接口名:各单词首字母大写,在接口名前加一个大写字母“I”。
*/
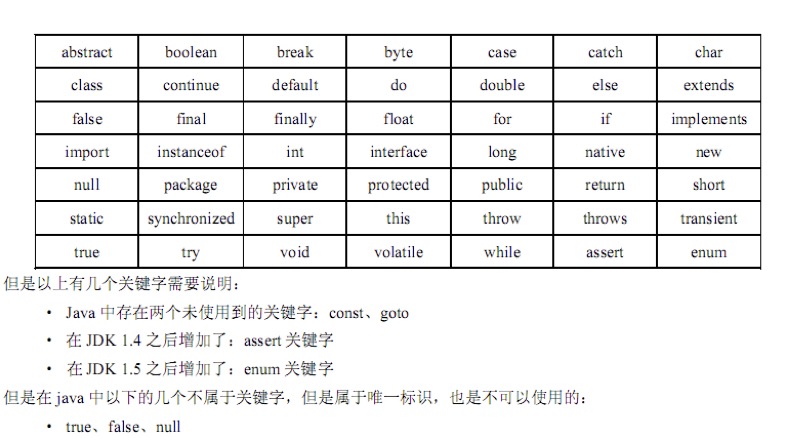
范例3:保留字。
保留字又称为关键字,说白了保留字就是Java系统专用的标识符,用户无权使用。
运算符
范例1:运算符划分。1
2
3
4
5
6算术运算符:+ - * / % ++ --
关系运算符:> < >= <= == !=
赋值运算符:= += -= *= /= %= ^= &= |= <<= >>= >>>=
逻辑运算符:&& || ! & |
位运算符: ! & | >> << >>>
条件运算符:? :
范例2:逻辑运算。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 逻辑运算包含:与运算、或运算、非运算。
// 与运算
// 简洁与运算:“a&&b”,如果a为false则不再判断b,表达式的值自动为false。
// 全部与运算:“a&b”, 如果a为false则同样去判断b。
// 或运算
// 简洁或运算:“a||b”,如果a为true则不再判断b,表达式的值自动为true。
// 全部或运算:“a|b”, 如果a为true则同样去判断b。
// 非运算
// 非运算“!a”,如果a为true则表达式的值为false,反过来一样。
public class LogicCalc {
public static void main(String[] args) {
int a = 3,b = 4;
if(a++ > 0 || b++ > 0){
System.out.println("a="+a+" b="+b);
}
}
}
语句解释:
- 此时程序输出:a=4 b=4。若是把“||”换成“|”,则程序输出:a=4 b=5。
范例3:位运算。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 所谓的位运算,其实就是移位。
// 是将一个数字的二进制表示形式,整体(向左或向右)移动若干位。
// 如数字1的二进制为:00000001,左移移1位后为00000010。
// 其中位串“00000001”中,左边称为高位,右边称为低位。
// 移位时所遵循的规则为:
// 左移:最高位直接被舍弃,最低位补0。
// 右移:又分为有符号右移和无符号右移。
// 有符号右移:正常情况下每右移一位数据会缩小2倍,最低位直接被舍弃,移位之前最高位为1则移位之后最高位补1,为0则补0。
// 无符号右移:正常情况下每右移一位数据会缩小2倍,最低位直接被舍弃,左端补0。
// 左移、右移都是针对数值的“补码”来说的,关于“补码”的概念,在其它笔者的博文中会介绍。
// 有符号右移运算符(>>)、无符号右移运算符(>>>)、左移运算符(<<)。
// 或运算符(|):2个数有一个为1,结果就为1,否则为0。
// 与运算符(&):2个数同为1,结果才为1,否则为0。
// 取反运算符(~):将0改成1,将1改成0。
// 异或运算符(^):2个数相同则为0,不同则为1。
数据类型
范例1:数据类型的划分。1
2
3
4
5
6
7
8
9// 1、基本数据类型(共8种)。
// 2、复合数据类型:数组、接口、类。
// 3、空类型:void。
// 8种基本数据类型为:
// 数值类型:
// byte(1字节)、short(2字节)、int(4字节)、long(8字节)、float(4字节)、double(8字节)
// 字符类型:char(2字节)
// 布尔类型:boolean(1字节),取值:true、false
语句解释:
- 复合类型成员变量默认值为null,局部变量没有默认值。
范例2:变量与常量。1
2
3
4
5
6
7
8
9
10
11
12// 变量:程序中值可以改变的量,又分为:
// 局部变量:程序中一对“{}”被称为一个块,局部变量隶属于某一个“块”当程序流程走出这个“块”时,局部变量就消失了。
// 成员变量:成员变量隶属于对象,对象建立时成员变量诞生,对象消失时成员变量死亡。
// 常量:程序中值不可以改变的量,又分为:
// 字面常量:如1、’c’、2342f、”String”、false等。
// 符号常量:final double PI=3.14。
// 关于局部变量还需要知道的是:
// (1)必须要先赋值后使用,否则通不过编译,局部变量没有默认初始化值。
// (2)作用范围:定义开始到定义它所在的代码块结束。
// (3)同一范围内,不允许2个局部变量命名冲突。
范例3:整型数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 整型数据分为:整型常量和整型变量。
// 整型常量有三种表示方法:
// 十进制表示法:如1、23、-5。
// 八进制表示法:以数字0开头,随后的数不能大于7,如01、023、-05等。
// 十六进制表示法:以0x开头,随后的数不能大于F(A代表10,F代表15),如-0x12。
// 整型变量有byte、int、short、long四种:
// 字节整型(byte):变量所能保存的值的取值范围:-128~127。
// 短整型(short):取值范围:-32768~32767。
// 基本整型(int):取值范围:-2147483648~2147483647,默认用十进制表示数字。
// 如“int i=0xF;”,此时输出i,结果为15 。
// 长整型(long):取值范围:很大很大很大。
// 需要注意的是:
// 整数型成员变量默认值0,整型的局部变量没有默认值,必须手工赋值。
// long型常量之后跟一个“L”或者“l”,如:12L。
范例3:实型数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 实型数据(实数)又称为浮点数,分为:实型常量和实型变量。
// 实型常量有两种表示方法:
// 十进制小数形式:由数字和小数点组成(注意必须要有小数点,但小数点之后,可以没有内容),如 1.2f、2.3、-5.等都是十进制小数形式
// 指数形式:12E3或者12e3都是12000的指数形式。
// 指数形式是实型数据特有的表示方法,e就代表10的次幂,E3就代表103次幂,E和e大小写任意。
// E的左右两边都必须有数字,且右边的数字必须是整数,但可以是负整数。
// 规范化指数形式:在字符e的左面的数字中,小数点的左面有且仅有一位非零数字。如:1.2e2 就是规范化指数形式。
// 实型变量分为单精度(float)型、双精度(double)型。
// 单精度型(float)占4字节,float型常量后面跟着一个“F”或者“f” 。
// 双精度型(double)占8字节,double型常量后面可以加上“d”或“D”。
// 浮点数默认为double型,因此“float f=12.4;”是错误的,因为double的精度float高,不可以直接赋值。
// 需要注意的是:
// 1. 浮点成员变量默认值为0.0,浮点局部变量同样没有默认值。
// 2. 浮点数/0结果为+-Infinity(正负无穷大),0.0/0.0结果为NaN(Not a Number,即这是一个数学上没有定义的值)。
// 3. float、double 如果取值达到上界以上,则会取值:+Infinity或者-Infinity,整数型变量数值达到最大时会自动跳到最小,达到最小时会跳到最大,即所谓的物极必反。
// 4. double比float范围更广、精度更高,但float比double更速度、更节省空间。
范例4:字符和布尔。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// 字符型数据分为:字符型常量和字符型变量。
// 字符型数据(char)占2个字节,是无符号型数据,取值范围:0~65535。
public static void main(String[] args) {
char ch = (char) -1;
// char类型所有字符都是用2个字节存储的,即‘a’和‘崔’都是使用2个字节。
// 输出65535
System.out.println((int) ch);
// 若是字符串“a”则本质上却仍是1字节。
// 输出1,1
System.out.println("a".length() + "," + "a".getBytes().length);
// 在字符串里出现的汉字,所占的字节数是变化的,占2、3、4字节都有可能。
// 输出1,3
System.out.println("崔".length() + "," + "崔".getBytes().length);
// 此汉字占两个字符长度,如果尝试打印charAt(0)和charAt(1)则会出现“?”
// 也就是说,下面这个汉字占2位长度。
// 输出2,4
System.out.println("𠮷".length() + "," + "𠮷".getBytes().length);
// 下面的语句无法编译通过,因为这个汉字不在char数据类型的收藏范围内。
char ch='𠮷';
}
// 布尔型数据分为:布尔型常量(只有true和false两个取值)和布尔型变量。
// 成员变量默认值为false,局部变量没有默认值。
范例5:数据类型转换。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// 整型、实型、字符型混合运算时,从低级到高级的优先关系如下:
// byte → short → char → int → long → float → double
// 将一个低优先级的常量或变量赋给一个高优先级的变量时,会产生自动转换:
long i=5; // 5默认为int型的常量,此时赋给一个long型变量。
double d= 2.4f //2.4f是float型的常量,如果去掉f则默认为double型常量。
// 类型自动提升规则:
// a和b作某种运算,先把低级类型转成高级类型后在开始运算。
// a和b中最高是double,结果就是double。
// a和b中最高是float,结果就是float。
// a和b中最高是long,结果就是long。
// 除此之外,结果都是int。
byte a = 1;
byte b = 2;
a = a+b; //编译出错自动类型提升成int
a += b; //+=没有自动类型提升问题
// 两个整数相除,计算出的结果也是一个整数。
// 如3/2结果为1,Java会自动截断小数部分。
// 把高字节转成低字节,需要作强制类型转换。
byte c=(byte)(a+b);
// 需要注意的是“byte a = 1;”中的“1”是一个整数常量,整数常量默认为int型。
// 而int型又比byte、short、char型的优先级高,按道理来说是不可以将一个整数常量赋值给这三个类型的,但事实上是:
// 整数 -128~127 之间(包括)的数可以直接赋值给byte型。
// 整数 -32768~32767 之间(包括)的数可以直接赋值给short型。
// 整数 0~65535 之间(包括)的数可以直接赋值给char型。
// 整数 +-21亿之间的数可以直接赋值给一个int型。
// 如果一个整常量超过int型的范围,则必须在这个整数后面加上一个“L”来指明这个数是一个long型的常量,否则编译出错。
范例6:封装类。
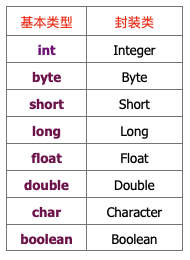
其中6种数字类型均派生自Number类,而Boolean和Character则直接派生自Object。
1 | // 装箱: |
范例7:对象重用。1
2
3
4
5
6
7public class Demo {
public static void main(String[] args) throws Exception {
Integer i = 10, j = 10, m = 200, n = 200;
System.out.println(i == j); // true
System.out.println(m == n); // false
}
}
语句解释:
- 在自动装箱时,对于值在-128~127之间的值,它们被装箱为Integer对象后会在内存中被重用。
- 如果超过了这个范围,被装箱后的Integer对象并不会重用。
- 为什么这么做?因为人们认为-128~127之间的数使用的频率特别频繁,若每用到这些数都new一个新的对象,则很浪费空间。
范例8:关于“==”号。1
2
3// 在Java中有两种数据类型可以使用“==”进行比较。
// “基本数据类型 == 基本数据类型” 比较的是变量值。
// “复合数据类型 == 复合数据类型” 比较的是对象的引用变量的值,不是hashCode码。
流程控制
范例1:单分支结构。1
2
3
4
5
6
7
8
9
10
11
12
13// 单分支结构中只有两个分支,程序将只能选择其中一个分支,然后执行下去,使用if语句来表达。
public class Demo{
public static void main(String[] args){
boolean b=false;
// Java中If语句里只能是boolean类型的常量或表达式,不能是数字。
if(!b)
if(b)
System.out.println("true");
// 下面的else和第二个if配对,因此程序执行的结果是输出false。
else
System.out.println("false");
}
}
语句解释:
- 因此应该在第一if后,加上一对大括号将下面的if...else给括起来。
范例2:多分支结构。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 单分支结构中只有两个分支,程序将只能选择其中一个分支,然后执行下去,使用if语句来表达。
public class Demo{
public static void main(String[] args){
int a = 1;
switch(a){
// 同级的每一个case后常量不能相同。
case 1:
// 每一个case执行完后应该加一个break,否则程序流程会继续执行下去,不再匹配case。
break;
case 2:
case 3:
break;
case 4:
break;
// default 后面不跟常量,当所有case都失配时,会执行default后的语句。
// 可以没有default,若没有default并且所有case都失配,则程序不执行任何操作。
default:
// 最后一个语句可以不写break,各个case和default任意排列,不用分先后。
break;
}
}
}
范例3:循环结构。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 循环结构:分为直到循环和当型循环。
// 直到循环:程序流程至少会循环一次,使用do…while()实现,在while()后要加上一个“;”
// 当型循环:只有当条件满足时,循环体才会执行,最少时一次都不执行,使用while(..){}和 for(..)来实现。
// for语句的语法
// for(表达式1;表达式2;表达式3)
// 表达式1用来初始化循环控制变量。
// 表达式2用来判断循环是否应该结束。
// 表达式3用来迭代循环控制变量。
// 其中3个表达式都可以省写,如果省写表达式2,则默认为真(此时可能产生死循环),但是for语句中的2个分号不能省写。
// 关于break和continue:
// break可以在循环体和switch中使用,continue只能在循环体中使用。
// break结束最内层的循环,然后执行最内层循环体之后的语句。
// continue结束最内层循环的当前这一次,然后执行最内层循环体的下一轮循环。
// 带标号的跳转语句:
// “break 标号;” 可以跳出任意层的循环,然后执行标号指向的循环体之后的语句。
// “continue 标号;” 可以执行标号指向的循环的下一轮循环。
数组
范例1:一维数组定义格式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 只定义不赋值
// 数组类型[] 数组名 =new 数组类型[数组长度];
// 数组类型 数组名[]=new 数组类型[数组长度];
// 定义的同时进行赋值
// 数组类型[] 数组名 =new 数组类型[]{参数1,参数2,…..参数n};
// 数组类型 数组名[]={参数1,参数2,…..参数n};
// 其中[数组长度]可以是变量也可以是常量,变量最高只能是int型的。
// 数组下标从0~9,并且所有元素都有默认值,且默认为0。
int[] array=new int[10]
// 定义数组的同时,为数组初始化,此时“new int[]”的中括号内不能指定长度。
int[] array=new int[]{1,2,3,4,5}
// 但是此方式只能在定义的同时使用。
int[] array={1,2,3,4,5}
// 这样写是错误的:
int[] array=null;
array={1,2,3,4,5}
范例2:二维数组定义格式。1
2
3
4
5
6
7
8
9
10
11
12
13
14// 只定义不赋值
// 数组类型[][] 数组名 =new 数组类型[行长度][列长度];
// 数组类型[][] 数组名 =new 数组类型[行长度][];
// 定义的同时进行赋值
// 数组类型[][] 数组名 =new 数组类型[][]{ {参数1} , {参数2,…..参数n} };
// 数组类型[][] 数组名 = { {参数1} , {参数2,…..参数n} };
// 在Java中定义多维数组时,可以只指定最高维的长度,低维的长度可以稍后指定。
// Java中多维数组每一行的列数可以互不相同,C语言中数组所有行的列数必须相同。
// 只是建立了一个引用变量,此时并无对象产生。
int[] a;
// “int[]”代表一个数据类型,不能在中括号里写长度。
// 数组的长度使用“数组名.length”来表示,如:array.length。
范例3:数组遍历。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// for遍历
public static void main(String[] args){
int[] array=new int[]{1,2,3,4,5,6};
for(int i=0;i<array.length;i++)
System.out.print(array[i]+"、");
}
// foreach遍历
public static void main(String[] args){
int[] array=new int[]{1,2,3,4,5,6};
// i的类型必须和数组的类型相同。
// 遍历时会自动使i依次指向array中的每一个元素。
for(int i:array)
System.out.print(i+"、");
// 说白了就是i必须要比数组小一级,接着看遍历2维对象数组:
Person[][] array=new Person[4][5];
for(Person[] i:array)
for(Person j:i)
System.out.println(j);
}
面向对象基础
面向对象和面向过程
现在木匠要做一个木箱子,按照面向对象和面向过程两种方法做。
面向对象
将箱子看成多个部分,首先分析箱子的结构,得出箱子由箱盖、箱体、拉坏等部分组成。
然后分别去做完 箱子的箱盖、箱体、拉坏等部分,各部分的尺寸按公共标准来。
各个部分都留有插口,用于与其他部分连接,最后将各部分组装成一个箱子。
面向过程
将箱子看成一个整体,箱子所有的组件之间联系紧密。
制作箱子的时候每做好箱子的一部分就将那部分“用钉子”嵌到到箱子上去,并不会去刻意的将各组件间的联系给疏远。
说白了对于面向过程来说只要“能做出一个箱子”就是万事大吉了,不会去考虑:
箱子中各个部件的连接是否合理
箱子某一组件损坏后,是否何以轻易的更换掉该组件
箱子无用后,是否能再重复利用箱子的一些组件
这就是所谓的面向过程是“专注于解决问题”,对于面向对象来说不仅要做出一个箱子,而且要做出一个设计合理、可维护、可重用的箱子,这就是所谓的面向对象是“专注于分析问题”。
比如现在出现了如下两个问题:
1、木匠觉得箱子的拉环做的不完美想要重新做一个拉环。
2、箱子用坏了,但是箱子的锁环由于是铁打的,所以还可以用,木匠想把这个锁环装到大门上继续使用。
对于面向过程来说,由于设计箱子的时候将箱子看成一个整体,因此箱子的锁环是在设计的时候是根据箱子的大小、木质等特点,为这个箱子“量身定做”的,如果箱子坏了或者想重做一个拉环,那么箱子的锁环也就没什么用了。而面向对象思路做成的箱子,它的各组件拼装的时候就设计好了组件间拼装的接口,因此 如果门上面也有这个可以插入箱子锁环的接口,那么就可以直接将箱子的锁环拿到门上面重用了。
需要注意的是:
面向过程编程还有一个特点:代码自顶向下一步一步顺序执行。
面向过程是面向对象的基础,不管你怎么分析问题,一切的分析都结束后,仍然需要按照面向过程的编程思路“自顶向下 一步一步 顺序执行”进行具体的编码。
换句话说就是,在大的方向上使用面向对象分析,在具体的实施阶段上,使用面向过程编程。
面向对象的三大特性1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 封装性
// 定义:所谓的封装性就是指,使类中重要的东西对外部不可见。
// 作用:保护类中的属性不被外部直接访问。
// 意义:
// 1、保护数据安全。比如说一个人的心脏,都是被皮肤、肌肉、骨头一层一层的包围(封装)起来的。如果不被保护在身体里面,而放到身体外面,那么任何人都可以看到、伤害到这个人的心脏 那么这个人要是和谁有仇,那么他不就完蛋了吗?随便拿个针就能戳破他的心脏。
// 2、封装复杂度。比如说电脑的显示器,咱们不需要知道它的工作原理,只需要插上电源使用它就可以了,至于显示器具体的组成、工作原理都被封装到一个显示器外壳内部了,用户不用去管它。
// 继承性
// 和现实世界中的继承是一个意思。
// 在现实世界中:孩子继承老子的遗产。
// 在编程中:子类继承父类的属性和方法。
// 多态性
// Java中多态分为两种:方法重载、方法重写。
// 咱们在大街上喊一声“我爱中国”,路人听到咱们这句话(即接受到咱们的消息)后,每个人对此所做出的反应是不同的,有“惊讶,偷笑,无聊,赞许”等等,路人这些反应,就称为多态。
类
类与对象
类:就是对一群事或物共有特征和行为的抽象。它是抽象的、不是客观存在的。它是一个模板、一张图纸。比如说:
人类
特征: 姓名、年龄、性别
行为: 说话、吃饭、学习、工作鸟类
特征: 羽毛、翅膀
行为: 飞翔、下蛋
显然不能说“人类”就是指“张三”或者指“李四”,因为“人类”是抽象的。
对象:就是类的一个个体,一个具体的实例。它是具体的、客观存在的,它是类的一个样品、一个实物。比如说:
张三
特征:张三、30岁、男
行为:说话、吃饭、学习、工作麻雀
特征:灰色的羽毛、短小的翅膀
行为:飞翔、下蛋
范例1:类的基本组成。1
2
3
4
5// 类通常由两部分组成:属性和方法。类的定义格式:
class ClassName{
int name; // 属性;
void add(){}; // 方法;
}
属性
类的属性又称为:字段和成员变量。
成员变量分为:
实例变量:不用static修饰的变量,隶属于对象。
静态变量:使用static修饰的变量,隶属于类。
范例1:属性定义的格式。
[访问修饰符] [存在修饰符] 数据类型 变量名[=默认值];
语句解释:
- 中括号内的内容代表是可省写的。
范例2:修饰符。1
2
3
4
5
6
7// 访问修饰符就是起到限制别人访问本类中变量和方法的功能的修饰符。
// public 公开访问修饰符权限最大,在任何地方都可以访问。
// protected 保护访问修饰符权限第二,同一个包中的类和不同包的子类可访问。
// default 包访问修饰符权限第三,同一个包中的类可访问,不给变量写访问修饰符,则就默认为包访问。如果使用default关键词修饰变量反而错了,default只存在于switch、annotation等语句中。
// private 私有访问修饰符权限最低,只有本类内部的代码才可以访问。
// 存在修饰符 : static、final、transient。
方法
类的方法又称为:函数、行为、成员方法。
成员方法分为:
实例方法:不用static修饰的方法,隶属于对象。
静态方法:使用static修饰的方法,隶属与类。
范例1:方法定义的格式。
[访问修饰符] [存在修饰符] 返回值类型|void 方法名称(参数列表){
// 方法体。
[return 返回值]
}
语句解释:
- 中括号内的内容代表是可省写的。
- 如果方法没有返回值,则要使用void关键字,方法体中可以有return语句也可以没有return语句,如果有则return语句不能带回返回值。
- 如果方法有返回值类型,方法中必须要有return语句,且return必须带回返回值,且返回数据的类型与方法的返回值类型要兼容。
- 方法体中可以有多个return语句,执行到哪一个return语句,哪一个就起作用。
- 返回值类型可以是数组类型的,可以这么直接获取数组第一个元素“int i=getArray()[0]”。
范例2:方法的调用。1
2
3
4
5
6
7
8
9
10
11// 方法调用的时候,传递给方法的参数,会有自动数据类型晋升的机制。
// 例如:public void method(double param){}
// 然后执行“method(5);”
// 最终调用的流程:
// 由于实参是int类型变量,所以编译器首先会在类中查找方法
// public void method(int param){}
// 如果没有查找到,则会继续查找public void method(long param){}
// 如果仍然没有查找到,则会继续查找public void method(float param){}
// 如果仍然没有查找到,则会继续查找public void method(double param){}
// 如果仍然没有查找到,则编译报错。
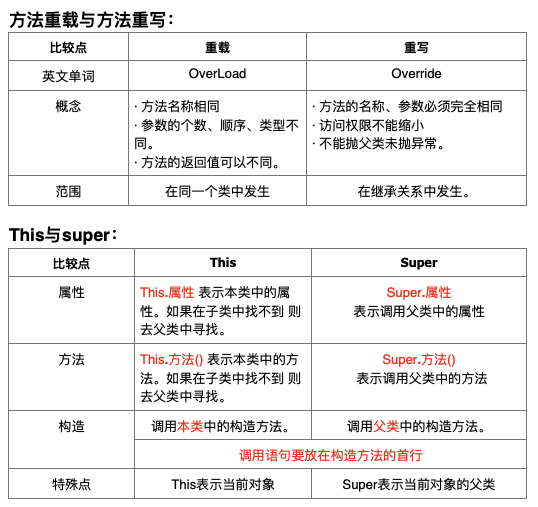
范例3:方法的重载(overloading)。1
2
3// 方法重载时,方法的名称必须相同。
// 方法重载时,方法的参数列表必须不相同,包括参数的个数、类型、顺序,也就是说两个同名的方法在这三项中至少要有一项互不相同。
// 方法重载时,方法的返回值类型可以不相同,即方法重载只检查方法名称和参数列表。
范例4:可变参数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Demo {
public static void main(String[] args){
print();
print(1,23,5);
print(1,23,5,6,2,11,32);
print(new int[]{1,23,5,6,2,11,32});
}
// int和temp之间的那三个“.”是固定的,不能多也不能少。
// 可变参数必须放在方法参数列表的最后一个位置。
// 编译器使用数组来存储可变参数中的参数,因此可以在方法中,以数组的形式访问可变参数。
// 可变参数可以传递0个或多个参数,若传递0个参数,则数组的长度为0,而非null。
public static void print(int...temp){
for(int i:temp)
System.out.print(i+" ");
System.out.println();
}
}
范例5:修饰符。1
2
3// 访问修饰符:public、protected、default、private
// 存在修饰符:static、final、abstract
// 操作修饰符:synchronized
定义一个类
范例1:学生类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69class Student{
private String name; // 学生的姓名属性
// 学生的学号属性
// static修饰的变量被称为类变量或静态变量,类中所有的对象 共用这个变量。
// 对象a改变这个变量的值,对象b再引用此变量的时候,引用的值是已经改变之后的了。
// static修饰的变量存在于全局数据区,static不能修饰局部变量。
private static int id;
// 构造方法的特点:
// 构造方法名必须和类名相同,方法没有返回值,也不是void。
// 不能在构造方法中使用return返回一个内容。
// 构造方法在实例化对象的时候(new的时候)被自动调用。
// Java会为每一个类提供一个默认的(无参)构造方法。
// 如果一个类显式的定义了一个有参的构造方法 则Java不会在为其提供无参的构造方法。
// 构造方法可以重载。
// 无参构造方法
public Student(){
// this表示“当前对象”,即当前正在调用本方法的对象。
// 使用this(参数)转调用其它构造方法。
// 此语句必须在构造方法中才能使用,必须是方法体中的第一条语句。
// 本类中必须要有一个构造方法没有调用其他构造,该方法作为递归调用的出口,一般使用无参的构造来作为这个出口。
this("学生"+id);
id++;
}
// 有参构造方法
public Student(String name){
// this.name用来调用当前对象的name属性。
// 局部变量的范围内,成员变量被隐藏,因此需要使用this。
this.name=name;
}
public String getName(){
return this.name;
}
}
public class Demo{
// static修饰的成员是隶属于类的,即使程序中没有该类的对象存在,也可以通过类名引用该类静态变量和静态方法。
// static定义的方法被称为类方法或静态方法,调用方式“类名.方法名(推荐使用此方式)”或者“对象名.方法名”。
// static修饰的方法内部,只能访问静态成员(静态方法、变量)不能访问实例成员、不能使用this、super关键字,因为当前程序中可能还没有该类的对象存在。
// static方法可以被继承但是不可以被重写,若子类存在一个和父类完全相同的一个方法,则父类的方法会被隐藏。
// static修饰的内部类被称为 静态内部类。
public static void main(String[] args){
// 创建一个Student对象
// 前半句只是在栈中声明一个引用变量,此时并没有对象产生,只是开辟的栈空间,而没有开辟堆空间,此时还不能使用stu调用类的方法和属性。
// 后半句才是实例化对象,开辟了堆空间,此时可以调用类的方法和属性。
Student stu=new Student();
// 实例属性和实例方法是隶属与对象的,每一个对象的属性和方法都独立于其它对象,即被这个对象自己独占。因此修改对象stu1的name字段,对对象stu2的name字段没有任何影响。
// 调用属性
stu.name="张三";
// 调用方法
stu.getName();
// 如果指定姓名 则按指定的姓名给学生初始化。
Student stu2=new Student("张三");
// 如果没有指定姓名 则调用无参的构造方法 进行自动命名。
Student stu3=new Student();
Student stu4=new Student("李四");
System.out.println(stu.getName());
System.out.println(stu2.getName());
System.out.println(stu3.getName());
System.out.println(stu4.getName());
}
}
内存简述
在操作系统中内存被划分为如下几个部分。
静态数据区
存放程序中的静态数据,如static变量、常量等。
变量的内存地址在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。
代码区
存放程序中源代码。如函数、语句等。
栈
存放简单变量、对象的引用变量。
当程序流程走出局部变量所在的代码块后,局部变量会被从栈中弹出。其所占内存会被操作系统自动回收。每当需要为函数中局部变量开辟空间时,都会从栈中申请。若栈中的内存足够,则系统将为程序提供内存,否则将报异常并提示栈溢出。当函数执行完毕后,会按照后进先出的原则,将局部变量依次弹栈,并将释放出的资源加入到栈中的空闲内存中。
堆
存放程序动态申请的数据。
如Java中的对象和C语言使用malloc()函数申请的空间都保存在堆中。堆是由内存中的多个分散的存储空间组成的一个不连续的存储空间,各个存储空间基于数据结构中的链表,而组织在一起。当系统收到程序的空间申请时会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
保存在堆中的数据,由于是用户自己动态申请的空间,所以当堆中的数据不再需要被使用时,则应该由用户手工释放该数据所占据的空间。因为系统并不知道空间中的数据,何时才不再会被用户使用,在
Java中却不需要用户手工释放空间。
名词:内存溢出(Out of Memory,OOM)
通常在两种情况下,会出现OOM的问题:
1、操作系统中当前剩余内存容量,不足以满足进程当前的申请的空间的需求。
2、进程当前所占的内存 + 其本次申请的内存 > OS允许单个进程的上限。
在Java中若进程遇到了OOM,则该进程会被操作系统给杀掉。
名词:内存泄漏
堆内存的空间由各个进程自己申请和释放,当某块申请的内存不再会被使用时,若没有被程序员及时释放,就会导致进程中明明存在可用的内存空间,却偏偏不能使用。
进程的内存泄漏情况严重后,最终会导致OOM。
名词:栈溢出(Stack Overflow)
栈中剩余空闲空间不足以满足应用程序所需要的空间。
递归死循环可以模拟出栈溢出的问题。
代码块
在Java中使用“{}”括起来的代码就称为代码块。
范例1:代码块的使用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class Student {
private String name;
// 构造块
// 在方法外部、类的内部出现的代码块。
// 通常用于初始化成员变量,每产生一个对象就会调用一次。
// 但是由于构造方法也能完成这个作用,所以构造块了解就可以了。
{
name="张三";
System.out.println("姓名:"+this.name);
}
// 静态块
// 在方法外部、类的内部、使用static修饰的代码块。
// 通常用于初始化静态变量,只会在类加载的时候调用一次。
// 静态块和静态方法一样,不可以引用实例变量和实例方法。
static {
System.out.println("静态块");
}
}
public class Demo{
public static void main(String[] args){
// 普通代码块 : 在方法内部出现的代码块。
{
int i=5;
System.out.println(i);
}
int i=6;
System.out.println(i);
}
}
类的继承
范例1:学生也是人啊。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Person{
String name;
public void fun(){
System.out.println("Hello World");
}
}
// Java中使用extends关键字来实现继承。
// 子类可以继承父类中的非private属性和方法。
// 在Java中不允许多继承,一个子类只能有一个直接父类,C++中允许有多继承。
class Student extends Person{
int score;
public Student(String name,int score){
this.name=name;
this.score=score;
}
}
public class Demo{
public static void main(String[] args){
Student stu=new Student("张三",90);
stu.fun();
}
}
语句解释:
- 在Java中可以使用多层继承,一个子类可以有多个间接父类,通俗的说一个人可以有老爸、爷爷、祖宗。。。。。
范例2:关键词super。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32class Person{
private String name;
public Person(String name){
this.name=name;
}
public String getName(){
return this.name;
}
}
class Student extends Person{
int score;
public Student(String name,int score){
// 调用父类的构造方法
// super关键字的用法和this是一样的,super代表父类的意思,this代表当前对象。
super(name);
this.score=score;
}
public void fun(){
// 调用父类的属性和方法
System.out.println("姓名: "+super.getName()+"\t分数:"+this.score);
}
}
public class Demo{
public static void main(String[] args){
// super有三种用法:
// 调用父类的构造方法。
// 调用父类的属性。
// 调用父类的方法。
Student stu=new Student("张三",90);
stu.fun();
}
}
方法重写与属性隐藏
方法重写
所谓的方法重写(over riding) 就是指,在子类中定义一个与父类方法中同名的方法。
方法重写具有如下特点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 子类中的方法必须和父类中的方法同名。
// 子类方法的参数列表必须和父类方法的完全相同,参数列表的内容包括:参数的个数、顺序、类型。
// 子类中重写的方法的访问权限不能小于父类中方法的访问权限,可以增大访问权限。
// 子类方法的返回值必须和父类方法的返回值相同,如果父类返回double型 则子类也必须是double,或者子类方法返回值的类型是父类方法返回值类型的子类。
// 如果父类方法抛出了异常
// 子类方法可以不抛异常。
// 子类方法可以抛出父类方法抛出的异常。
// 子类方法不可以抛出父类方法没有抛出的异常。
// 子类方法抛出的异常可以是父类方法抛出的异常的子类,如果父类方法抛出的异常是Exception则子类方法可以抛出任意类型的异常。
// 父类中的private、final修饰的方法不会被重写。
// 子类无法继承父类中的使用private。如果你重写成功了,那只不过是重新定义。
// final修饰的方法 被称为最终方法 不能被重写。即“可以被继承 但不能重写”。
// Static修饰的方法可以被重写、继承。
范例1:父子冲突。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Person{
public void fun(){
System.out.println("父类中的方法");
}
}
class Student extends Person{
// 由于父类中的fun()方法是public权限,因此在Student类中继承了该方法。
// 由于Student类中又定义了一个fun()方法,此时和从父类中继承来的fun方法产生了冲突。
// 因此就形成了Java中的“方法重写”。
public void fun(){
System.out.println("子类中的方法");
}
}
public class Demo{
public static void main(String[] args){
Student stu=new Student();
// 调用重写后的方法
stu.fun();
}
}
语句解释:
- 使用子类对象调用被重写的方法时 调用的永远都是子类重写后的方法。
范例2:不留遗产给儿子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Person{
private void fun(){
System.out.println("父类中的方法");
}
public void print(){
this.fun();
}
}
class Student extends Person{
public void fun(){
System.out.println("子类中的方法");
}
}
public class Demo{
public static void main(String[] args){
// 执行结果:“父类中的方法”
Student stu=new Student();
stu.print();
}
}
语句解释:
- 定理1:如果调用的方法“在子类中被重写”,那么调用一定是子类中的方法。
- 定理2:如果调用的方法“在子类中没被重写”,那么调用的一定是父类中的方法。
- 定理3:父类中的private方法在子类中“永远不是重写,而是重新定义”。
属性隐藏
所谓的属性隐藏就是指,在子类中定义了一个与父类中同名的属性。
范例1:父子都有名字。1
2
3
4
5
6
7
8
9
10
11
12
13
14class Person{
String name="张三";
}
class Student extends Person{
// 由于在子类中定义了一个与父类中同名的实例变量。
// 因此父类中的变量被隐藏起来了,不再起作用。
String name="李四";
}
public class Demo{
public static void main(String[] args){
Student stu=new Student();
System.out.println(stu.name);
}
}
语句解释:
- private修饰的属性同样不可以被继承。
- 如果希望调用父类中被隐藏的属性,可以在子类中使用super关键字。
- 子类中的属性可以和父类中的属性的类型不相同,只要变量名相同,就可以达到属性隐藏的效果。
- 实际开发中,属性都是private的,因此关于属性的隐藏了解即可。
范例2:请记住隐藏并不是绝对的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18package cxy.zy.demo;
public class Super {
private int age=23;
public void printer(){
System.out.println(age);
}
}
class Sub extends Super{
private int age =24;
public static void main(String[] args){
// 程序输出的结果为:23
// 原因:
// 若在子类中引用了子类的与父类同名的属性,那么引用的一定是子类的。
// 若在父类中引用了二者同名的属性,那么引用的一定是父类的。
Sub s = new Sub();
s.printer();
}
}
语句解释:
- 隐藏父类的属性,其实和局部变量与成员变量同名的处理方法是一个样的,在局部变量的范围内,成员变量被隐藏;在子类的范围内,父类的同名属性被隐藏。
关键字final
final关键字四种用法:
修饰类:此类不可以被继承。
修饰方法: 此方法可以被继承但不可以被重写。
修饰变量: 此变量被标为常量,只能赋值一次,赋值后其值不可以改变。
和static组合一起修饰变量:被成为全局常量或类常量,可以使用类名调用。
关于常量,需要知道的是:
局部常量:使用之前必须赋值,赋值后其值不可再更改。
实例常量:可以在定义的同时赋值,也可以通过“实例块”、“构造方法”赋值。但是实例常量不会有默认值,因此使用之前必须手工赋值。
类常量:只能且必须在“定义的同时”或者“静态块”中赋值。
抽象类
所谓的抽象类就是指一个不完整的类。
范例1:定义格式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 使用abstract class关键字定义抽象类。
// 如果一个类中定义了抽象方法,那么这个类必须是抽象类,即使用abstract定义。
// 抽象类中可以有抽象方法,也可以没有抽象方法。
// 如果一个类继承了抽象类,则必须重写完抽象类中所有抽象方法,否则它也必须使用abstract修饰。
// 抽象类是不可以实例化对象的。
// 被final修饰的类不能有子类,而abstract类必须被继承,因此二者不能同时修饰类。
// 抽象类中可以存在构造方法。
abstract class Person{
public void fun(){
System.out.println("Hello World");
}
// 使用abstract关键字定义的方法称为抽象方法。
// 抽象方法没有方法体,即没有“{}”。
// 抽象方法只有在被重写后才可以使用。
// 抽象方法不可以使用private修饰。
public abstract void method();
}
接口
接口是一个特殊的类,其内定义的所有属性都是静态常量,所有方法都是抽象方法。
范例1:定义格式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 接口使用interface关键字定义。
interface Person{
// 不论你是否明写,接口中所有的属性默认为public static final。
public static final String STR="Hello World";
// 不论你是否明写,接口中所有的方法默认为public abstract。
// 因此不能将public改成private、protected关键字。
public abstract void fun();
// 不能在接口定义构造方法。 即接口只能存在一个系统提供的无参的构造方法。
}
// 一个类使用implements关键字来实现一个接口。
// 一个类只能同时继承一个类,但是可以同时实现多个接口。
// 类定义完整的格式:class 类名 extends 父类名 implements 接口A名, 接口B名…;
class Student implements Person{
public void fun(){
System.out.println("Hello World");
}
}
public class Demo{
public static void main(String[] args){
Student stu=new Student();
System.out.println(stu.STR);
stu.fun();
}
}
语句解释:
- 接口只能继承接口,接口可以实现多继承,即一个接口可以同时继承多个接口。
- 若在抽象类中定义抽象方法,则需要在方法头部,手工加上abstract关键字。
- 一个抽象类同样可以实现多个接口,但是接口不可以继承类。
范例2:向上转型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class Person{
public void fun(){
System.out.println("父类fun()");
}
}
class Student extends Person{
public void fun(){
System.out.println("子类fun()");
}
public void fun1(){
System.out.println("子类fun1()");
}
}
public class Demo{
public static void main(String[] args){
// 将子类对象赋值给父类的引用变量的行为,就是向上转型。
// 进行向上转型后stu只能调用父类中存在的fun(),不能调用fun1()。
Person stu=new Student();
stu.fun();
// 因为本质上stu是Student类的对象,它还是可以调用fun1()的,但需要向下转型。
Student stu2= (Student)stu;
stu2.fun1();
// 下面的代码,是无法向下转型的,因为stu本质是Person对象。
// 强行操作的话,运行时会抛异常。
// Person stu= new Person();
// Student stu1=(Student)stu;
// 为了避免抛出异常可以在向下转型之间使用instanceof关键字进行验证。
Person p = new Student();
if(p instanceof Student ){
Student stu3 = (Student)p;
System.out.println("转换成功 p是Studnt类的对象");
}
}
}
范例3-1:多态的作用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35abstract class Person{
public abstract void fun();
public abstract void fun1();
}
class Student extends Person{
public void fun(){
System.out.println("Student子类fun()");
}
public void fun1(){
System.out.println("Student子类fun1()");
}
}
class Worker extends Person{
public void fun(){
System.out.println("Worker子类fun()");
}
public void fun1(){
System.out.println("Worker子类fun1()");
}
}
public class Demo{
public static void main(String[] args){
Demo demo = new Demo();
demo.calls(new Student());
demo.calls(new Worker());
}
public void calls(Student stu){
stu.fun();
stu.fun1();
}
public void calls(Worker worker){
worker.fun();
worker.fun1();
}
}
语句解释:
- 在Demo类中使用方法重载来实现调用每一个子类的fun()和fun1()方法。
- 假设Person类有100个子类,则就需要在Demo类中重载100方法,这是根本不行的。
- 此时使用对象的多态性就可以很简单的解决这个问题。
范例3-2:修改代码。1
2
3
4
5
6
7
8
9
10
11public class Demo{
public static void main(String[] args){
Demo demo = new Demo();
demo.calls(new Student());
demo.calls(new Worker());
}
public void calls(Person per){
per.fun();
per.fun1();
}
}
语句解释:
- 此时就使用到了 对象多态性中的 向上转型。
- 因为每一个子类中都重写了父类中的方法,JVM使用会调用子类重写后的方法。
- 此时不论有多少个子类,都不需要修改calls方法。
在继承关系中,父类的设计很重要,只要父类设计合理了,代码的开发就非常方便了。
内部类
定义:所谓的内部类就是指,在一个类的内部定义一个类。
分类:
局部内部类
实例内部类
静态内部类
匿名内部类
范例1:局部内部类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Outer {
private String name="张三:";
public static void main(String[]args){
final int j=20;
// 所谓的局部内部类,就是指在一个块中定义的类。
// 局部内部类和局部变量的地位是一样的,它们都不可以使用访问修饰符和static修饰。
// 局部内部类的作用范围就是其定义位置开始到“块”结束。
class Inner{
public String getString(){
return new Outer().name+"说"+j;
}
}
System.out.println(new Inner().getString());
}
}
语句解释:
- 局部内部类可以访问其外部类的私有成员变量和其所在块内定义的局部变量,但是局部变量必须使用final修饰。
范例2:实例内部类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class Outer{
private String str="Hello World";
// 实例内部类就是指在类内方法外定义的内部类。
// 实例内部类的地位和实例方法是一样的。
// 实例内部类可以使用private、public、default、protected修饰。
// private内部类只有其外部类可以访问。
// protected内部类只有其同一个包中的类和不同包中的其外部类的子类可以访问。
// 内部类的全名:外部类名.内部类名。
// 内部类生成的.class文件,命名为“外部类名$内部类名.class”。
class Inner{
public String getInfo(){
return str;
}
}
}
public class Demo{
public static void main(String[] args){
// 没有外部类对象,就没有实例内部类的对象。
// 因此要通过外部类对象,来创建实例内部类的对象。
Outer out=new Outer();
// 通过外部类对象实例化内部类对象
Outer.Inner in=out.new Inner();
System.out.println(in.getInfo());
}
}
语句解释:
- 在以后要学的各种框架(FrameWork)时会大量使用内部类,因此最好此时打好基础。
范例3:在外部类的实例方法中,建立内部类的对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Outer{
private String name="张三";
// 内部类不能与外部类同名。
private class Inner{
private String str;
private Inner(String str){
this.str=name + str;
}
}
public String fun(){
//在外部类的实例方法中建立实例内部类的对象。
return new Inner(" : Hello World").str;
}
}
public class Demo{
public static void main(String[] args){
System.out.println(new Outer().fun());
}
}
范例4:静态内部类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Outer{
// 静态内部类,就是指在类内、方法外使用static关键字定义的内部类。
// 静态内部类的地位和静态方法是一样的。
// 静态内部类和静态方法中的局部内部类,不能直接访问其外部类的实例成员。
static class Inner{
public String getInfo(){
return "Hello World";
}
}
}
public class Demo{
public static void main(String[] args){
// 静态内部类隶属于外部类,即使没有外部类的对象,静态内部类也同样存在。
// 因此可以使用“外部类名.内部类名”来实例化。
Outer.Inner in=new Outer.Inner();
System.out.println(in.getInfo());
}
}
范例5:匿名内部类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18interface A{
public void fun();
}
public class Demo{
public static void main(String[] args){
// 所谓的匿名内部类,说白了就是指这个类没有名字。
// 匿名内部类必须继承一个已经存在了的类或者接口。
// “new A(){}”这句话的意思是:建立了一个实现了A接口的匿名内部类的对象 这个内部类没有名字,匿名类中重写了A接口中的fun()方法。
new A(){
public void fun(){
System.out.println("Hello World");
}
}.fun();
// “new A(){}”匿名类调用了A接口的无参构造方法,如果需要调用有参构造方法 则在小括号中加上参数即可。
}
}
语句解释:
- 匿名内部类意味着只能用一次,而所谓的用,其实就是实例化对象,同时既然只用一次,所以就没必要起名字了,因而我们使用匿名内部类的时候,就将类定义和实例化两个操作合二为一了。
- 本例中,匿名内部类写全了就是:“class 类名 implements A{}”,省写后就成了“new A(){}”。
- 匿名内部类的名称为“Demo$1.class”因为没有名字,所以使用数字进行编号。
对象实例化与类加载
对象实例化过程
一个类的对象产生过程从两方面来说:“有父类”和“无父类”。
范例1:无父类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// Java中类名是可以使用汉字的,上面的代码可以直接执行。
class 盘子{
private String name;
public 盘子(String name){
this.name=name;
System.out.println("盘子的构造方法");
}
{
System.out.println("盘子的实例块");
}
}
class 桌子{
private 盘子 p=new 盘子("盘子");
private String name;
public 桌子(String name){
this.name=name;
System.out.println("桌子的构造方法");
}
{
System.out.println("桌子的实例块");
}
}
public class Demo{
public static void main(String[] args) {
// 执行结果:
// 盘子的实例块
// 盘子的构造方法
// 桌子的实例块
// 桌子的构造方法
桌子 desk=new 桌子("桌子");
// 对象的建立过程:
// 程序执行到“new 桌子("桌子");”时,会在堆中申请一定大小的空间。
// 然后在桌子类中,从上到下,扫描或初始化类的“实例属性”和执行“实例块”。
// 一切执行完后,才执行桌子类的构造方法,最后将对象在堆中的引用,传递给引用变量。
}
}
语句解释:
- 上面执行到桌子类的第13行代码的时候 又跳转到盘子类去执行。
范例2:有父类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class 动物{
private String name;
public 动物(String name){
this.name=name;
System.out.println("父类的构造方法");
}
{
System.out.println("父类的实例块");
}
}
class 猫 extends 动物{
private String name;
public 猫(String name){
super("小动物");
this.name=name;
System.out.println("子类的构造方法");
}
{
System.out.println("子类的实例块");
}
}
public class Demo{
public static void main(String[] args){
// 执行结果:
// 父类的实例块
// 父类的构造方法
// 子类的实例块
// 子类的构造方法
猫 cat=new 猫("小狗");
}
}
语句解释:
- 如果一个类具有父类,则一定会先建立完父类的对象后才会建立子类的对象。
- 在建立子类对象时,默认情况下会在子类的构造方法中会自动调用父类的无参构造方法。
- 如果父类中没有定义无参的构造方法,则编译就会出错。
- 因此在第14行代码处,显式的指明了要调用父类的哪一个构造方法。
- 需要知道的是,每建立一个此类的对象,都会重复执行一边上面的执行结果。
类加载过程
所谓的类加载,就是JVM将类加载到内存中,加载完毕后就可以在内存中建立这个类的对象。Java中类加载发生在如下三种情况:
创建一个类的对象。
调用一个类的静态变量。
调用一个类的静态方法。
范例1:类加载。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class 猫 {
private String name;
public 猫(String name){
this.name=name;
System.out.println("子类的构造方法");
}
static{
System.out.println("猫的静态块");
}
{
System.out.println("子类的实例块");
}
}
public class Demo{
public static void main(String[] args){
// 一个类只会被加载到内存一次,不会重复被加载。
// static块是在类加载的时候被调用,由于类只会被加载一次,所以静态块也只执行一次。
// “类加载”的过程要早于“对象实例化”的过程,如果有父类则同样先加载父类。
// 类加载的时候同样是自上向下的扫描静态变量和静态块。谁先定义 先执行谁。
// 类装载时只扫描静态变量和静态块,不执行静态方法。
// 执行结果:
// 猫的静态块
// 子类的实例块
// 子类的构造方法
// 子类的实例块
// 子类的构造方法
猫 cat=new 猫("小狗");
猫 cat2=new 猫("小狗");
}
}
范例2:一个变态的范例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70class 生物类{
private int i=11;
static {
System.out.println("生物类的静态块");
}
{
System.out.println("生物类的实例块");
System.out.println("this:"+this);
}
生物类(){
i=100;
System.out.println("生物类的构造方法");
}
public String toString(){
return "i="+this.i;
}
}
class 动物类 extends 生物类{
private int j=22;
static {
System.out.println("动物类的静态块");
}
{
System.out.println("动物类的实例块");
System.out.println("this:"+this);
}
动物类(int j){
this.j=j;
System.out.println("动物类的构造方法");
}
public String toString(){
return super.toString()+",j="+this.j;
}
}
class 猫类 extends 动物类{
private int k=33;
static {
System.out.println("猫类的静态块");
}
猫类(int k){
super(200);
this.k=k;
System.out.println("猫类的构造方法");
}
{
System.out.println("猫类的实例块");
System.out.println("this:"+this);
}
public String toString(){
return super.toString()+",k="+this.k;
}
public static void main(String[] args){
// 执行结果:
// 生物类的静态块
// 动物类的静态块
// 猫类的静态块
// 生物类的实例块
// this:i=11,j=0,k=0
// 生物类的构造方法
// 动物类的实例块
// this:i=100,j=22,k=0
// 动物类的构造方法
// 猫类的实例块
// this:i=100,j=200,k=33
// 猫类的构造方法
// in main:i=100,j=200,k=300
猫类 cat=new 猫类(300);
System.out.println("in main:"+cat);
}
}
异常处理
异常处理机制是指当程序出现错误后,程序如何处理。具体来说,异常机制提供了程序退出的安全通道。当出现错误后,程序执行的流程发生改变,程序的控制权转移到异常处理器。
Object类派生出Throwable类,Throwable类是Java中最大的处理异常的类,其又有2个子类:1
2
3
4
5
6
7
8
9
10// Error类
// Error一般表示由程序运行异常或其他原因导致的一个JVM错误。
// 它们通常是一个致命的错误,不是一般程序能控制的。
// 因此在程序中一般也无法解决此类问题。
// 例如当发生OOM的时候,就会抛出“java.lang.OutOfMemoryError”。
// Exception类一般是指程序中可以进行处理的错误。如除数为0、数组下表越界等,其本身又分为两类:
// RuntimeException 异常:此类表示运行时的异常,即在程序运行的时候,由于某些变量的值非法等导致的错误,若出现RuntimeException,那么一定是程序员的错误。
// 其他非RuntimeException异常,如IOException,这类异常一般是外部错误,并不完全是程序本身的错误,而是在应用环境中出现的外部错误。
范例1:简单异常。1
2
3
4
5
6public class Demo{
public static void main(String[] args){
// 下面会抛出一个数学异常ArithmeticException。
System.out.println(10/0);
}
}
范例2:异常处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public class Demo{
public static void main(String[] args){
// 使用try…catch块来捕获异常。
try{
// try…catch块之间的语句代表是可能产生异常的语句。
// 一个语句可能会产生多种异常(但是在某一瞬间上只会产生一种异常),此时可以使用多个catch语句。
// 当产生一个异常的时候,程序会立刻终止本行代码的执行,直接跳到catch块中进行异常匹配,如果抛出的异常对象的类型和某一个catch块后面指定的类型兼容,则就执行此catch内的语句,否则继续匹配下一个catch语句。
int i = Integer.parseInt(args[0]);
int j = Integer.parseInt(args[1]);
System.out.println(i/j);
}catch(NumberFormatException e){
// 在Java中“万物皆对象”,异常也是一个对象,JVM会自动根据不同的情况产生不同的异常对象。
// 例如:如果程序执行到了10/0则会产生“数学异常”。
// 例如:如果程序引用了大于等于数组长度的下标 则会产生“数组越界异常”。
System.out.println("NumberFormatException 被执行"+e);
}catch(ArithmeticException e){
System.out.println("ArithmeticException 被执行");
// 打印异常信息和异常抛出的完整路线(即异常堆栈轨迹),此种打印方法最常用。
e.printStackTrace();
}catch(Exception e){
// 由于Exception是“最大”的异常处理类,所以任何异常只要是遇到了包含Exception的catch块,都会进去执行此catch块。
// 范围大的catch块一定要放在范围小的catch块之后,否则编译出错。
System.out.println("Exception 被执行");
e.printStackTrace();
}finally{
// finally块中的语句不论程序中是否抛出异常,都会去执行。
System.out.println("不论是否产生异常 finally都会被执行");
}
}
}
范例3:只有一句啊?太没诚意了吧。1
2
3
4
5
6
7
8
9
10class Student{}
public class Demo{
public static void main(String[] args){
// 下面的代码会编译出错
// Java中在if后面定义一个对象是完全没有意义的,因为没有人可以使用到它。
// 解决的方法:在if后面,加上一对大括号。
if(true)
Student stu = new Student();
}
}
范例4:手动抛出异常。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Student{
private String name;
private int age;
// 由于IllegalArgumentException是一个运行异常,因此不需要在构造方法头部使用throws关键字。
public Student(String name,int age){
if(name == null || (age<0 || age > 150))
// 使用throw关键字手动抛出异常。
throw new IllegalArgumentException("参数非法");
this.name = name ;
this.age = age ;
}
}
public class Demo{
public static void main(String[] args){
// 由于方法头部没有throws关键字,那么在方法的调用处也就不需要使用try…catch语句了。
Student stu = new Student("张三",-1);
}
}
范例5:异常信息阅读。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class Demo{
public static void main(String[] args){
div(10,0);
}
public static void div(int i,int j){
// 不能单独使用try块,try块之后必须跟随一个catch块或者一个finally块。
try{
int temp = i / j ;
}catch(Exception e){
e.printStackTrace();
}
}
}
// 异常信息:
//java.lang.ArithmeticException: / by zero
// at Demo.div(Demo.java:7)
// at Demo.main(Demo.java:3)
// 抛出的异常对象是 java.lang.ArithmeticException 类的。
// 异常信息是:by zero(即 除数为零)
// 异常抛出的起点:Demo.div(Demo.java:7) ,即Demo.java文件中的第7行代码,同时也是指Demo.java文件中的Demo类中的div方法中抛出。
// 异常抛出的终点: main方法。 (Demo.java:3)
语句解释:
- 如果程序中同时有return和finally语句 那么程序会先执行finally块中的语句 执行完后 才会执行return返回到方法的调用处。
范例6:自定义异常类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class IamSorry extends RuntimeException{
public IamSorry(){}
public IamSorry(String message){
super(message);
}
}
class Student{
private String name;
private int age;
public Student(String name,int age){
if(name == null || (age<0 || age > 150))
throw new IamSorry("参数非法");
this.name = name ;
this.age = age ;
}
}
public class Demo{
public static void main(String[] args){
Student stu = new Student("张三",-1);
}
}
// 自定义异常非常简单,共分4步:
// 第一步 自己想一个类名 。
// 第二步 让这个类继承Exception 类或者 RuntimeException类。
// 第三步 重写两个构造方法: 无参的 和 有一个String参数的构造方法。
// 第四步 然后就可以使用了。
语句解释:
- 我们都是使用系统自定义好的异常,一般来说不会去自定义异常。
范例7:断言。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 所谓的断言就是程序员告诉JVM:“我肯定 程序执行到某条语句的时候 其结果肯定是我说的值”。
public class Demo{
public static void main(String[] args){
int i = 10 ;
// 使用assert关键字来进行“断言”。
assert i == 100;
}
}
// 验证断言需要在执行程序的时候使用如下命令: java -ea Demo
// -ea 就代表验证断言是否正确的意思。
// 如果不加 –ea 则程序不会自主的进行断言判断。
// 如果断言正确,则什么事都没有,如果断言错误,则会抛出错误:Exception in thread "main" java.lang.AssertionError。
// 也可以自定义错误信息“assert i == 100:“断言错误”;”,那么抛出的异常信息则为:
// Exception in thread "main" java.lang.AssertionError: 断言错误
包机制
包实际上就是一个文件夹。
包机制的主要目的:实现在不同的文件夹中可以存在同名的类。
范例1:简单包定义。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 使用package关键字定义包,cxy.zy.demo是包名,包名可以任意自定义。
package cxy.zy.demo;
// 编译此程序使用:“javac -d . Demo.java”
// -d 代表创建目录。根据package语句来生成目录。
// . 代表在当前目录下创建。
// 编译此程序后,会在当前目录下生成一个名为cxy的文件夹,其下又有zy文件夹,zy下面又有一个demo文件夹。
// 在Demo.java文件中定义的所有类都会被放到cxy.zy.demo包下面。
// 编译后生成的.class文件中的类名就成为: 包名.类名。
// 如Demo类的全名为 :cxy.zy.demo.Demo
// 如Student类的全名为 :cxy.zy.demo.Student
// 因此在执行类的时候应该使用如下语句:java cxy.zy.demo.Demo
// 此时JVM会自动进入到cxy/zy/demo文件夹下执行名为cxy.zy.demo.Demo的类。
// 但是不能人为的进入到cxy/zy/demo文件夹下执行“java Demo”或者“java cxy.zy.demo.Demo”语句,这是不可能成功的。
public class Demo {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
class Student{}
范例2:导入包。1
2
3
4
5
6
7
8
9
10
11// 使用import语句导入cxy.zy.demo包中的Demo类。
// import可以有多条,但是必须放在所有类定义之前及package语句之后。
// 如果要导入一个包中的多个类 可以使用“import cxy.zy.demo.*;”
// 使用.*导入包时,只会导入程序中使用到的类,那些没使用到的类不会被导入。
import cxy.zy.demo.Demo;
class Test {
public static void main(String[] args) {
Demo d = new Demo();
d.print();
}
}
范例3:2个包中具有同名类啊。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25package cxy.zy.demo1;
public class Test {
public static void print() {
System.out.println("Demo1包中的Test类") ;
}
}
package cxy.zy.demo2;
public class Test {
public static void print() {
System.out.println("Demo2包中的Test类") ;
}
}
package cxy.zy.demo;
import cxy.zy.demo1.*;
import cxy.zy.demo2.*;
class Demo {
public static void main(String[] args) {
// 由于上例中两个包中都有Test类,所以在建立对象的时候需要指定类的全名,否则编译报错: 引用不明确。
// 在开发时所有的类都必须存在于包中。
cxy.zy.demo1.Test t = new cxy.zy.demo1.Test();
t.print();
}
}
语句解释:
- 在进行包导入的时候需要先配置classpath变量,此变量是JVM“找类”用的。
范例4:静态导入。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16package cxy.zy.demo;
// 所谓的静态导入就是,只导入一个类中的静态成员。
// 使用 import static 来进行静态导入Math类的静态变量和方法。
import static java.lang.Math.*;
// 也可以使用静态导入,导入某一个具体的静态方法或静态常量。
// import static java.lang.Math.pow ;
// import static java.lang.Math.PI ;
public class Demo{
public static void main(String[] args){
// 静态导入可以直接使用方法或变量的名称调用其他类的一个静态方法或变量,而不需要再使用类名.方法名来调用。
System.out.println(PI);
System.out.println(pow(2,4));
}
}
范例5:系统常用包。1
2
3
4
5
6
7// java.lang包 :此包包含了各种常用类,例如:Object、String等。在JDK1.0中此包需要手工导入,但是在现在此包会自动导入到程序中。
// ava.lang.reflect包 :此包为反射机制包,是整个Java乃至整个Java世界中最重要的包,此包可以完成大量的底层操作。
// java.util包 : 工具包,包含各种常用的操作类 如类库、类集等中的类都在此包中。
// java.io包 : 没的说 是Java中的IO包。
// java.net包 :网络编程。
// java.sql包:数据库编程。
// java.text包:在国际化时候使用此包。
Jar命令
在开发中一个软件会有很多的类,如果现在把这写类散装着给用户则肯定不好,因为太多了、容易乱,所以一般会将这些类压缩成一个jar包,然后将jar包发给用户就行了。
Jar文件其实就是一个压缩文件。
范例1:假设有一个类。1
2
3
4
5
6package cxy.zy.demo;
public class Demo {
public static void print() {
System.out.println("Hello World");
}
}
编译文件:
javac -d . Demo.java
压缩文件:
jar -cvf my.jar cxy
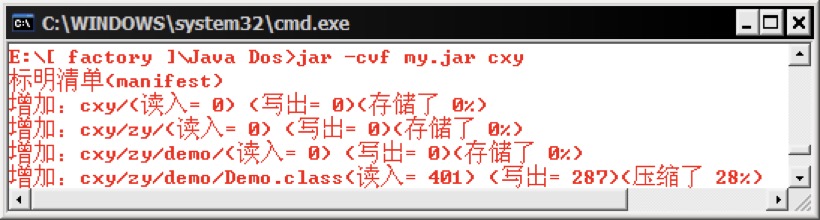
语句解释:
- c :创建文档
- v :详细的输出到底哪个类被导入到了jar包中了。
- f :指定文件的名称。 上例中文件名称为 my.jar
- cxy :要压缩的文件夹。 压缩时会将其子文件夹一起压缩。
此时就可以将这个jar文件发给客户了,客户拿到此文件后需要设置一下classpath,在其中加上此文件的路径就可以在程序中使用了。
范例2:双击可运行的Java程序。1
2
3
4
5
6
7
8
9
10
11// 首先将所有的类压缩成一个jar文件。
// 建立一个文件: mainclass.mf 使用记事本打开它。
// 在其中加上: Main-Class: 包名.类名
// 再在最后面加上一个回车键。
// 使用 jar –ufm jar文件的名称 mainclass.mf
// u 代表:更新现有的归档文件。
// 代表:指定文件名。
// m代表:包含指定清单文件中的清单信息。
// 双击jar文件即可。
// 例如:jar –ufm my.jar mainclass.mf
语句解释:
- 要始终记住 Java程序只能在JVM上运行,离开了JVM它是无法执行的。
- 所谓的双击运行只是方便程序的执行而已,电脑中必须得安装JDK或者JRE后才可以执行,否则 即使建立好了jar文件也没用,因为没有虚拟机。
- 有一种软件可以将java程序转换成.exe程序,原理也是一样的,如果电脑中没有JVM即使是转成.exe文件,也照样不能执行。
类库基础
基础类
String
在Java中String类用来表示一个字符串,它是final的不可被继承。同时Java中所有的字符串文字都是一个String的对象。
有两种方式可以创建一个String对象:1
2
3
4
5
6// 直接赋值字符串常量,此时内存中建立了一个String对象。
String str = "Hello World";
// 通过使用new关键字调用构造方法来实例化字符串对象。
// 此时内存中建立了两个String对象,一个是字符串常量"Hello World",另一个是new出来的。
String str = new String("Hello World");
常量池(constant pool)指的是在编译期被确定、并被保存在.class文件中的一些数据,组成的集合。它包括了关于类、方法、接口等中的常量,也包括字符串常量。
常量池中的字符串常量是唯一的,在池中不会同时存在两个相同的字符串常量。
使用第一种方法创建String对象时,JVM会从常量池中查找出常量”Hello World”的引用然后赋值给变量str。
使用第二种方法创建String对象是很浪费空间,因此很少用那种方法。
范例1:怎么证明只有一个呢?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Demo {
public static void main(String[] args) {
String str1 = "this is message";
String str2 = "this is message";
// 程序输出true。
// 两个引用变量使用“==”进行相等运算时,比较的是它们是否同时指向同一个对象。
System.out.println(str1 == str2);
String a = "A";
String b = "C";
String c = "AC";
a = a+b;
// 程序输出false。
// 新串"AC"是在程序运行的时候产生的,它存在于堆中,因此他和常量"AC"不是一个。
System.out.println(a == c);
}
}
范例2:其它常用函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48// 返回字符串指定位置上的字符,index>=0 。
public char charAt(int index)
// 将字符串转成字符数组。
public char[] toCharArray()
// 将String变成字节数组。
public byte[] getBytes()
// 构造方法,将字节数组转成String对象。
public String(byte[] bytes)
// 比如:new String(new byte[]{97,98,99}),结果为:abc
// 判断是否以指定的字符串开始。
public boolean startsWith(String pref)
// 判断是否以指定的字符串结束。
public boolean endsWith(String suffix)
// 替换字符串的内容,注意String类实现了CharSequence接口。
public String replace(CharSequence oldString, CharSequence newString)
// 比如:"---- Hello World ----".replace("-", "+");
// 将字符串中所有的-号替换为+号,并将新串返回来,但此时str的值并没有改变。
// 字符串截取。
public String substring(int beginIndex)
public String substring(int beginIndex, int endIndex)
// 比如1:str.substring(5, 10)从下标为5的位置开始,到10(不包括)结束。
// 比如2:str.substring(5)从下标为5截取到字符串末尾。
// 从0开始查找字符串,如果找到了则返回下标,如果未找到则返回-1。
public int indexOf(String str)
// 从指定位置开始向后进行字符串查找,如果未找到则返回-1。
public int indexOf(String str, int fromIndex)
// 字符串查找,如果查找到了则返回true否则返回false。
public boolean contains (CharSequence s)
// 消掉字符串首尾的小于等于\u0020的字符 (空格符的编码是(32)10)。
public String trim()
// 计算字符串长度。
public int length()
// 将字符串中的所有大写字母转成小写,不是大写字母则不变。
public String toLowerCase()
// 将字符串中的所有小写字母转成大写,不是小写字母则不变。
public String toUpperCase()
// 比较两个字符串,返回两个字符串中第一个不相同的字符间的差。
// 如果第一个字符串大则返回一个正数,否则返回一个负数,如果两个字符串相同则返回0.
public int compareTo(String ano)
// “equals()”方法:比较的是两个字符串的内容。
// “equalsIgnoreCase()”方法:忽略大小写比较2个字符串的内容。
Object
在Java中所有的类都是从Object类派生出来的。如果一个类没有明确的继承一个类,则它默认继承Object类,如果有父类,则它的父类或父类的父类….中,总有一个类是默认继承Object。
范例1:接收任何类型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Demo{
public static void main(String[] args){
int[] array=new int[]{1,4,6,2,1,6,2};
// Object类可以接受任意引用类型的对象,包括一维、二维数组
// 只要是new出来的东西都可以赋值给Object类的引用变量。
Object obj = array;
print(obj);
}
public static void print(Object array){
// 但是若想再次使用原来的对象,则需要向下类型转化。
int[] temp = (int[])array;
for(int i:temp)
System.out.print(i+"、");
}
}
范例2:常用方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44class Student{
private String name;
private int age;
public Student(String name,int age){
this.name=name;
this.age=age;
}
public boolean equals(Object obj){
if(this == obj)
return true;
if(!(obj instanceof Student))
return false;
Student temp = (Student)obj ;
if(this.name.equals(temp.name) && this.age == temp.age)
return true;
else
return false;
}
public String toString(){
// 如果不重写toString()方法则输出的数据:
// 对象所在类类名@对象的hashcode码(16进制形式)。
return "我是一个学生";
}
}
public class Demo{
public static void main(String[] args){
// 当一个对象需要被转换成String类型的,就会调用该对象的toString方法。
// 常见的需要转换的场景有:
// 1、System.out.println(),输出一个对象。
// 2、“转换吧:”+ new Student(),和一个字符串链接。
// 3、我们手动调用toString()方法。
// 因为此方法在Student类被重写了,所以输出的结果为:"我是一个学生"。
System.out.println(new Student("李四",20));
Student stu1 = new Student("张三",30);
Student stu2 = new Student("张三",30);
// 使用“==”号比较两个对象的时候,比较的是对象引用变量中保存的值。
// 如果想比较两个对象的内容(即字段)则需要重写object类的equals方法。
System.out.println(stu1.equals(stu2));
// String类也有一个equals()方法,其实这个方法就是重写Object中的方法。
}
}
系统类
Runtime
Java程序是以进程的形式运行在操作系统中的,Runtime类代表当前JVM的运行时环境,Runtime类是Singleton的由JVM来实例化。
使用Runtime类可以获取当前进程中JVM的内存状态、操作子进程等。
范例1:取得系统内存信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Demo {
public static void main(String[] args) {
// 获取Runtime类的单例对象。
Runtime r = Runtime.getRuntime();
// 返回JVM试图使用的最大内存量。单位:字节。
System.out.println("试图使用的最大内存:"+r.maxMemory());
// 返回JVM中实际可用的内存总量。此方法返回的值可能随时间的推移而变化,这取决于主机环境。单位:字节。
System.out.println("实际可用总内存:"+r.totalMemory());
// 返回当前JVM中的空闲内存量。单位:字节。
System.out.println("空闲内存:"+r.freeMemory());
String str = "";
for (int i = 0; i < 10000; i++)
str += i;
System.out.println("空闲内存:"+r.freeMemory());
// 运行垃圾回收器。
// 调用此方法意味着 Java 虚拟机做了一些努力来回收未用对象,以便能够快速地重用这些对象当前占用的内存。
r.gc();
System.out.println("gc后,空闲内存:"+r.freeMemory());
}
}
范例2:垃圾回收。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// 关于垃圾回收。
// 在每个Java应用程序运行的时候,其内都会开启多个线程,每个线程用来完成不同的任务。
// 这些线程中包含有:执行程序的入口代码的主线程、执行垃圾回收的gc线程等等。
// 从线程的重要角度来说,线程可以被分为:后台线程和非后台线程。
// 后台线程是在后台为别人提供服务的线程,但当程序的所有非后台线程结束时,即使后台线程还没有结束,程序也将终止。
// 主(main)线程是非后台线程,gc是一个后台线程。
// 当虚拟机判定内存不够的时候,gc会自动进行垃圾回收,因此在Java中通常不需要程序员手工的回收内存空间。
// 谁是垃圾?
// 在Java中,不再被引用的对象(没有引用变量指向的对象) 将被Java虚拟机视为垃圾。
// 注意:GC线程执行垃圾回收操作的时间是不确定,因此可以调用System.gc()方法来通知gc线程去执行垃圾回收操作。
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return "姓名:" + this.name + ";年龄:" + this.age;
}
public void finalize() throws Throwable {
// 当一个类对象被回收之间,会调用该类的finalize()方法进行收尾工作。
// finalize方法来自于Object类,重写时应将访问权限改为public。
// 对象的收尾工作和人死之前要写遗书是一个概念。
System.out.println("(" + this + ")因为犯罪被回收了.");
}
}
public class Demo {
public static void main(String[] args) throws Exception {
Person p = new Person("李四", 30);
p = null;
System.gc();
}
}
范例3:运行本机上的exe程序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 本范例需要运行在Windows系统中。
public class Demo {
public static void main(String[] args) throws Exception {
Runtime r = Runtime.getRuntime();
// Process类提供了执行从进程输入、执行输出到进程、等待进程完成、检查进程的退出状态以及销毁(killing)进程的方法。
// 通过ProcessBuilder.start()和Runtime类的exec()方法可以创建一个本机进程。
// 事实上在Runtime类的exec()方法中就是调用的ProcessBuilder类完成进程的创建。
// 打开Windows画图程序。
// exec方法会在单独的进程中执行指定的字符串命令。
// 其会返回一个Process对象,代表当前进程的子进程,使用Process可以进一步操作子进程。
Process p = r.exec("mspaint");
Thread.sleep(2000); // 2秒后关闭子进程。
// 关闭进程
p.destroy();
}
}
// 终止当前正在运行的JVM,此方法从不正常返回,可以将变量作为一个状态码。
// 根据惯例非零的状态码表示非正常终止。
// 此方法是Runtime类的。
public void exit(int status)
System
System类是一个系统类,其内的方法和变量都是静态的,其构造方法被隐藏。
在System类提供的设施中,有标准输入、标准输出和错误输出流;对外部定义的属性和环境变量的访问;加载文件和库的方法;还有快速复制数组的一部分的实用方法。
范例1:计算程序执行的时间。1
2
3
4
5
6
7
8
9
10
11
12// 1秒=1000毫秒
public class Demo {
public static void main(String[] args) throws Exception {
String str = "";
// 返回当前时间距离1970年1月1日午夜之间的时间差(单位:毫秒)。
long start = System.currentTimeMillis();
for (int i = 0; i < 20000; i++)
str += i;
long end = System.currentTimeMillis();
System.out.println("耗时" + ((end - start) / 1000)+"秒");
}
}
范例2:数组复制。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Demo {
public static void main(String[] args) throws Exception {
int[] array = { 1, 2, 3, 4, 5 };
int[] array2 = new int[10];
// System.arraycopy方法,用来复制数组中的元素到另一数组中。
// 第一个参数:源数组。
// 第二个参数:从源数组的此位置上的元素开始copy。
// 第三个参数:目标数组。
// 第四个参数:将copy来的元素放到目标数组从此位置上开始。
// 第五个参数:从源数组中copy多少个元素。
System.arraycopy(array, 0, array2, 0, 4);
// Arrays类在后面就会讲到,此处的toString方法是将数组中的所有元素转换成String类型。
System.out.println(Arrays.toString(array2));
}
}
工具类
常用工具
范例1:数组操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class Demo {
public static void main(String[] args) throws Exception {
int[] a = { 1, 2, 3, 4, 5 };
int[] b = { 5, 4, 3, 2, 1 };
// 若两个数组以相同顺序包含相同的元素,则两个数组是相等的。
// 此外,若两个数组引用都为null,则认为它们是相等的。
System.out.println(Arrays.equals(a, b));
// 将当前数组内的元素按照从小到大的顺序排序。
// sort方法可以对除了boolean类型之外的7种基本类型排序和对象数组进行按非递减的顺序排序。
Arrays.sort(b);
System.out.println(Arrays.equals(a, b));
// 将指定的int值(第二个参数)分配给指定int型数组的每个元素。
Arrays.fill(b, 5);
// 返回指定数组内容的字符串表示形式。
System.out.println(Arrays.toString(b));
char[] arrChar = {'C','h','i','n','a'};
int[] arrInt = new int[]{1,2,3,4,5};
// 输出:China
// 由于System.out对象提供了println(char[] x)方法,所以能直接输出字符串。
System.out.println(arrChar);
// 输出:[C@de6ced
System.out.println("输出char数组:"+arrChar);
// 输出:[I@c17164
System.out.println("输出int数组:"+arrInt);
}
}
范例2:对象数组排序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54// 如果一个自定义类想使用Arrays类的sort方法进行排序,需要实现Comparable接口。
class Student implements Comparable<Student>{
private String name;
private int age;
private int score;
public Student(String name , int age ,int score){
this.name = name;
this.age = age;
this.score =score;
}
public String toString(){
return "{"+this.name+","+this.age+"岁,"+this.score+"分}";
}
// 实现Comparable接口后,需要重写此方法,此方法用来比较当前对象与指定对象的顺序。
// 如果当前对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
// 返回一个大于0的数,意味着需要将当前对象和参数对象交换位置。
// 返回一个小于0的数,意味着不需要将当前对象和参数对象交换位置。
// 返回0代表相等。
// 按成绩从高到低排序学生,如果成绩相同,则按年龄从小到大排序。
public int compareTo(Student stu){
if(this.score > stu.score)
return -1;
else if(this.score < stu.score)
return 1;
else{
if(this.age > stu.age)
return 1;
else if(this.age < stu.age)
return -1;
else
return 0;
}
}
}
public class Demo {
public static void main(String[] args) throws Exception {
Student[] array ={
new Student("张三",21,99),
new Student("李四",25,91),
new Student("王五",22,94),
new Student("赵六",24,42),
new Student("秦七",23,42)
};
System.out.println("==========排序之前=============");
print(array);
Arrays.sort(array);
System.out.println("==========排序之后=============");
print(array);
}
public static void print(Student[] array){
for(Student stu:array)
System.out.println(stu) ;
}
}
范例3:数学运算。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Math类在java.lang包中,主要用来执行一些数学运算,如求绝对值、正弦、余弦等。
// 其内的所有方法和字段都是静态的。
import static java.lang.Math.*;
public class Demo {
public static void main(String[] args) throws Exception {
System.out.println("E = " + E) ;
System.out.println("PI = " + PI) ;
System.out.println("max(2,3) = " + max(2,3)) ;//计算最大数
System.out.println("min(5,4.3) = " + min(5,4.3)) ;
System.out.println("pow(2,4) = " + pow(2,4)) ;//计算 24
System.out.println("abs(-44)" + abs(-44)) ; // 计算绝对值
System.out.println("round(83.652)" + round(83.652)) ;//四舍五入
// 向上取整,即ceil(1.1)的值为2.0 ,但是咱下面这个语句则输出2.0 。
System.out.println("ceil = " + ceil(50 / 20));
// 因为两个整数相除的结果一定是整数。 50/20的值为2,然后才进行ceil(2)。
}
}
范例4:Random类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Random类在java.util包中。此类用于产生一个伪随机数,详见(官方API)。
import java.util.Random;
public class Demo {
public static void main(String[] args) throws Exception {
Random r = new Random();
System.out.println("随机一个int数:"+r.nextInt());
System.out.println("随机一个long数:"+r.nextLong());
// 返回一个从 0.0d(包括)到 1.0d(不包括)范围的数
System.out.println("随机一个double数:"+r.nextDouble());
// 返回一个从 0.0f(包括)到 1.0f(不包括)范围的数
System.out.println("随机一个float数:"+r.nextFloat());
System.out.println("随机一个boolean数:"+r.nextBoolean());
// 随机0(包括)~100(不包括)间的数。
for (int i = 0; i < 10; i++)
System.out.print(r.nextInt(100) + "、");
}
}
范例5:Scanner类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44// 本类需要用到后面IO一节中讲解的知识,请看完后在回来看此类。
// Scanner类一个可以使用正则表达式来解析基本类型和字符串的简单文本扫描器。
import java.util.Scanner;
public class FileDemo {
public static void main(String[] args) throws Exception {
Scanner sc = new Scanner(System.in);
if(sc.hasNextInt())
System.out.println("读到数字: "+sc.nextInt());
if(sc.hasNextBoolean())
System.out.println("读到boolean: "+sc.nextBoolean());
if(sc.hasNext())
System.out.println("读到一个单词: "+sc.next());
System.out.println("读到一行数据: "+sc.next());
}
}
// 运行结果:
// 64
// 读到数字: 64
// false
// 读到boolean: false
// Hello
// 读到一个单词: Hello
// 世界,你好! \n HelloWorld
// 读到一行数据: 世界,你好!
// 判断后面是否有一个int型的数据,如果有则返回true。
public boolean hasNextInt()
// 读取后面的int型数据。如果后面的数据不是int型数据 则抛异常。
public int nextInt()
// 判断后面是否有一个单词,如果有则返回true。
public boolean hasNext()
// 读取一个单词(即遇到间隔符或者回车符就停止读取)。
// Scanner类的默认分隔符:空格、tab、回车符等 “空白符”。
// 这些间隔符对除了nextLine()以外的任何方法都有效。
public String next()
// 修改分隔符,但对nextLine()无效,它只认换行符。
public Scanner useDelimiter(String pattern)
// 读取一行字符串,以换行符为结束标志(遇到间隔符照样读取)。
public String nextLine()
// Scanner类可以读取七种基本类型,没有nextChar()方法,对应的hasNextXxx()也没有。
// Scanner类中next的含义:下一个间隔符之前的内容。
// 比如nextInt()就是指读取下一个间隔符之前的int型数据。
范例6:字符串处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// String类是一个不可改变的字符串。
// StringBuffer是一个类似于String的字符串缓冲区,可以对字符串缓冲区中的字符进行修改(添加、删除)操作。由于可以修改缓冲区的数据,因而就涉及到多线程访问的问题,所以本类的大部分方法都是同步方法(后述)。每个字符串缓冲区都有一定的容量。只要字符串缓冲区所包含的字符序列的长度没有超出此容量,就无需分配新的内部缓冲区数组。如果内部缓冲区溢出,则此容量自动增大。
public class Demo {
public static void main(String[] args) throws Exception {
// 本类提供的很多与String相同功能的API,若程序需要动态的去修改一个字符串则应该使用StringBuffer或StringBuilder类,若是使用String类,则在操作完成后,内存中会产生大量的中间字符串。
// 注意String和StringBuffer没有任何继承关系,因此不能将一个String对象赋值给一个StringBuffer对象。
StringBuffer buf = new StringBuffer("Hello World");
buf.append("---> cxy").append("-----> tsx");
buf.insert(0, "cxy@zy --->");
// 将StringBuffer对象转成String类型。
System.out.println(buf.toString());
System.out.println(buf.indexOf("Hello"));
System.out.println(buf.charAt(0));
System.out.println(buf.delete(0, 1));
}
}
// StringBuffer类是一个线程安全的可变字符序列。
// StringBuilder类提供了和StringBuffer类相同的接口,但是不是线程安全的,不去考虑多个线程同时操作。
// 因此StringBuilder比StringBuffer的效率要高一些。
// 通常更多的会使用StringBuilder类。
范例7:性能测试。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// 在频繁改变字符串的时候 使用StringBuffer比使用String效率要好上很多。
// 在我这里,执行结果:
// stringbuff耗时:16毫秒!
// string耗时:4515毫秒!
public class Demo {
public static void main(String[] args) {
long start,end;
start = System.currentTimeMillis();
stringBuff();
end = System.currentTimeMillis();
System.out.println("stringbuff耗时:"+(end - start)+"毫秒!");
start = System.currentTimeMillis();
string();
end = System.currentTimeMillis();
System.out.println("string耗时:"+(end - start)+"毫秒!");
}
public static void string(){
String str = "";
for(int i=0;i<=20000;i++){
str += i;
}
}
public static void stringBuff(){
StringBuffer sub = new StringBuffer();
for(int i=0;i<=20000;i++){
sub.append(i);
}
}
}
日期处理
Date类表示特定的瞬间,精确到毫秒。
范例1:日期类。1
2
3
4
5
6
7
8public class Demo {
public static void main(String[] args) {
// 直接打印Date类的对象就可以得到当前时间。
// 但是得到的日期格式不符合国人的习惯,因此需要使用其他类对Date类的输出格式进行调整。
Date time = new Date();
System.out.println(time);
}
}
范例2:三年之后。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37import java.util.Calendar;
// Calendar类表示一个日历,它是对Date的一个封装(即增强版的Date)。
// Calendar可以方便的在某个时间上增加或减去一个时间。
public class Test {
public static void main(String[] args) {
// 使用默认时区和语言环境获得一个日历。
// 返回的Calendar默认表示的是当前时间,使用了默认时区和默认语言环境。
Calendar c = Calendar.getInstance();
c.add(Calendar.YEAR, 3); //将日历向后翻三年。
// 参数field:日历字段,常用的取值为:
// Calendar.YEAR:年。
// Calendar.MONTH:月。
// Calendar.DAY_OF_MONTH:日。
// Calendar.HOUR_OF_DAY:时。
// Calendar.MINUTE:分。
// Calendar.SECOND:秒。
// Calendar.MILLISECOND:毫秒。
System.out.print(c.get(Calendar.YEAR)+"年");
// 月份是从0开始计算的,范围为0~11,因此在输出的时候应该在月份后面+1。
System.out.print(c.get(Calendar.MONTH)+1+"月");
System.out.print(c.get(Calendar.DAY_OF_MONTH)+"日");
System.out.print(c.get(Calendar.HOUR_OF_DAY)+"时");
System.out.print(c.get(Calendar.MINUTE)+"分");
System.out.print(c.get(Calendar.SECOND)+"秒");
System.out.println(c.get(Calendar.MILLISECOND)+"毫秒");
// 例如要从当前日历时间减去5天,可以通过调用以下方法做到这一点:
Calendar.getInstance().add(Calendar.DAY_OF_MONTH,-5)。
c.set(Calendar.YEAR, 2012);
System.out.println("本年第 " + c.get(Calendar.DAY_OF_YEAR) + " 天");
// 通常国外认为,每周的第一天是周日。
System.out.println("本周第 " + c.get(Calendar.DAY_OF_WEEK) + " 天");
System.out.println("日期为: " + c.getTime());
}
}
范例3:日期格式化。1
2
3
4
5
6
7
8
9
10
11package cxy.zy.demo;
import java.text.SimpleDateFormat;
import java.util.Date;
public class Demo {
public static void main(String[] args) throws Exception {
// 在SimpleDateFormat类构造对象的时候,指定格式化后的日期格式。
SimpleDateFormat simple = new SimpleDateFormat("yyyy年MM月dd日HH时mm分ss秒SSS毫秒");
// 使用format()将Date对象格式化成刚才指定的格式。
System.out.println(simple.format(new Date()));
}
}
其它工具
范例1:对象克隆。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37package cxy.zy.demo;
// 所谓的对象克隆,其实就是指对象的复制。
// Java中不是所有对象都可以克隆的,只有实现了Cloneable接口的类才可被克隆。
// Cloneable接口中没有任何方法实现这个接口类就表示具有了一种能力、一种特点。
// 对象克隆的时候需要重写Object类的clone()方法。
class Person implements Cloneable {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return "姓名:" + this.name;
}
public Object clone() throws CloneNotSupportedException{
// 从表面上来说既然转调用clone()方法,那还不如不去重写呢。
// 其实不然,仔细观察Object类的clone()方法,它的访问权限是protected的 在不同包的非子类中是无法访问的。
// 因此我们重写clone()方法的主要目的就是,扩大clone()方法的访问权限为public。
// 而具体的克隆操作,交由父类完成即可。
return super.clone();
}
}
public class Demo {
public static void main(String[] args) throws Exception {
Person p1 = new Person("张三");
Person p2 = (Person)p1.clone();
p2.setName("李四");
System.out.println(p1);
System.out.println(p2);
}
}
范例2:大数操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22package cxy.zy.demo;
// 所谓的大数据操作就是指,数字超过了基本数据类型的取值范围,此时就不能使用基本数据类型进行数据操作了。
// 在Java中使用了对象的形式进行大数操作,有两个常用的类。
// BigInteger 操作整数
// BigDecimal 操作小数
// BigInteger和BigDecimal都是java.math包中的类,它们都继承自java.lang.Number。
import java.math.BigInteger;
public class Demo {
public static void main(String[] args) throws Exception {
String num = new String("99999999999999999999999999");
BigInteger big1 = new BigInteger(num);
BigInteger big2 = new BigInteger(num);
System.out.println("加法操作: "+big1.add(big2)); //加法运算
System.out.println("减法操作: "+big1.subtract(big2));//减法运算
System.out.println("乘法操作: "+big1.multiply(big2));//乘法运算
System.out.println("除法操作: "+big1.divide(big2));//除法运算
// 有余数的除法运算
BigInteger[] result = big1.divideAndRemainder(big2);
// 第一个数代表商 第二个数代表余数。
System.out.println("商为: "+result[0]+"\t余数为: "+result[1]);
}
}
范例3:大数操作2。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28package cxy.zy.demo;
import java.math.BigDecimal;
public class Demo {
// 加法运算
public static BigDecimal oper(BigDecimal num1, BigDecimal num2,char op){
BigDecimal result = null;
switch(op){
case '+': result = num1.add(num2) ;break;
case '-': result = num1.subtract(num2) ;break;
case '*': result = num1.multiply(num2) ;break;
}
return result;
}
// 除法运算 scale 指定保留的小数位数。BigDecimal.ROUND_HALF_UP 进行四舍五入。
public static BigDecimal divide(BigDecimal num1, BigDecimal num2 ,int scale){
return num1.divide(num2,scale,BigDecimal.ROUND_HALF_UP);
}
public static void main(String[] args) throws Exception {
BigDecimal big1 = new BigDecimal("1231231.23");
BigDecimal big2 = new BigDecimal("12523.12");
System.out.println("相加:"+oper(big1,big2,'+'));
System.out.println("相减:"+oper(big1,big2,'-'));
System.out.println("相乘:"+oper(big1,big2,'*'));
// 将计算结果保留2位小数。
System.out.println("相除:"+divide(big1,big2,2));
}
}
国际化类
一个经过国际化的处理后软件,会根据用户的国家(语言)不同,在软件的按钮、菜单上面使用不同的文字,以及对日期、货币的显示格式进行转换。
国际化又称为 i18n:单词internationalization 中i和n之间有18个字符 。
国际化操作有两种:
固定文本元素国际化:对按钮、菜单的文字进行国际化。
动态文本元素国际化:对日期、数字、消息进行国际化。
Locale
既然国际化程序,考虑的是适应各个国家语言要求,那么首当其冲的一个问题就是,如何表示一个国家。 在Java中使用java.util.Locale类就可以完成这个任务。
范例1:中美关系。1
2
3
4
5
6
7
8
9
10
11
12
13
14import java.util.Locale;
public class LocalDemo1 {
public static void main(String[] args) {
// 第一个参数,是两位小写的字母,代表语言。
// 第二个参数,是两位大写的字母,代表国家或地区。
// 中文(台湾): zh_TW
// 中文(香港特别行政区):zh_HK
// 需要注意的是:Locale对象本身并不会验证它代表的语言和国家地区信息是否正确 。
Locale china = new Locale("zh","CN"); // 中文_中国
Locale usa = new Locale("en","US"); // 英语_美国
System.out.println(china);
System.out.println(usa);
}
}
范例2:省点力气。1
2
3
4
5
6
7
8import java.util.Locale;
public class LocalDemo1 {
public static void main(String[] args) {
// 获得此Java虚拟机实例的当前默认语言环境值。
Locale china = Locale.getDefault();
System.out.println(china);
}
}
固定文本元素
如果想要实现国际化,光靠Locale是不够的,还需要配置多个属性文件。每个属性文件代表一个国家的语言,其内保存了一套完整的用于在按钮、菜单上面显示的文字,当程序执行时,程序根据用户计算机当前的语言,从不同的属性文件中,读取文字,然后显示到按钮、菜单上面。
所谓的属性文件,就是指后缀名为“*.properties”的文件。
范例1:配置文件。1
2
3
4
5
6
7
8
9
10
11
12// hi_en_US.properties文件。
// 属性文件的命名规则:基名_语言_国家.properties 。
// 基名:多个属性文件的文件名中共有的那部分。本范例中基名:hi 。
// 属性文件中 “=”号左边的被成为“key(键)”,右边的被成为“value(值)” 。
// 在程序中,通过指定某个key来访问所对应的value。
button=A Button!
// hi_zh_CN.properties文件。
// 在properties文件中不允许出现汉字,因此若想使用汉字则需要将汉字转换成Unicode编码。
// 可以使用“jdk1.6.0_06\bin\native2ascii.exe”文件,来对汉字进行编码,然后将编码的结果存入properties文件中去即可。
button=\u6211\u662F\u4E00\u4E2A\u6309\u94AE\!
范例2:访问文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import java.util.Locale;
import java.util.ResourceBundle;
// 配置完属性文件后,就可以在程序中,根据用户的语言环境,来选择不同的属性文件。
// 然后从属性文件读出数据,最终将数据显示给用户看。
public class PropertiesDemo1 {
public static void main(String[] args) {
// 通过ResourceBundle类,来完成对某个属性文件的读取操作。
// 使用指定的基本名称、语言环境和调用者的类加载器获取资源包。
// 文件的名称为:baseName +“_”+ locale.toString() + “.properties”
ResourceBundle rsb = ResourceBundle.getBundle("hi",new Locale("en","US"));
// 若ResourceBundle对象在资源包中找不到与用户匹配的资源文件,它将选择该资源包中与用户最相近的资源文件,如果再找不到,则使用默认资源文件。若仍找不到默认资源文件则抛异常。
System.out.println(rsb.getString("button"));
}
}
动态文本元素
数值,货币,时间,日期等数据由于可能在程序运行时动态产生,所以无法像文字一样简单地将它们从应用程序中分离出来,而是需要特殊处理。
java.text.Format是一个抽象类,其下面有三个常用的子类:
DateFormat :用于格式化日期,此类是SimpleDateFormat的父类。
NumberFormat:用于格式化数字。
MessageFormat:用于批量格式化。
范例1:日期国际化。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import java.text.DateFormat;
import java.util.Date;
public class DateFormatDemo {
public static void main(String[] args) {
// 获得日期格式化对象。
// 将Date对象的日期部分抽出来显示。
DateFormat date = DateFormat.getDateInstance();
// 将Date对象的时间部分抽出来显示。
DateFormat time = DateFormat.getTimeInstance();
// 将Date对象的日期和时间部分抽出来显示。
DateFormat dateTime = DateFormat.getDateTimeInstance();
// 获得当前时间。
Date current = new Date();
// 使用格式化对象对当前日期进行格式化。
System.out.println("当前日期:"+date.format(current));
System.out.println("当前时间:"+time.format(current));
System.out.println("当前日期+当前时间:"+dateTime.format(current));
// 程序执行结果:
// 当前日期:2011-9-7
// 当前时间:1:46:18
// 当前日期+当前时间:2011-9-7 1:46:18
}
}
范例2:指定显示风格。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35package org.cxy.i18n;
import java.text.DateFormat;
import java.util.Date;
public class DateFormatDemo {
public static void main(String[] args) {
// 获得日期格式化对象。
DateFormat date1 = DateFormat.getDateInstance(DateFormat.SHORT);
DateFormat date2 = DateFormat.getDateInstance(DateFormat.MEDIUM);
DateFormat date3 = DateFormat.getDateInstance(DateFormat.LONG);
DateFormat date4 = DateFormat.getDateInstance(DateFormat.FULL);
// 获得当前时间。
Date current = new Date();
// 使用格式化对象对当前日期进行格式化。
System.out.println("当前日期:"+date1.format(current));
System.out.println("当前日期:"+date2.format(current));
System.out.println("当前日期:"+date3.format(current));
System.out.println("当前日期:"+date4.format(current));
// 程序执行结果:
// 当前日期:11-9-7
// 当前日期:2011-9-7
// 当前日期:2011年9月7日
// 当前日期:2011年9月7日 星期三
}
}
// 相应的时间也有四种格式:
// 当前日期:上午1:50
// 当前日期:1:50:13
// 当前日期:上午01时50分13秒
// 当前日期:上午01时50分13秒 CST
DateFormat date1 = DateFormat.getTimeInstance(DateFormat.SHORT);
DateFormat date2 = DateFormat.getTimeInstance(DateFormat.MEDIUM);
DateFormat date3 = DateFormat.getTimeInstance(DateFormat.LONG);
DateFormat date4 = DateFormat.getTimeInstance(DateFormat.FULL);
范例3:指定国家。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27package org.cxy.i18n;
import java.text.DateFormat;
import java.util.Date;
import java.util.Locale;
public class DateFormatDemo {
public static void main(String[] args) {
// 美国。
Locale locale = new Locale("en","US");
// 获得日期格式化对象。
DateFormat date1 = DateFormat.getDateInstance(DateFormat.SHORT,locale);
DateFormat date2 = DateFormat.getDateInstance(DateFormat.MEDIUM,locale);
DateFormat date3 = DateFormat.getDateInstance(DateFormat.LONG,locale);
DateFormat date4 = DateFormat.getDateInstance(DateFormat.FULL,locale);
// 获得当前时间。
Date current = new Date();
// 使用格式化对象对当前日期进行格式化。
System.out.println("当前日期:" + date1.format(current));
System.out.println("当前日期:" + date2.format(current));
System.out.println("当前日期:" + date3.format(current));
System.out.println("当前日期:" + date4.format(current));
}
}
// 程序执行结果:
// 当前日期:9/7/11
// 当前日期:Sep 7, 2011
// 当前日期:September 7, 2011
// 当前日期:Wednesday, September 7, 2011
范例4:数字国际化。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import java.text.NumberFormat;
// NumberFormat可以将一个数值格式化为符合某个国家地区习惯的数值字符串,也可以将符合某个国家地区习惯的数值字符串解析为对应的数值。
public class NumberFormatDemo {
public static void main(String[] args) throws Exception {
// 货币显示对象。
NumberFormat format1 = NumberFormat.getCurrencyInstance();
// 通用数值显示对象。
NumberFormat format2 = NumberFormat.getInstance();
// 整数显示对象。
NumberFormat format3 = NumberFormat.getIntegerInstance();
double num = 1200000000;
System.out.println("货币:"+format1.format(num));
System.out.println("整数:"+format3.format(num));
System.out.println("通用数值:"+format2.format(num));
}
}
// 程序执行结果:
// 货币:¥1,200,000,000.00
// 整数:1,200,000,000
// 通用数值:1,200,000,000
// getCurrencyInstance方法相对于其他两个方法来说比较常用。
// 相应的,也可以将字符串转成数字。
NumberFormat format1 = NumberFormat.getCurrencyInstance();
String str = "¥1200000000";
double num = format1.parse(str).doubleValue();
System.out.println("货币:"+num);
范例5:消息国际化。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 如果一个字符串中包含了多个与国际化相关的数据,可以使用MessageFormat类对这些数据进行批量处理。
// MessageFormat类允许开发人员用占位符替换掉字符串中的数据。
import java.text.MessageFormat;
public class MessageFormatDemo {
public static void main(String[] args) throws Exception {
// 创建一个“消息”,其中使用了占位符。
// 占位符的编号从0开始,调用format方法时会自动将传递过去的Object[]中的数据依次放到占位符中去,其实就是进行了字符串替换。
String pattern = "Hi,{0}! 好久不见,{1}你中了{2}万大奖呢!";
MessageFormat message = new MessageFormat(pattern);
String name = "Tom";
String date = "2011-1-1年时";
double money = 800000000;
Object[] param = {name,date,money};
System.out.println(message.format(param));
}
}
范例6:消息国际化2。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import java.text.DateFormat;
import java.text.MessageFormat;
import java.util.Date;
import java.util.Locale;
public class MessageFormatDemo {
public static void main(String[] args) throws Exception {
String pattern = "At {0, time, short} on {0, date}, a destroyed'\n'"
+ "{1} houses and caused {2, number, currency} of damage.";
MessageFormat message = new MessageFormat(pattern);
String datetimeString = "Jul 3, 1998 12:30 PM";
Date date = DateFormat.getDateTimeInstance(DateFormat.MEDIUM,
DateFormat.SHORT,Locale.US).parse(datetimeString);
String event = "a hurricance";
Object []msgArgs = {date, event, new Integer(99), new Double(1E7)};
System.out.println(message.format(msgArgs));
// 程序执行结果:
// At 下午12:30 on 1998-7-3, a destroyed
// a hurricance houses and caused ¥99.00 of damage.
}
}
正则表达式
是什么?
正则表达式(英语:Regular Expression、regex或regexp,缩写为RE)。
在讨论正则表达式之前,先复习一下表达式的概念。表达式是由数字、算符、数字分组符号(如括号)、变量等以能求得数值的有意义排列方法所得的组合。在Java中有如下几种表达式:1
2
3
4
5
6// 算术表达式 如: 3 * 4
// 关系表达式 如: 3 > 4
// 赋值表达式 如: a = 4
// 逻辑表达式 如: 3 == 4
// 条件表达式 如: 3 > 4? true : false
// 位运算表达式 如: 3 | 4
在计算机科学中,正则表达式是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。正则表达式和普通表达式的异同点:

因此简单地说,正则表达式主要用来进行字符串匹配和替换的。
也许你早已用过它:
在Windows中打开“我的电脑”后,点击工具栏上的“搜索”按钮,然后输入“文件的名称”并选择查找的目录后,系统就会在你指定的目录下搜索你想要的文件。
在你输入的“文件的名称”中是可以使用通配符(wildcard) : * 和 ? 。
若你想查找某个目录下的所有的Word文档的话,你会搜索*.doc,它的含义是查找出所有名称是以“.doc”为结尾的文件或目录。 在这里,*会被解释成任意的字符串。正则表达式中所使用的各种符号,比起这些简单的通配符来说,它们能更精确地描述你的需求,当然代价就是更复杂。
它是如何工作的?
与正则表达式相对应,存在有相应的“正则表达式引擎”,由“正则表达式引擎”来负责解析正则表达式,程序员只需要写出正则表达式即可。
在很多文本编辑器或其他工具里,正则表达式通常被用来“检索”或“替换”那些符合某个模式的文本内容,许多程序设计语言都支持利用正则表达式进行字符串操作。
基本用法
在Java中也是支持正则表达式的,可以通过有两种方式进行正则匹配:
通过String类,进行简单的正则匹配。
通过java.util.regex包提供的对正则表达式支持的两个类(Pattern类和Matcher类),用于进行更复杂的匹配操作。
本节将先以String类为例进行讲解。
在使用正则表达式匹配字符串时,需要提供两个参数,一个是正则式,一个是待匹配串。
范例1:最简单的正则表达式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 通配符,在正则表达式中也被称为元字符(metacharacter),在正则表达式中提供了很多元字符,接下来会一一介绍。
public class Test {
public static void main(String[] args) {
String regexExpress = "hi"; // 正则式。
String str1 ="hi";// 匹配串。
String str2 ="Hi";// 匹配串。
String str3 ="hi world, hi java!";// 匹配串。
// 判断str是否符合regexExpress的要求。
// matches()方法,只有在“匹配串”完全满足“正则式”的情况下才会返回true。
// 本范例中没有使用任何的元字符,它只用来判断待匹配串的内容是否是“hi”,所以需要二者完全相等。
System.out.println(str1.matches(regexExpress));//true
System.out.println(str2.matches(regexExpress));//false
System.out.println(str3.matches(regexExpress));//false
}
}
// 下面是String类提供的与正则表达式相关的API。
// 告知此字符串是否匹配给定的正则表达式。
public boolean matches(String regex)
// 使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。
public String replaceAll(String regex,String replacement)
// 使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串。
public String replaceFirst(String regex,String replacement)
// 根据给定正则表达式的匹配拆分此字符串。
public String[] split(String regex)
在正则表达式中预定义了一些具有特殊意义(即有语法意义)的字符,使用这些字符可以方便的进行匹配操作。预定义字符类的元字符有如下几个:

范例2:元字符“\d”。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class Test {
public static void main(String[] args) {
// 由于“\”在Java中有语法意义,因此需要将“\d”写成“\\d”。
// 元字符“\\d”只用来匹配一位数字。
String regexExpress = "\\d";
String str1 ="1";// 匹配串。
String str2 ="a";// 匹配串。
String str3 ="我";// 匹配串。
String str4 ="123";// 匹配串。
System.out.println(str1.matches(regexExpress));//true
System.out.println(str2.matches(regexExpress));//false
System.out.println(str3.matches(regexExpress));//false
System.out.println(str4.matches(regexExpress));//false
// 元字符“\\D”只用来匹配一位数字。
// 另外对于“\s、\S、\w、\W”都是一样的用法。
regexExpress = "\\D";
str1 ="1";// 匹配串。
str2 ="a";// 匹配串。
str3 ="我";// 匹配串。
str4 ="a23";// 匹配串。
System.out.println(str1.matches(regexExpress));//false
System.out.println(str2.matches(regexExpress));//true
System.out.println(str3.matches(regexExpress));//true
System.out.println(str4.matches(regexExpress));//false
}
}
但是,若是只会使用这些预定义的字符类,则可能会遇到一些麻烦。比如:
范例2:匹配5个数字。1
2
3
4
5
6
7
8
9
10public class Test {
public static void main(String[] args) {
// 若是要匹配100个数字呢? 就目前的情况来看,咱们只有去乖乖的写上100个“\\d”。
String regexExpress = "\\d\\d\\d\\d\\d";
String str1 ="1234";// 匹配串。
String str2 ="43254";// 匹配串。
System.out.println(str1.matches(regexExpress));//false
System.out.println(str2.matches(regexExpress));//true
}
}
Greedy数量词用来指定其所修饰的正则表达式所要连续出现的次数。

范例3:判断一个字符串是否由数字组成。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class Test {
public static void main(String[] args) {
// 在正则式的后面直接加上一个Greedy数量词即可。
String regexExpress = "\\d+";
String str1 ="1234";// 匹配串。
String str2 ="43254";// 匹配串。
System.out.println(str1.matches(regexExpress));//true
System.out.println(str2.matches(regexExpress));//true
// 所有长度x的满足:3<= x <=4的,并且在其内只包含有字母、数字、下划线的字符串,都将被匹配。
// 相应的“\\w{3,}”只需要满足长度>=3且其内只包含有字母、数字、下划线即可。
regexExpress = "\\w{3,4}";
str1 ="1234";
str2 ="abc";
String str3 ="a2_d";
String str4 ="abcde";
System.out.println(str1.matches(regexExpress));//true
System.out.println(str2.matches(regexExpress));//true
System.out.println(str3.matches(regexExpress));//true
System.out.println(str4.matches(regexExpress));//false
}
}
范例4:匹配汉字。1
2
3
4
5
6
7
8
9
10public class Test {
public static void main(String[] args) {
// 使用“.”表示任何字符,但是只表示一位任何字符,强调字符类型。
// 使用“*”表示任意多个字符,强调字符数量。
// 使用“.*”表示任意多位任意字符。
String str = "cxy紫zy";
String pattern = ".*紫.*" ;
System.out.println(str.matches(pattern));
}
}
若是需要枚举出多个字符,则可以使用字符类的元字符。
[] 若待匹配字符 是中括号里列出的任意一个字符,则返回true。
[^] 若待匹配字符 不是中括号里列出的任意一个字符,则返回true。
若需要指定一个范围(集合),则可以使用“开始字符-结束字符”来表示。
依据上面的元字符,我们可以写出如下正则式:
[a-z0-9A-Z] 若待匹配字符是a~z、A~Z、0~9之间则返回true。
[a-d[m-p]] 若待匹配字符是a~d或者m-p之间则返回true。即此处将“[m-p]”视为一个子集合,即并集。
[a-z&&[def]] 若待匹配字符是d、e、f则返回true,即取集合“a-z”与集合“def”的交集。
[a-z&&[^bc]] 若待匹配字符是a~z之间且不是b、c则返回true。
此正则等价于:[ad-z],即由a和d-z组成的集合。即差集。
[a-z&&[^m-p]] 若待匹配字符是a~l或q~z之间则返回true。
范例5:“[]”元字符。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class Test {
public static void main(String[] args) throws Exception {
// 只要待匹配串中的字符是“[]”中列出的任意一个,则视为匹配成功。
// 字符类的元字符,同样是只会匹配一位。
String regexExpress = "[abcd123]";
// 相应的也可以加上Greedy数量词:“[abcd123]+”。
// 含义为:待匹配串的长度>=1的且待匹配串内的每个字符都必须是已在“[]”中列出来的。
String str1 ="123";// 匹配串。
String str2 ="a";// 匹配串。
String str3 ="2";// 匹配串。
String str4 ="我";// 匹配串。
System.out.println(str1.matches(regexExpress));//false
System.out.println(str2.matches(regexExpress));//true
System.out.println(str3.matches(regexExpress));//true
System.out.println(str4.matches(regexExpress));//false
}
}
// 限制只能由数字、下划线、字符组成,且第一位不能是数字,且总长度必须在6~16位之间。
String regexExpress = "[a-z_A-Z]\\w{5,15}";
// 在“[]”中可以指定一个字符范围,范围的起止字符之间使用“-”符号即可,如[0-9]。
// 值得注意的是,只有在“[]”的内部,连字符“-”才被视作位元字符,否则它就只能匹配普通的连字符号。
// 其实即使在“[]”内部,“-”也不一定就是元字符,若在连字符两端只有一端有字符(如:“[-ab]”)或者两端都没有(如:“[-]”),则它表示的就只是一个普通的字符,而不是一个范围,而且顺序也不可以乱,如“[z-a]”是错误的。
// 同样的道理,问号和点号通常被当作元字符处理,但是在字符组中则不是如此。
// 如:“[.+?]”可以匹配成功下面的字符串。
String str =".";
若是想匹配元字符本身的话,比如“.”或者“*”,那么就得使用“\”来取消这些字符的特殊意义。也就是说应该使用“\.” 和“\*”,当然要查找“\”本身,你也得用“\\”。
范例6:字符转义。1
2
3
4
5
6
7
8
9public class Test {
public static void main(String[] args) throws Exception {
String regexExpress = "\\\\"; // 正则式。
String str1 ="\\\\";// 匹配串。
String str2 ="\\";// 匹配串。
System.out.println(str1.matches(regexExpress));//false
System.out.println(str2.matches(regexExpress));//true
}
}
范例7:或运算。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 正则表达式支持“或”运算。
// 与“[]”类似,或运算也是提供几种规则,如果满足其中任意一种规则都视为匹配成功,具体方法是用“|”把不同的规则分隔开。
// 使用或运算时,要注意各个条件的顺序。因为匹配时,将会从左到右地测试每个条件,如果满足了某个条件的话,就不会去再管其它的条件了。
public class Test {
public static void main(String[] args) {
String regexExpress = "abc|1234|ak47"; // 正则式。
String str1 ="abc";// 匹配串。
String str2 ="1234";// 匹配串。
String str3 ="ak47";// 匹配串。
String str4 ="asdfghjkl";// 匹配串。
System.out.println(str1.matches(regexExpress));//true
System.out.println(str2.matches(regexExpress));//true
System.out.println(str3.matches(regexExpress));//true
System.out.println(str4.matches(regexExpress));//false
}
}
组
在正则表达式中,组本质上也是一个正则式,它是由一个或多个基本正则表达式组合在一起形成的一个大的正则式。
范例1:捕获组。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class Test {
public static void main(String[] args) throws Exception {
// 以字符“a”开头,中间出现1~n个数字,并以“abc”结尾。
String regexExpress = "a\\d+abc";
String str1 = "a2abc";
String str2 = "a3ab";
System.out.println(str1.matches(regexExpress)); // true
System.out.println(str2.matches(regexExpress)); // false
// 使用“()”来将一段正则式括起来后,这段正则式就可以被称为一个组了。
// 在正则式中,组有捕获组和非捕获组之分,下面定义了3个捕获组。
// 捕获组并不会影响正则式的匹配,其作用和上面的正则式一样。
// 捕获组的作用是将正则式匹配到的内容保存到组里,供以后使用。
regexExpress = "(a)(\\d)+(abc)";
System.out.println(str1.matches(regexExpress)); // true
System.out.println(str2.matches(regexExpress)); // false
// 正则式中的每个捕获组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推,分组0对应整个正则表达式。
// 通过“\组号”可以引用捕获组捕获到的内容,这种引用方式被称为“反向引用”。
// 下面的“\\1”就是引用“(a)”捕获到的内容。
regexExpress = "(a)(\\d)+\\1";
str2 = "a322a";
System.out.println(str1.matches(regexExpress)); // false
System.out.println(str2.matches(regexExpress)); // true
}
// 关于反向引用(也称为后向引用)有两个点需要知道:
// 后向引用不能用于它自身,比如“([abc]\\1)”是错误的;因此你不能将“\\0”用于一个正则表达式匹配本身,它只能用于替换操作中。
// 后向引用不能用于字符集内部,比如“(a)[\\1b]”中的“\\1”并不表示后向引用,在字符集内部“\\1”可以被解释为八进制形式的转码。
}
范例2:命名捕获组。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class Test {
// 当正则表达式比较复杂的时候,里面含有大量的捕获组和非捕获组。
// 通过从左至右数括号来得知捕获组的组号也是一件很烦人的事情,
// 而且这样做代码的可读性也不好,当正则表达式需要修改的时候也会改变里面捕获组的组号。
public static void main(String[] args) throws Exception {
// 在正则式的前面,使用“?<组名>”的语法来给组命名
// 使用“\\k<组名>”的方式引用组。
String regexExpress = "(?<group1>a)(\\d)+\\k<group1>";
String str1 = "a2abc";
String str2 = "a322a";
System.out.println(str1.matches(regexExpress)); // false
System.out.println(str2.matches(regexExpress)); // true
// 输出:中c国
str2 = "中a322a国";
System.out.println(str2.replaceAll(regexExpress,"c"));
}
}
范例3:捕获组特殊用法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class Test {
public static void main(String[] args) {
// 在本范例中,量词“{3}”用在了“good”上,若是去掉“()”,则将会用在“d”上。
// 假设有正则式:“4th|4”,则可以化简为“4(th)?”。
// 即括号内的表达式可以任意复杂,但是“从括号外来看”它们是个整体。
String regexExpress = "(good){3}";
String str1 ="goodgoodgood";
String str2 ="gooddd>";
System.out.println(str1.matches(regexExpress));//true
System.out.println(str2.matches(regexExpress));//false
// 匹配邮箱
// 使用“()”可以限制“|”的作用范围。
String regexExpress = "\\w+@[a-zA-Z]+\\.(com|com.cn|net|edu|gov|org)";
String str1 ="123d@qq.com";
System.out.println(str1.matches(regexExpress));//true
}
}
范例3:非捕获组。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// 正则表达式引擎会把匹配到的结果保存到一个捕获组里。
// 而有时候我们只是想用“()”进行分组操作,并不需要保存这部分内容的。
// 这就带来一定的副作用,浪费了系统资源,降低了效率。
// 此时就可以使用非捕获组。
public class Test {
public static void main(String[] args) {
// 使用“(?:)”来定义一个非捕获组。
// 由于非捕获组不会捕获内容,也不会拥有组号,因此第一个正则表达式会失配。
String regexExpress = "(?:\\d{1})\\1"; // 正则式。
String regexExpress2 = "(\\d{1})\\1"; // 正则式。
String str1 ="22";
System.out.println(str1.matches(regexExpress));//false
System.out.println(str1.matches(regexExpress2));//true
// 从执行结果可以看出,虽然“(?:\\d{2})”左右两侧都有捕获组,但仍然没有被分配组号。
regexExpress = "(\\d{1})(?:\\d{2})(\\w{1})\\2";
System.out.println("123aa".matches(regexExpress));//true
System.out.println("123ab".matches(regexExpress));//false
}
}
零宽断言
在正式介绍零宽断言之前,先说说“缝隙”的概念:
“缝隙”是零宽度的,它只是字符串中的一个位置,而不是实际的字符。
比如在字符串“ab”中就存在有三个“缝隙”,如下图所示:
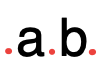
字符“a”前面,“a”和“b”中间以及“b”后面,分别有一个“缝隙”。
在正则表达式中,零宽断言用于匹配缝隙,这个缝隙应该满足一定的条件(即满足断言),只有当断言为真时才会继续进行匹配。使用零宽断言匹配到某个(或某些个)缝隙后,我们就可以在该缝隙上插入若干个字符,从而达到通过正则表达式来修改字符串的目的。
零宽断言又分两类共四种,它们都属于非捕获组:
lookahead:零宽度正预测先行断言、零宽度负预测先行断言。
lookbehind:零宽度正回顾后发断言、零宽度负回顾后发断言。
范例1:零宽度正预测先行断言。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 使用符号“(?=断言表达式)”来定义零宽度正预测先行断言。
// 主要查看缝隙的右侧。
public class Test {
public static void main(String[] args) {
// 在字符串“cooking singing”中总共有16个缝隙。
// 匹配时依次查看每个缝隙,看哪个缝隙的“右侧”是ing,则该缝隙将被匹配成功。
String str1 ="cooking singing";
String regexExpress = "(?=ing)";
// 本范例中“k和i”、“s和i”、“g和i”之间的缝隙将被匹配。
// 输出:cookCing sCingCing
System.out.println(str1.replaceAll(regexExpress,"C"));
// 零宽断言属于预匹配,它的匹配操作是在其他所有字符匹配之前进行的。
// 下面代码的匹配的过程:
// 1、先是对“(?=ing)”进行匹配,并得到3个缝隙。
// 2、在3个缝隙的基础上,查看哪个缝隙的左边还有一个字符“g”。
regexExpress = "g(?=ing)";
str1 ="cooking singing";
//输出:cooking sinCing
System.out.println(str1.replaceAll(regexExpress,"C"));
}
}
范例2:零宽度负预测先行断言。1
2
3
4
5
6
7
8
9
10
11// 使用符号“(?!断言表达式)”来定义零宽度负预测先行断言。
// 与零宽度正预测先行断言对应,“零宽度负预测先行断言”取断言表达式的反值。
// 即如果断言表达式不成立,则匹配这个位置;如果断言表达式成立,则不匹配。
public class Test {
public static void main(String[] args) {
String regexExpress = "(?!\\d)";
String str1 ="1234d5678a";
//输出:1234Cd5678CaC
System.out.println(str1.replaceAll(regexExpress,"C"));
}
}
范例3:零宽度正回顾后发断言。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 使用符号“(?<=断言表达式)”来定义零宽度正回顾后发断言。
// 如果断言表达式成立,则匹配这个位置;如果断言表达式不成立,则不匹配。
// 主要查看缝隙的左侧。
public class Test {
public static void main(String[] args) {
// 匹配的过程:
// 依次查看字符串“abcdefgabc”的每个缝隙,看哪个缝隙的左侧是abc。
// 下面的代码中,“c和d”之间的缝隙 以及“最后一个c后面”的缝隙将被匹配。
String regexExpress = "(?<=abc)";
String str1 ="abcdefgabc";
//输出:abcCdefgabcC
System.out.println(str1.replaceAll(regexExpress,"C"));
// 若正则式为“abc(?<=abc)d”则本范例将输出“Cefgabc”。
}
}
范例4:零宽度负回顾后发断言。1
2
3
4
5
6
7
8
9
10
11
12// 使用符号“(?<!断言表达式)”来定义零宽度负回顾后发断言。
// 与零宽度正回顾后发断言对应,即如果断言表达式不成立,则匹配这个位置,成立则不匹配。
// 主要查看缝隙的左侧。
public class Test {
public static void main(String[] args) {
// 哪一个缝隙的左侧不是数字
String regexExpress = "(?<!\\d)";
String str1 ="1234d5678a";
//输出:C1234dC5678aC
System.out.println(str1.replaceAll(regexExpress,"C"));
}
}
范例5:混合运算。1
2
3
4
5
6
7
8
9
10
11public class Test {
public static void main(String[] args) {
String regexExpress = "(?=\\d)(?<!\\d)";
// 下面的字符串中总共有20个缝隙。
// 执行“(?=\\d)”匹配后,还剩下9个符合要求的缝隙。
// 接着执行“(?<!\\d)”匹配后,还剩下4个符合要求的缝隙。
String str1 ="斯蒂芬3341是分123是否3斯蒂芬3";
// 程序输出:斯蒂芬A3341是分A123是否A3斯蒂芬A3
System.out.println(str1.replaceAll(regexExpress,"A"));
}
}
贪婪和懒惰
范例1:贪婪与懒惰。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Test {
public static void main(String[] args) {
// 当正则式中包含能接受重复的限定符(如Greedy数量词)时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。
// 下面的正则式将会匹配最长的“以a开始,以b结束”的字符串。
String regexExpress = "a.*b";
String str1 ="aabab";
// 输出:W。
System.out.println(str1.replaceAll(regexExpress, "W"));
// 有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。
// 前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号“?”。
// 下面的正则式将会匹配最短的“以a开始,以b结束”的字符串。
// “a.*?b”会匹配aab(第1~3个字符)和ab(第4~5个字符)。
regexExpress = "a.*?b";
str1 ="aabab";
// 输出:WW。
System.out.println(str1.replaceAll(regexExpress, "W"));
}
}
多线程基础
基础知识
程序
程序是一段静态代码,它不占内存空间,不受操作系统调度,不能作为独立的运行单元,也不占用系统的运行资源,只占硬盘空间。
进程
进程是程序的一次执行,程序本身只是一块死代码、指令的集合,程序需要被加载到内存中后,才可以执行,而程序被加载入内存,OS就会为其启动一个进程。
线程
在进程的创建、撤销、切换中,系统必须为之付出较大的时间开销。
因此在系统中设置的进程数目不能过多,进程切换的频率不宜太高,这就限制了并发程度的提高。因此在现代操作系统中,引入了线程。此时进程仅仅是OS进行资源分配的基本单位,调度的基本单位变为了线程。
线程是程序运行的基本单元,线程隶属于进程。
一个进程中可以有多个线程,当一个进程消失了,那么进程中的所有线程都将死亡。
一个线程死亡了,进程却可能仍在运行着,线程不是程序,不能独立运行。
并发
线程的并发执性是指:多个线程轮流执行。由于线程间切换的速度非常快,所以感觉像是同时执行。但并发线程的数量不是越多越好,线程多不但不会提高程序效率,反而会增加CPU在多个线程间切换的时间,这就是一种很大的浪费。
因此迅雷在下载时,最多同时也就能有4~5个任务在执行,其他任务只有等待的份了。
并行
线程的并行执行是指:只有在计算机有多个CPU(或一个CPU有多个核心)时 线程间才可能真正的同时执行。
当程序中有多条执行路径并发执行时,就称为多线程。
所有的线程共享进程最初从内存中申请的空间。 当新建一个线程时,是在进程所占的内存内为其分配空间,而不是在内存中的其他地方,重新为其申请资源。
时间片轮转
OS在执行进程的时候,会不断的为每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程。如果进程在时间片结束前阻塞或结束,则CPU当即进行切换。 在进程中的多个线程同样采用时间片轮转。
每个线程根据优先级来决定谁先占有CPU。
Java主线程
当一个Java程序启动时,JVM会创建主线程,并在该线程中调用程序的main方法。
主线程是程序最早执行的线程,程序中所有的线程都是由主线程创建的。
程序启动时JVM同时还创建了其他线程,如垃圾收集的线程(gc线程)等。
Java中多线程实行抢占式工作方式,若当前就绪的线程中有优先级高于正在执行的线程,则CPU会放弃当前线程的执行,而去执行优先级高的线程,即使当前线程是主线程也不例外。
线程的实现
在Java中有两种方式可以实现多线程,但是不论使用哪种方式都需要用到Thread类。
第一种,直接继承Thread类,然后重写run()方法。
第二种,实现Runnable接口并重写run()方法,然后将此类的对象放到Thread类对象中。
范例1:Thread类实现线程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 在Java中一个Thread类(或其子类)的对象就代表一个线程。
public class MyThread extends Thread {
private String name;
private int i = 1;
public MyThread(String name){
this.name=name;
}
// 线程所要做的事情需要在run方法里,这个run方法继承自Thread类。
public void run() {
for (; i <=3; i++) {
System.out.println(this.name+": i="+i);
}
}
public static void main(String[] args){
MyThread n1 = new MyThread("张三");
MyThread n2 = new MyThread("李四");
// 启动线程需要调用Thread类的start()方法,这个方法负责建立线程。
// 如果线程建立成功,则自动转调用run()方法。
// 在start()方法中除了会转调用run()方法外,还会进行一些其它操作。
// 比如调用操作系统(windows、macOS等)的建立线程函数CreateThread。
// 因此若人为的调用run()方法则并不是启动线程,而仅仅是方法调用。
n1.start();
n2.start();
}
}
范例2:Runnable接口实现线程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 虽然实现了Runnable接口,但是最终还是要将MyThread对象放到Thread类的构造方法。
// 因为必须要调用Thread类的start()方法才能启动线程。
public class MyRunnable implements Runnable {
private int i=1;
// Runnable接口本身并没有任何对线程的支持,它仅提供了线程运行所需要的run方法。
// 也就是说,Runnable接口不止可以用在线程上。
public void run() {
for (; i <=3; i++) {
System.out.println("i="+i);
}
}
public static void main(String[] args){
MyRunnable n = new MyRunnable();
// Thread类本身也实现了Runnable接口。
Thread t1 = new Thread(n);
Thread t2 = new Thread(n);
// 启动线程时,会调用MyRunnable的run方法。
t1.start();
t2.start();
}
}
范例3:Thread类的常用方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public class Test {
public static void main(String[] args) throws InterruptedException {
// 使用Thread类的静态方法currentThread()方法可以得到当前线程的引用。
// 打印一个线程对象的时候默认输出的格式:Thread[线程名,线程优先级,所在线程组]
// 如打印主线程时输出:Thread[main,5,main]
System.out.println(Thread.currentThread());
// Java中每个线程都是有自己的名字的,若不手工指定,则JVM会自动分配一个唯一的名字。
// 在构造Thread对象的同时可以通过Thread类的构造方法来设置线程的名称。
// 也可以使用Thread类的getName()和setName()获得和修改名称。
Thread thread = new Thread(new Runnable() {
public void run() {
String name = Thread.currentThread().getName();
System.out.println(name + ": 我进入了run(),开始睡眠20秒");
try {
// 使用Thread类的静态方法sleep()可以使当前线程睡眠指定的时间。
// sleep方法的参数以毫秒为单位。
// 线程进入睡眠后,CPU会被其他线程占有。
Thread.sleep(20000);
} catch (InterruptedException e) {
// 当前线程睡眠被打断的时候会抛出 InterruptedException异常。
System.out.println(name + ": 我的睡眠被打断了,我很生气!");
return;
}
System.out.println(name + ": 我自然睡醒了");
}
}, "印度阿三");
thread.start();
String name = Thread.currentThread().getName();
System.out.println(name + ": 3秒后我会对你说一句话!");
Thread.sleep(3000);
// 手动唤醒线程的睡眠
thread.interrupt();
System.out.println("请起床!");
}
}
范例4:Thread的优先级。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public class MyThread extends Thread{
public MyThread(String name){
super(name);
}
public void run(){
for(int i=1;i<=3;i++){
System.out.println(Thread.currentThread().getName()+": "+i);
}
}
public static void main(String[] args) throws InterruptedException{
MyThread bug1= new MyThread("虫子1号");
MyThread bug2= new MyThread("虫子2号");
// 在Java中线程的优先级被分为1~10级,也可用三个全局常量表示。
// public static final int MAX_PRIORITY 最高优先级 : 10级
// public static final int MIN_PRIORITY 最低优先级 : 1级
// public static final int NORM_PRIORITY 标准优先级 : 5级
// 通过setPriority()和getPriority()方法来设置和访问线程的优先级。
// 操作系统会先执行优先级高的线程,下面虽然“虫子2号”是后启动的,但是它总是先执行的。
bug1.setPriority(1);
bug2.setPriority(10);
bug1.start();
bug2.start();
}
}
// 线程的优先级高度依赖于OS,当JVM依赖于宿主机平台的线程实现机制时。
// Java线程的优先级会被映射成宿主机平台上的优先级,如 Window NT/XP有7个优先级。
// 因此应该将线程的优先级看作是线程调度的参考因素,千万不要将程序构建为其功能的正确性依赖于线程的优先级,这是十分危险的。
// 但一般来说,当调度器决定挑选一个线程时,都会首先在优先级高的线程中选择。
// Java线程除了能向你保证每一个定义的线程都会被启动,每个启动的线程都会运行到完成,除了这些之外不会有任何保证。
// Java规范中不能百分百保证线程将按照它们调用start()的顺序开始执行。
// 一系列线程以某种顺序启动并不意味着它们将按照该顺序执行。
范例5:强行连接。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class MyThread extends Thread{
public MyThread(String name){
super(name);
}
public void run(){
for(int i=1;i<=3;i++){
System.out.println(Thread.currentThread().getName()+": "+i);
}
}
// main方法中的当前线程就是指的 主线程。
public static void main(String[] args) throws InterruptedException{
MyThread bug1= new MyThread("虫子1号");
bug1.start();
// join方法就是强行连接的意思,使当前线程等待调用此方法的线程死亡后才继续执行。
// 当前线程是:主线程。
// 调用join方法的线程:bug1线程。
// 因此本范例中主线程总是等待bug1执行完run()方法死亡后才继续执行。
bug1.join();
System.out.println("主线程执行");
}
}
范例6:线程让步。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class MyThread implements Runnable{
private int i=1;
public void run(){
for(;i<=3;i++){
System.out.println(Thread.currentThread().getName()+": "+i);
// 使用Thread类的静态方法yield()进行让步操作。
// yield()方法使当前线程放弃本次抢到的CPU,回到就绪状态,从而使其他线程可以运行。
// 但此方法同样没有任何保障,因为让步的线程可能再次被选中。
if(i==2)
Thread.yield();
}
}
public static void main(String[] args) throws InterruptedException{
MyThread my = new MyThread();
new Thread(my).start();
new Thread(my).start();
}
}
Java中线程有五个状态
新建状态
使用 Thread t = new Thread() 语句建立一个线程对象,新线程就处于了新建状态。
此时它只是一个空的线程对象,若要执行它,还需要将这个线程在OS中进行登记并为它分配系统资源,这些工作由start()方法来完成。
就绪状态
当一个线程调用start()方法后,它便进入了就绪状态。但是并不会马上执行,它们会被放到就绪队列中等待执行,何时执行取决于线程的优先级和就绪队列的当前状况。
执行状态
线程被分配到CPU时间片,开始运行run()方法时,线程就处于正在执行状态。
阻塞状态
因为一些原因导致线程需要“等待”,处于“等待”状态的线程就称为“阻塞”。
常见的造成阻塞的原因有:
|- 线程自己调用了sleep()方法进行睡眠。
|- 线程自己调用了wait()方法进行等待。
|- 线程等待用户输入或输出操作时同样会阻塞。
相应的解决方法有:
|- 等待睡眠时间结束或其他线程调用interrupt()方法将其唤醒。
|- 等待它等待的时间结束或其他线程调用notify()、notifyAll()将其唤醒。
|- 等待用户输入或输出结束。
死亡状态
一个线程被创建后只能调用一次start(),当线程完成其run()方法时,该线程不再是一个可执行的线程,该线程的栈已解散,我们就认为该线程死去,一旦一个线程死去,它将永远无法被重新启动,造成线程死亡有如下三种情况:
|- 正常执行完run()方法。
|- 在run()方法中因为一个未捕获的异常终止了run()方法,而使线程猝死。
|- 使用stop()和destroy()终止线程。
线程同步
背景:我们使用private修饰对象的属性 以此来保证此属性只能被本类的方法使用,这个可以防止别人修改重要的变量。
问题:虽然外界不能访问本类的私有变量了,但是本类中的所有方法都能访问到这些变量,那这意味着在多线程的环境中,同一个类内的方法,在同一时间有2个以上的线程对一个变量进行操作,这样变量的值就可能产生错误了。
范例1:卖票。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public class MyThread implements Runnable {
private int token = 5;
public void run() {
for(int i=0;i<50;i++){
if(token>0){
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("卖出一张票,还剩:"+(--token));
}
}
}
public static void main(String[] args) throws InterruptedException {
MyThread my = new MyThread();
new Thread(my).start();
new Thread(my).start();
// 程序运行结束:
// 卖出一张票,还剩:4
// 卖出一张票,还剩:3
// 卖出一张票,还剩:2
// 卖出一张票,还剩:1
// 卖出一张票,还剩:0
// 卖出一张票,还剩:-1
// 如果运行的不是上面的结果 就多执行几遍程序。
// 观察发现最后一次票的余数居然到达了负数,这就是不同步的原因。
// 上面的程序中有2个线程在卖票,假设此时程序中还有最后一张票:
// - 线程A从到if(token>0)进行判断,结果token>0则线程A继续向下走。
// - 线程A执行到sleep方法 进行睡眠300毫秒。
// - 此时线程B获得CPU同样走到if(token>0)进行判断,此时A还在睡眠当中,虽然A通过了检测,已经具备了卖票的资格,但是还没有进行卖票,token还没有减1,结果线程B顺利通过检测,也继续向下走。
// - 线程B执行到sleep方法,进行睡眠300毫秒。
// - 线程A醒来后,卖一张票,此时最后一张票卖完。
// - 线程B醒来后,又卖一张票,此时票数就到负数了。
// 上面的程序线程A和线程B一共执行了100次循环,它们仅仅共享使用成员变量。
}
}
解决问题的方法就是:进行线程同步。
所谓的线程同步就是说,设定一个程序块或者方法,此方法同一时间内只能有一个线程进入,其他线程必须等待那个线程从里面出来后,才能进去。
在Java中可以使用两种方式来实现线程的同步: 同步块和同步方法。
同步块: 使用synchronized关键字修饰的代码块。
同步方法: 使用synchronized关键字修饰的方法。
线程是凌驾于对象之上的,如下图所示:
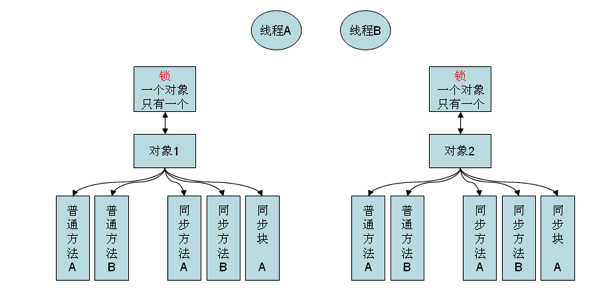
一个类可以有多个对象,一个对象中包含属性和方法,方法按照是否线程安全,则又可以分为普通方法和同步方法:
一个对象内的所有同步方法组成一个小组,这组中的方法,同一时间只能有一个方法被线程访问,其他的同步方法此时会禁止其他线程访问,类似于咱们常见的单选按钮,在多个选项中,同一时刻,只能选择一个选项。
之所以说线程是凌驾于对象之上的,是因为一个线程可以得到多个对象的锁,但是在同一时间点上 一个线程只能拥有一个对象的“锁”,一个对象只有“一把锁”。
所谓的得到对象的“锁” 说白就是:当一个线程进入到对象的某一个同步方法内时,这个线程就得到了这个对象的锁,当此线程从同步方法中出来的时候,就自动释放了锁。
其实就和咱们去厕所一样。当咱们进入到厕所里面的时候,咱们可以将门反锁上,当我们从厕所出来时,总不会把锁也带出来吧? 因此当一个线程进入到一个对象的某一个同步方法中后,这个对象的其他同步方法将拒绝接受其他线程的访问请求,其他线程只能等待这个线程从同步方法中出来。
如果一个对象在同步方法中调用sleep方法进行睡眠,则它会带着锁一起睡眠,即便它睡眠的时候放弃了CPU,别的线程也因此而得到了CPU,但是别的线程因为没有锁,所以还是进不来。因此不要在同步方法中调用sleep()方法。同理,咱们在厕所里睡着了,门会一直被反锁着,别人根本就进不来,虽然他也买到了一张门票,总不可能在咱们睡着的时候,厕所上的锁自动打开吧。
范例1:同步代码块。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class MyThread implements Runnable {
private int token = 5;
public void run() {
for(int i=0;i<50;i++){
// 每一个对象都有一把“锁”,这把“锁”就是在线程同步时用到。
// 只有抢到这把“锁”的线程才有资格进入到此对象的synchronized块或方法中。
// 没有抢到这把“锁”的线程只能等待里面的线程释放锁后才可以继续抢夺“锁”。
// 下面在同步块中调用了sleep方法,因此当前线程会带着“锁”一起睡眠。
// synchronized(this)代表 线程只有抢到当前对象的“锁”后才可以进入到同步块中来。
synchronized(this){
if(token>0){
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()
+ " 卖出一张票,还剩:" + (--token));
}
}
}
}
public static void main(String[] args) throws InterruptedException {
MyThread my = new MyThread();
new Thread(my).start();
new Thread(my).start();
}
}
范例2:同步方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class MyThread implements Runnable {
private int token = 5;
public void run() {
for(int i=0;i<50;i++){
sal();
}
}
// 虽然使用线程同步可以保证数据的正确性,但是同样也降低了程序执行的效率。
// 说白了假设此时有一个任务,如果不使用线程同步需要6秒就能完成。
// 使用线程同步则可能需要8秒才完成,但是相应的安全性也提高了。
// 同步的时候,static方法使用的是当前类的Class类对象。
public synchronized void sal(){
if(token>0){
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("卖出一张票,还剩:"+(--token));
}
}
public static void main(String[] args) throws InterruptedException {
MyThread my = new MyThread();
new Thread(my).start();
new Thread(my).start();
}
}
线程死锁
关于死锁:说白了就是:You first,You first问题。
双方各自持有一个资源,再不想释放已有资源的情况下,还想要对方的资源,谁都不愿意先放手,导致最终相互等待。
比如说:
抢劫犯要求: 你们先给我钱,我放人。
受害者家属要求: 你先放人,我们给你钱。
最终结果就是,相互僵持着。
注:在线程中,过多的同步就很容易导致死锁。
范例1:模拟死锁 —— 警察与绑匪。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79//绑匪类
class Kidnapper extends Thread {
private Trade t;
public Kidnapper(Trade t) {
super("匪徒");
this.t = t;
}
public void run() {
System.out.println(Thread.currentThread().getName()
+ " 说:你们先拿钱来,然后我就放人!");
try {
this.t.policeGiveMoney(); // 向警察要钱。
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 说:好吧,我放人!");
}
}
//警察类
class Police extends Thread {
private Trade t;
public Police(Trade t) {
super("警察");
this.t = t;
}
public void run() {
System.out.println(Thread.currentThread().getName()
+ " 说:你先放人,然后我们给你钱!");
try {
this.t.kidnapperGiveMan(); // 向匪徒要人。
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 说:好吧,你被捕了!");
}
}
//交易类
class Trade {
private boolean giveMoney = false;
private boolean giveMan = false;
/**
* 功能:用来描述匪徒向警察要钱的过程。
*/
public synchronized void policeGiveMoney() throws Exception {
// 警察先判断,当前线程(匪徒)是否已经放人。
if (!this.giveMan) {
// 若匪徒没有放人,则要求匪徒等待,等待其放人后,再给他钱。
wait();
}
// 当匪徒放人后,警察给他钱。
this.giveMoney = true;
// 匪徒唤醒警察, 警察去领人。
notifyAll();
}
/**
* 功能:用来描述警察向匪徒要人的过程。
*/
public synchronized void kidnapperGiveMan() throws Exception {
// 匪徒先判断,当前线程(警察)是否已经给钱。
if (!this.giveMoney) {
// 若警察没有给钱,则要求警察等待,等待其交钱后,再给他人。
wait();
}
// 当警察交钱后,匪徒给他人。
this.giveMan = true;
// 警察唤醒匪徒,匪徒去取钱。
notifyAll();
}
}
//测试类
public class Test {
public static void main(String[] args) {
Trade t = new Trade();
new Kidnapper(t).start();
new Police(t).start();
}
}
为了方便的实现线程同步,才引入第三个类(用于的交易类Trade)。
生产者与消费者
题目:现在有一个桌子,桌子上面最多能放5份菜。
有一个厨师不断的向桌子里添加菜,当桌子满的时候就停止添加。
有一个食客不断的从桌子上拿菜吃,当桌子空的时候就歇会再吃。
范例1:生产者与消费者。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87// 餐桌类
class Desk {
private int maxCount;
private int count;
public Desk(int maxCount) {
this.maxCount = maxCount;
}
// 厨师线程会调用此方法,往餐桌上添加菜。
public synchronized void put() throws Exception {
// 如果桌子上菜满了,则厨师暂时等待
while(count == maxCount) {
// 每一个对象除了有一把锁以外 还具有一个等待区。
// 所有在此对象上调用wait()方法的线程都会被放到这个等待区中去。
// 进入到等待区的线程不会带着锁去等待。
wait();
}
count++;
System.out.println(Thread.currentThread().getName()
+ " 添加了一盘菜 桌上此时还有:"+this.count+"盘菜");
// 唤醒食客线程,开始拿菜
// notify、notifyAll、wait方法是Object类的3个方法。
// 它们只能在同步方法或同步块中使用。
notifyAll();
}
// 食客线程会调用此方法,从桌子上拿菜。
public synchronized void get() throws Exception {
// 如果桌子上没有菜,则食客暂时等待
while (count == 0) {
// 若调用wait()方法的线程不拥有该对象的锁,则抛出异常。
wait();
}
count--;
System.out.println(Thread.currentThread().getName()
+ " 吃了一盘菜 桌上此时还有:"+this.count+"盘菜");
// 唤醒厨师线程,开始做菜
// 当调用notifyAll时并不意味着当前线程这时会放弃其锁,在其离开同步块之前,不会放弃锁。
notifyAll();
}
}
// 厨师类
class Producer implements Runnable{
private Desk desk;
public Producer(Desk desk){
this.desk = desk;
}
public void run(){
// 最多往桌子上添加20次菜。
for(int i= 0 ; i<20; i++){
try{
desk.put();
int time = (int)(Math.random()*1000);
Thread.sleep(time);
}catch(Exception e){
e.printStackTrace();
}
}
}
}
// 食客类
class Consumer implements Runnable{
private Desk desk;
public Consumer(Desk desk){
this.desk = desk;
}
public void run(){
// 最多从桌子上拿20次菜。
for(int i=0 ; i<20; i++){
try {
desk.get();
int time = (int)(Math.random()*1000);
Thread.sleep(time);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
// 测试类
public class Demo {
public static void main(String[] args){
Desk desk = new Desk(5);
Thread t1 = new Thread(new Producer(desk),"厨师");
Thread t2 = new Thread(new Consumer(desk),"食客");
t1.start();
t2.start();
}
}
关于线程还有如下几个知识点:
1、如果是普通对象直接使用new关键字建立对象,而不把这个对象赋值给一个引用变量,则垃圾回收器就会将其回收,然而每个线程对象总是将其登记到OS中,在其run()方法执行完毕之前,它不会被gc回收。同时,若是在某个对象的某个实例方法中开启了线程,则在线程执行完毕之前,该对象也不会被回收。
2、后台线程是在后台为别人提供服务的线程,但当所有非后台线程结束时,即使后台线程还没有结束,程序也将终止,Main线程是非后台线程,gc是一个后台线程。
3、后台线程的子线程自动为后台线程,所谓的子线程就是在当前线程执行时创建的线程,子线程会继承父线程的优先级,而Main线程的优先级是5,因此Java中所有在main方法开始之后建立的线程,默认都是5级优先级。
4、如果线程获得一个对象的锁,之后试图调用同一个对象上的其他同步方法,则完全没有问题。
5、如果一个对象的等待区中有多个线程在等待,则调用notify()方法只会唤醒一个线程,但是不保证以何种顺序选择,如果等待区中没有线程,则不执行任何特殊操作。
Timer
Timer是一个定时器,使用它可以将某个任务设置在指定的时间上执行。
范例1:定时任务。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class Test {
public static void main(String[] args) {
// 定时器对象。
Timer timer = new Timer();
// 向定时器对象中安排一个定时器任务。
// 在Timer类内部有一个任务队列(TaskQueue),定时器会按照先进先出的原则,从队列中依次取出每个任务来执行。
timer.schedule(new TimerTask() {
// 定时器中待执行的任务,使用TimerTask类来描述。
// 当定时器执行某个TimerTask时,会调用其run()方法。
public void run() {
System.out.println("Task Execute!");
}
}, 1000); //定时器会一秒后执行该定时器任务。
}
// TimerTask对象有四个状态:
// TimerTask.VIRGIN:新建状态。
// TimerTask.SCHEDULED:已安排(等待执行)状态。
// TimerTask.EXECUTED:已被执行状态。
// TimerTask.CANCELLED:已被撤销状态。
// TimerTask对象一旦被安排到某个Timer中后,它的状态将被置为SCHEDULED,
// 不论其最终是否被成功执行,该TimerTask对象都将不能再次被安排到任何Timer对象中,
// 因为它已经被识为死亡了。
}
// TimerTask类有一个cancel()方法
// 假设现在有一个TimerTask对象A调用了cancel方法,那么之后的情况,如下所述:
// - 若A当前未被安排到任何Timer中,则其将无法被安排,因为Timer对象只接受状态为TimerTask.VIRGIN的TimerTask对象。
// - 若A已经被安排到某个Timer中,但未执行,则其将永远不会被执行,因为当Timer从任务队列将A取出时,会将A直接抛弃,然后继续执行下一个任务。
// - 若A正在被执行,则任务将会运行完,但永远不会再运行。
另外,在Timer对象中除了包含一个任务队列外,还包含了一个线程对象(TimerThread),该线程对象在Timer被实例化的同时被创建,它的工作就是不断的从任务队列中取出TimerTask,然后执行。当任务队列中暂时没有TimerTask时,则该线程对象将会调用wait()方法进入等待。当程序向Timer中安排新任务时,会同时唤醒该线程对象。
同时,在Timer类中也包含一个cancel()方法,用来终止当前计时器,丢弃所有当前已安排的任务,若当前Timer中存在正在执行的任务,则该任务会继续执行完毕。当Timer对象被终止时,TimerThread对象也会停止运行。
ThreadLocal
假设现有一个功能模块,需要依次调用四个类:A、B、C、D,即调用完A类之后要接着调用B类,B后是C,C后是D。同时还有个变量n,在ABCD4个类中都会用到它,若是将变量n随着程序的执行流程从A类开始依次传递,最后转给D,则代码会很乱。若是这类变量有很多,则这种传递数据的方式就很繁琐。
比较好的解决的方案有如下两种:
使用单例设计模式,将变量n封装起来,并处理线程同步。
使用ThreadLocal类来完成数据的传递。
通过ThreadLocal类,可以将一些变量存放到某个线程对象中,那么只要是这个线程能走到的地方(代码),都可以从线程对象中获取变量的值。
范例1:保存数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48public class Test {
// 假设现在有2个Thread对象t1和t2,2个ThreadLocal对象l1和l2
// t1可以往l1、l2中分别存储一个数据
// l1可以为t1、t2各自存储一个数据
// 也就是说,Thread和ThreadLocal是多对多的关系。
private static ThreadLocal<Object> threadLocal = new ThreadLocal<Object>();
public static void main(String[] args) {
// 第一个线程。
new Thread("张三") {
public void run() {
// 当前线程往threadLocal变量中设置自己的数据
threadLocal.set("年龄:10");
A.print();
}
}.start();
// 第二个线程。
new Thread("李四") {
public void run() {
threadLocal.set("年龄:20");
A.print();
}
}.start();
// 程序输出:
// 张三,年龄:10
// 李四,年龄:20
}
static class A {
public static B b;
public static void print() {
b.print();
}
}
static class B {
public static C c;
public static void print() {
c.print();
}
}
static class C {
public static void print() {
System.out.println(Thread.currentThread().getName()
+ "," + threadLocal.get());
}
}
}
UncaughtExceptionHandler
由于应用程序中总是可能存在隐藏的bug,因而抛出的异常没被捕获也就是再所难免的了。当异常产生后,为了良好的用户体验、及时回收系统资源(如关闭数据库连接等) 以及程序bug的搜集,可以将异常信息上传到服务器端。但是通常情况下,未捕获的异常会被虚拟机接到,且其会第一时间终止程序,并打印出异常的堆栈轨迹。
UncaughtExceptionHandler是Thread类的内部接口,当任意线程中突然发生一个未捕获的异常时,会回调此接口内的方法,在JDK中默认就有一个该接口的实例,咱们可以替换掉该实例,然后当未捕获的异常产生时,咱们的实例中的方法就会被调用。
范例1:异常处理器。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class Test{
public static void main(String[] args)throws Exception{
// 自定义一个异常处理器。
Thread.UncaughtExceptionHandler excHandler
= new UncaughtExceptionHandler() {
public void uncaughtException(Thread t, Throwable e) {
System.out.println("线程发生异常:"+e.getMessage());
System.exit(0);
}
};
// 替换掉Thread类默认提供的实例。
Thread.setDefaultUncaughtExceptionHandler(excHandler);
// 除数为0异常。
System.out.println(1/0);
}
}
JavaIO基础
Java中的IO操作可以分为:
- 对文件本身的操作:使用File类完成。
- 对文件内容的操作:
- 使用字节流、字符流、RandomAccessFile类完成。
- 字节(0、1 组成的二进制码,8个二进制码组成一个字节)流:
- InputStream : 字节输入流顶层抽象类
- OutputStream :字节输出流顶层抽象类
- 字符(字符数据,如字母、汉字)流:
- Reader : 字符输入流顶层抽象类
- Writer : 字符输出流顶层抽象类
- RandomAccessFile类:
- 独立于字节流和字符流,自成一派,可以进行随机读写,此类中有一个文件指针的概念。
IO常用类
File
File类是Object类的直接子类,在java.io包中。
范例1:初探File类。1
2
3
4
5
6
7
8
9
10
11
12
13
14import java.io.*;
public class FileDemo {
public static void main(String[] args){
// 创建一个文件对象,指向D:\a.txt。
// 文件的分隔符应该使用File.separator它自动获取您当前操作系统的文件分隔符。
// 在Linux和Unix中文件分隔符为”/”,而在windows中文件分隔符为”\”。
// 但是Windows的分隔符在java中有语法含义,因此在windows内也支持使用”/”或者”\\”。
File file = new File("D:"+File.separator+"a.txt");
// 上面file对象只是指向了a.txt文件,但并不去检查这个文件是否存在,更别说创建了。
// 只有在使用file对象调用方法时,才会去判断它所指向的文件是否存在。
// File对象既可以指向一个文件也可以指向一个文件夹。
}
}
关于文件的扩展名:
在Windows中文件的后缀名只是为了打开文件更方便,除此之外别无其他作用。使用了后缀可以为该文件指定一个默认打开它的一个程序,如果一个文件没有后缀名或者使用的是操作系统未知的后缀名,则双击该文件的时候,Windows会要求你选择一个打开此文件的应用程序。说白了你可以将一个mp3格式的文件的后缀改成txt格式,只要你不在记事本中改变其中的内容,那么你把它再改回.mp3格式的文件,照听不误。
因此文件的后缀名可以任意修改,且文件的内容不会随着后缀名的改变而改变,也就是说不能通过改变文件的后缀来改变文件的类型。即一个.pdf的文件只能用pdf电子书阅读器来打开,即使你改变它的后缀为txt,然后试图使用记事本来打开他,看到的一定是乱码。
范例2:File类常用方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import java.io.*;
public class FileDemo {
public static void main(String[] args){
File file = new File("D:"+File.separator+"test"+File.separator+"a.txt");
// 判断当前文件对象所指向的文件或文件夹是否在硬盘上实际存在。
if(file.exists()){
// 删除文件
// 若file指向的文件不存在,则不执行任何操作,删除成功则返回true。
// 若使用此方法删除一个文件夹,则文件夹必须为空,否则无法删除。
file.delete();
} else {
// 获取file对象的上一级File对象,即“D:/test”。
File parent = file.getParentFile();
// 依据file对象的路径,创建沿途的各个文件夹,若已经存在则不创建。
parent.mkdirs();
// 创建当前文件对象指向的文件,若文件存在,则不执行任何操作。
file.createNewFile();
}
}
}
// 以下方法,当且仅当当前文件对象指向的文件存在且满足特定条件时才返回true,否则返回false。
// canExecute() :是否可执行。
// canRead() :是否能读。
// canWrite() :是否能写。
// delete() :是否能删除。
// isDirectory() :是否是文件夹。
// isFile() :是否是文件。
// isHidden() :是否是隐藏文件。
范例3:筛选文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import java.io.*;
public class FileDemo {
public static void main(String[] args) throws IOException{
File file = new File("D:"+File.separator);
// 以文件数组的形式返回当前文件夹内所有内容,列出File对象。
// 只能对文件夹调用listFiles方法,若对文件调用,则会返回null。
File[] array = file.listFiles(new FileFilter() {
// JVM负责为file下的所有文件调用一次accept方法。
// 如果accept方法返回true则选中此文件并放到最终返回值数组中,否则则放弃此文件。
public boolean accept(File f){
if(f.getName().endsWith(".txt")){
return true;
}
return false;
}
});
for(File str : array)
System.out.println(str);
}
}
RandomAccessFile
RandomAccessFile可以对文件进行随机读写,一般用于文件断点续传(上传/下载)的场景下。
范例1:进行随机读写数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56import java.io.*;
public class Test {
public static void main(String[] args) throws Exception {
// 当前Java项目的根目录下创建此文件
File file = new File("a.txt");
// 打开文件的模式:
// “r” 以只读方式打开。随后调用任何write方法都将导致抛出IOException。
// “rw” 以读写的方式打开。如果该文件尚不存在,则尝试创建该文件。
// “rws” 以读写的方式打开。如果该文件尚不存在,则尝试创建该文件。
// 写入到此流内的数据或对文件的元数据进行的修改不会被放入缓冲区中,而会立刻被写入磁盘文件中。
// “rwd” 以读写的方式打开。如果该文件尚不存在,则尝试创建该文件。
// 写入到此流内的数据不会被放入缓冲区中,而会立刻被写入磁盘文件中。
RandomAccessFile r = new RandomAccessFile(file, "rw");
// 使用writeXxx()可以写八种基本类型
// 使用readXxx()可以读八种基本类型
r.writeChars("张三");
r.writeInt(30);
r.writeFloat(8000);
r.writeChars("李四");
r.writeInt(33);
r.writeFloat(5200);
r.writeChars("王五");
r.writeInt(43);
r.writeFloat(6200);
// 将文件指针移动到文件开头
r.seek(0);
// 从当前的文件指针所在文职,读取数据
System.out.println("姓名: " + readString(r, 2) + "; 年龄:" + r.readInt() + "; 工资:" + r.readFloat());
// 跳过李四的信息。
r.skipBytes(12);
System.out.println("姓名: " + readString(r, 2) + "; 年龄:" + r.readInt() + "; 工资:" + r.readFloat());
// 用完后要关闭流
r.close();
}
// RandomAccessFile类写字符串有三种方式:
// 1、使用writeBytes()按字节序列将该字符串写入该文件。
// - 该字符串中的每个字符均按顺序写出,并丢弃其高八位。
// - 即写的字符串不能包含汉字,只能写(0-255的字符)。
// - 如果写了汉字,则读取时,一定不能原样读回。
// 2、使用writeChars()按字符的形式将该字符串写入该文件,不会丢其字符的高八位。
// - 它写的所有的字符(包括英文字母)都占2个字节,跳字节时要注意跳的是字符数*2。
// - 所以使用此方式写字符串,最好不要写英文,浪费空间。
// 3、使用writerUTF()按UTF-8编码方式写字符串,要和readUTF()方法配合使用。
// 总之使用RandomAccessFile类要坚持怎么写入,就怎么读取的方式。比如:
// 使用writeBytes()写一个字符串,应该循环使用readByte();
// 使用writeChars()写一个字符串,应该循环使用readChar();
// 使用writeUTF()写一个字符串,应该使用readUTF()读入这个字符串。
public static String readString(RandomAccessFile r, int count) throws IOException {
char[] array = new char[count];
for (int i = 0; i < count; i++)
array[i] = r.readChar();
return new String(array);
}
}
关于文件读写,有几个需要知道的事情:
java.io.EOFException文件读到结尾异常,说白了就是当前所剩字节不够读的。
seek()方法访问底层的运行时系统因此往往是消耗巨大的。
RandomAccessFile类可以通过seek(file.length())跳到文件的最后,达到追加效果。
使用其他字节流输出流指向某个文件,即使没有写任何东西,也会清空文件的内容,使用RandomAccessFile类并不是将原内容清空,而是覆盖,写多少就覆盖多少,未覆盖的则保持不变,因此可以使用seek(file.length())进行追加。
RandomAccessFile类仅能操作文件,不能访问其他IO设备,如网络,内存映像等。
流
关流的概念:
程序中所有的数据传输都不是一次性的将所有数据送出去的,而是一点一点的传输,而计算机的速度又很快,所以读写数据的时候感觉上像是水一样流动一样,因此使用’流’来描述数据的传输。
数据从程序向磁盘写数据时,叫输出流.
数据从磁盘向程序读数据时,叫输入流.
流的分类:
按数据方向分:输入流和输出流
- 输入流:InputStream / Reader
- 输出流:OutputStream / Writer
按数据类型分:字节流和字符流
- 字节流:InputStream / OutputStream
- 字符流:Reader / Writer
按流的功能分:节点流和装饰流(处理流)
- 节点流用来操作数据的来源。它是最基本的操作流。
- 装饰流用来封装节点流,从而给节点流增加一个功能,不能独立存在,在关闭流时如果使用了装饰流,只需关闭最外层的流就可以了。
字节流
字节流的两个顶层抽象类InputStream和OutputStream,其下的流有:
- 文件节点流:FileInputStream和FileOutpuStream。它们是最基本操作文件内容的流类,一般会在节点流外面加上一些装饰流,以增强节点流的功能。
装饰流:
- 字节缓冲流: BufferredInputStream 和 BufferedOutputStream
- 字节数据流: DataInputStream 和 DataOutputStream
范例1:从文件中读写数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import java.io.*;
public class FileDemo {
public static void main(String[] args) throws Exception {
// 使用文件流打开文件时:
// 若文件不存在,则建立这个文件.
// 若文件存在,则删除其内的内容后,再写上新内容。
File file = new File("D:"+File.separator+"a.txt");
FileOutputStream out = new FileOutputStream(file);
// 字符串的getBytes()方法,可以将字符串转成一个字节数组。
out.write("张三".getBytes());
out.write(30);
out.close();
}
// 如果InputStream指向的文件不存在,则会抛FileNotFoundException异常。
// windows中使用\r\n换行,java中使用\n换行,因此向记事本中写数据的时候,如果想在记事本中换行,则需要写一个“\r\n”字符串。
public static void main(String[] args) throws Exception {
File file = new File("D:"+File.separator+"a.txt");
FileInputStream in = new FileInputStream(file);
byte[] array = new byte[4];
for(int i=0;i<array.length;i++){
// 每次读取一个字节
array[i]=(byte)in.read();
}
System.out.println(new String(array));
System.out.println(in.read());
in.close();
}
}
范例2:文件复制。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import java.io.*;
// 缓冲流是一个装饰流,在节点流的基础上添加了一个缓冲区,缓冲区的作用就是 提高流读写的速度。
// 直接用文件流读写文件时,程序每读写一次都需要和外存交互一次,这样触发了大量的底层运行时系统调用是很耗时间的。
// 加入缓冲区后,数据先被读写入缓冲区,缓冲区满了之后,才将进行一次内外存交互,交互的次数减少了,文件读写的速度自然也就快了。
public class FileDemo {
public static void main(String[] args) throws Exception {
BufferedInputStream in =
new BufferedInputStream(new FileInputStream(
new File("D:" + File.separator + "jdk-6u6-windows-i586-p.exe")));
BufferedOutputStream out =
new BufferedOutputStream(new FileOutputStream(
new File("F:" + File.separator + "jdk-6u6-windows-i586-p.exe")));
int temp;
long start = System.currentTimeMillis();
while((temp = in.read())!=-1){
out.write(temp);
}
long end = System.currentTimeMillis();
in.close();
out.close();
System.out.println("耗时:" +(end-start)+"毫秒 大约 "
+(end-start)/1000+" 秒");
}
}
范例3:数据流。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 文件流只提供了最简单的读写数据的方法,当我们需要结构化的读写数据时,就比较麻烦。
// 于是JDK提供了一对结构化读写数据的接口,DataInput和DataOutput,并提供了若干子类。
// 所有实现这俩接口的类,都要遵守一个原则:按什么顺序写,就按什么顺序读。
// 这两个接口的实现类:
// - DataInputSream和DataOutputStream
// - ObjectInputStream和ObjectOutputStream
// - RandomAccessFile
import java.io.*;
public class FileDemo {
public static void main(String[] args) throws Exception {
// 写数据
DataOutputStream out = new DataOutputStream(
new FileOutputStream(new File("D:/a.txt")));
out.writeUTF("Hello World\r\n大家好 我是程序员.");
out.close();
// 读数据
DataInputStream in = new DataInputStream(
new FileInputStream(new File("D:/a.txt")));
System.out.println(in.readUTF());
in.close();
}
}
范例4:打印流。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// PrintStream是一个字节流,既可以作为装饰流也可以作为节点流。
// 其有两个非常著名的实现对象:
// - System.out 标准输出流,向屏幕输出数据。
// - System.err 标准错误流,也会向屏幕输出数据
// 一般来说我们不直接实例化PrintStream类对象,而是直接使用System.out、System.err。
import java.io.*;
public class PrintStreamDemo {
public static void main(String[] args) throws IOException{
PrintStream p=new PrintStream(new File("D:"+File.separator+"a.txt"));
p.print('C');
p.print(123);
p.println("\r\nHello world");
p.printf("\r\n%c,%d,%s", 'A',97,"Hello A!");
p.printf("\r\n%s,%s,%s", 'A',97,"Hello A!");
p.close();
}
// 重定向标准输出流。
// 此时"Hello World"将被输出到文件中。
public static void main(String[] args) throws Exception{
PrintStream out=new PrintStream(new FileOutputStream(
new File("D:"+File.separator+"a.txt")));
System.out.println("Hello World");
System.setOut(out);
System.out.println("Hello World");
}
}
字符流
字符流的两个顶层抽象类Reader和Writer,其下的流有:
- 文件节点流:FileReader和FileWriter。它们是最基本操作文件内容的流类,一般会在节点流外面加上一些装饰流,以增强节点流的功能。
装饰流:
- 字节缓冲流: BufferedReader 和 BufferedWriter
范例1:从文件中读写数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import java.io.*;
public class FileDemo {
public static void main(String[] args) throws Exception {
// FileWriter 支持追加写。
FileWriter out = new FileWriter(new File("D:"+File.separator+"a.txt"));
out.write("世界,你好。\r\nHello World");
// 虽然代码写的是97,但输出到文件中字符’a’。
// 1个int数据占32位,本方法只能写入的低16位中,高16位被忽略。
out.write(97);
out.close();
// 不论是字符流还是字节流,想直接使用节点流读入一个字符串,都稍显麻烦。
FileReader in = new FileReader(new File("D:"+File.separator+"a.txt"));
int temp;
while((temp = in.read())!=-1){
System.out.print((char)temp);
}
in.close();
}
}
范例2:缓冲流。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import java.io.*;
public class FileDemo {
public static void main(String[] args) throws Exception {
BufferedWriter out = new BufferedWriter(new FileWriter(
new File("D:"+File.separator+"a.txt")));
// 写一个字符串
out.write("世界,你好!");
// 写一个换行符
out.newLine();
// 写一个字符串
out.write("Hello World");
out.close();
BufferedReader in = new BufferedReader(new FileReader(
new File("D:"+File.separator+"a.txt")));
// 读一行数据,遇到换行符或者到了文件末尾就停止。
System.out.println(in.readLine());
System.out.println(in.readLine());
in.close();
}
}
范例3:转换流。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26import java.io.*;
// 转换流也属于字符流。
// 它可以将字节流转换成字符流,然后以字符流的方式去操作文件。
// 转换流它包括OutputStreamWriter、InputStreamReader两个类。
public class FileDemo {
public static void main(String[] args) throws Exception {
Writer out = new OutputStreamWriter(new FileOutputStream(
new File("D:"+File.separator+"a.txt")));
out.write("世界你好\r\nHello World\r\n ☆☆☆cxy☆☆☆");
out.close();
Reader in = new InputStreamReader(new FileInputStream(
new File("D:"+File.separator+"a.txt")));
int temp;
while((temp = in.read())!=-1)
System.out.print((char)temp);
in.close();
}
// 从键盘读取一行数据
public static void main(String[] args) throws Exception {
BufferedReader in = new BufferedReader(
new InputStreamReader(System.in));
String info = in.readLine();
System.out.println("输入的信息为:"+info);
}
}
小结
计算机中所有文件都是以字节方式存储的,字符是在内存中形成的。
计算机只认识0、1组成的二进制码,硬盘上存贮的任何文件,也都是用0、1码表示。
所有看到的字符、图片、视频和听到的声音都是经过应用程序转化后的(在内存中形成的)。
比如当使用Windows记事本程序打开一个文件之后,您看到的绝对不是010101码,而是字符。
因为记事本本身也是一个程序,字节被读到内存后经过了记事本的转换。
查看FileReader和FileWriter类的源码,可以发现它们的父类是转换流。
和异常、线程一样,如果父类是一个异常或者线程类,那么子类也同样是一个异常或线程类。
这个概念在流中也同样存在,FileReader和FileWriter的父类是转换流,那么意味着它们两个也同样是转换流。
其实在FileReader和FileWriter的内部就是使用的FileInputStream和FileOutputStream类。
说到这里就可以得到一个结论了:
文件由字节组成,咱们无法直接查看。
字符是在内存中形成的,如果咱们想看字符,则就需要在内存中对字节转换。
但是我们使用FileWriter和FileReader时,并没有去使用转换流,难道是它们自己转换了?
的确是这样的,在我们使用FileWriter和FileReader时这一转换是自动进行的,因为它们是转换流的子类,它们完全有能力去将字节转换成字符。
但是转换操作在什么地方进行? 内存?说的太广泛了吧?
转换在缓冲区进行。
这里说的缓冲区不是指的BufferedReader流,而是另一个用于暂存数据的区域。
也就是说字符流可以使用2个缓冲区,一个是BufferedReader,另一个是字符流自带的一个缓冲区。
为什么有人说“字符流必须得关闭流”?1
2// 此方法用于关闭流,但是关闭流之前,会将缓冲区的数据送出去。
public void close() throws IOException
也就是说:
对于字节流来说,关闭流就是为了安全、程序效率(若不关闭流则系统资源会一直被占用)而做的操作。
对于字符流来说,关闭流除了为了安全外、程序效率,还有一个操作就是,刷新缓冲区。
如果使用字符流时忘了关闭流,那么程序结束时字符流缓冲区的数据都会丢失。
此时就涉及到另一个方法了:1
2
3
4
5
6
7
8
9public abstract void flush() throws IOException
// 此方法来自于Flushable接口,用于刷新缓冲区。
// 其中OutputStream、Writer中实现了此接口,并提供了空实现,而输入流则没有实现此接口。
// 其中:
// FileOutputStream类并没有重写此方法,即其不需要刷新刷冲区。
// BufferedOutputStream类则实现了此方法。
// FileWriter的父类OutputStreamWriter则重写了此方法。
最后说一下:
字节流为了处理字节而生,读取图片、视频、音乐等数据时使用,也可以读取各种数据类型。
字符流为了处理字符,读取文字、符号等文本时使用。
在实际开发中,还是字节流我们使用的比较多,同时为了安全、正确、高效等因素,请关闭所有的流。
对象序列化
所谓的对象序列化,将对象转成字节并保存在硬盘的操作。对象序列化的要求:
- 只有实现了java.io.Serializable接口的类的对象才可以序列化。
- 此接口与Clonezble接口是一样的,接口中并没有任何方法,它只是标识其实现类具备了某种能力。
对象序列化的操作类:
- ObjectOutputStream :进行序列化,将对象转成字节形式写入硬盘。
- ObjectInputStream :进行反序列化,将对象读入内存。
范例1:序列化对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44import java.io.*;
class Person implements Serializable {
private String name;
private int age;
// 使用transient修饰的属性不会被序列化,如将name属性修改为:
// private transient String name;
public Person(String name,int age){
this.name = name;
this.age =age;
}
public String toString(){
return "姓名:"+this.name+"; 年龄: "+this.age;
}
}
public class FileDemo {
public static void main(String[] args) throws Exception {
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream(new File("D:"+File.separator+"a.txt")));
// 序列化对象
out.writeObject(new Person("张三",40));
out.close();
ObjectInputStream in = new ObjectInputStream(
new FileInputStream(new File("D:"+File.separator+"a.txt")));
// 反序列化对象
Person p = (Person) in.readObject();
in.close();
System.out.println(p);
}
}
// 回想一下Object类型的引用变量,是可以接受任意引用类型的对象的。如:
Object obj = new int[22]
// 因此可以利用此特点来序列化一组对象。
// out.writeObject(
// new Person[]{
// new Person("张三",40),
// new Person("李四",42),
// new Person("王五",20)
// });
// 但是反序列化时需要向下转型成数组类型。
Person[] p = (Person[]) in.readObject();
查看”D:\a.txt”文件内容显示为:
sr cxy.zy.io.Personv-邇n I ageL
namet Ljava/lang/String;xp (t 寮犱笁
从文件中大体可以看到,所谓的对象序列化其实序列化的内容是:
包名、类名
类中的属性、属性所在的类,以及属性的取值。
需要注意的是,里面并没有序列化方法:
因为方法都是已经存在的,或者说是固定不变的,而对象间的区别实际上就在于属性上。
对象的属性会被递归序列化的,但是如果某个字段所在类没实现Serializable接口,则该对象将不可以序列化,上例中int和String都实现了Serializable接口。
静态属性不会被序列化。
在序列化对象时要一次性写入完毕:
对象序列化时,会先写入一个头部,然后写入数据,最后加上结束符号。
如果使用追加方式写入的话,那新数据就会在文件末尾继续向下写入。
但是在读取时只会读到第一个结束符就停止,后来再次写入的数据就根本都不到了,若仍然继续读,就会抛StreamCorruptedException异常了,这个异常和EOFException颇为相似,因此以后别用追加的方式序列化对象,要一次性序列化完所有的对象后,再关闭ObjectOutputStream 。
版本控制:
- 在进行对象序列化和反序列化的时候,对于不同JDK版本,会出现版本兼容问题。如在JDK1.5序列化的对象,在JDK1.0上面可能就不能使用了。
- 为了解决对象的序列化和反序列化间的版本不统一问题,引入了一个类常量。
- static final long serialVersionUID
- 在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应的类的class文件中的SerialVersionUID比较
- 如果相同则就认为版本一致,因此可以进行反序列化。
- 如果不相同则就认为版本不一致,然后就抛“序列化版本不一致”异常。
- 在序列化对象的时候,应该为该类创建一个serialVersionUID属性,做为字节码的ID,若是不定义此变量则系统会依据该类内的属性名、属性的标识符等自动生成的一个serialVersionUID,因此若是以后该类的某个字段的名字被修改了,则自动生成的serialVersionUID就不一样了。
其他流类
范例1:内存流。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 前面介绍的各种IO流知识,主要是针对文件的输入输出。
// 但在实际开发中,输入的数据可能来源于网络,输出的数据目的地也不一定是文件。
// 在这种情况下,我们就可能会使用到内存流。
// 所谓的内存流就是ByteArrayInputStream和ByteArrayOutputStream。
import java.io.*;
public class FileDemo {
public static void main(String[] args) throws Exception {
ByteArrayOutputStream byteOut = new ByteArrayOutputStream();
ObjectOutputStream objOut = new ObjectOutputStream(byteOut);
// 将对象序列化到ByteArrayOutputStream中。
objOut.writeObject(new Person("张三",30));
objOut.close();
// toByteArray()方法将ByteArrayOutputStream对象中的内容转成一个byte[]。
// 进行反序列化。
ObjectInputStream in = new ObjectInputStream(
new ByteArrayInputStream(byteOut.toByteArray()));
Person temp = (Person)in.readObject();
in.close();
System.out.println(temp);
}
}
// 其中ByteArrayOutputStream类在Java网络编程时用的比较多,具体后述。
范例2:合并流。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 合并流可以将2个数据源中的内容合并在一起,如将2个记事本的内容合成1个记事本文件。
// 下面2首歌共12MB,如果不使用缓冲区则花费了65秒,使用缓冲区后1328毫秒。
// 操作类SequenceInputStream,它是InputStream的直接子类。
import java.io.*;
public class SequenceDemo {
public static void main(String[] args) throws Exception {
BufferedInputStream buf = new BufferedInputStream(new SequenceInputStream(new FileInputStream(new File("D:/周杰伦 - 你怎么连话都说不清楚 - 演唱会 the one.mp3")),new FileInputStream(new File("D:/周杰伦-回到过去.mp3"))));
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(new File("D:"+File.separator+"total1.mp3")));
int temp;
long start = System.currentTimeMillis();
while( (temp = buf.read())!=-1)
out.write(temp);
System.out.println("耗时: "+(System.currentTimeMillis()-start));
buf.close();
out.close();
}
}
文件压缩
将大文件压缩成小文件,在文件传输的时候可以减少传输时间,常见的文件压缩格式:jar、rar、zip、gz(Unix系统中的)等。
Java中主要支持3种文件的压缩: jar、zip、gzip。
压缩Jar文件涉及到的API:
- JarInputStream和JarOutputStream,分布负责解压缩文件和压缩文件。
- JarFile和JarEntry,分布表示压缩文件和压缩实体。
压缩Zip文件涉及到的API:
- ZipInputStream和ZipOutputStream,与压缩Jar文件作用一样。
- ZipFile和ZipEntry与压缩Jar文件作用一样。
压缩Gzip文件涉及到的API:
- GZIPOutputStream
- GZIPInputStream
各类压缩API的操作方法大同小异,只是使用的压缩流不同而已。
范例1:压缩文件夹。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import java.io.*;
import java.util.zip.*;
public class Demo {
public static void main(String[] args) throws Exception {
// 待压缩的文件夹
File file=new File("D:"+File.separator+"demo");
// 输出的压缩文件
ZipOutputStream zipFile=new ZipOutputStream(new FileOutputStream(file.getParent()+"demo.zip"));
if(file.isDirectory()){
File[] array = file.listFiles();
for(File temp : array){
// ZipEntry表示压缩文件内部的一个压缩项
zipFile.putNextEntry(new ZipEntry(file.getName()+File.separator+ temp.getName()));
FileInputStream sourceFile = new FileInputStream(temp);
int data ;
while( (data=sourceFile.read())!=-1){
zipFile.write(data);
}
sourceFile.close();
}
zipFile.close();
}
}
}
范例2:解压缩文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import java.io.*;
import java.util.zip.*;
public class Demo {
public static void main(String[] args) throws Exception {
File waitUnZipFile=new File("D:"+File.separator+"demo.zip");
ZipFile zipFile=new ZipFile(waitUnZipFile);
ZipInputStream zipInputStream=new ZipInputStream(new FileInputStream(waitUnZipFile));
FileOutputStream out=null;
InputStream in=null;
ZipEntry entry=null;
while((entry=zipInputStream.getNextEntry())!=null){
in=zipFile.getInputStream(entry);
File outFile=new File("D:"+entry.getName());
if(!outFile.getParentFile().exists()){
outFile.getParentFile().mkdir();
}
if(!outFile.exists())
outFile.createNewFile();
out=new FileOutputStream(outFile);
int temp;
while((temp=in.read())!=-1)
out.write(temp);
in.close();
out.close();
}
zipInputStream.close();
}
}
泛型
泛型顾名思义,它代表一个广泛的类型,即它可以代表任意类型,而Object类也可以接受任意类型的对象,也可以代表任意类型。
泛型和Object的区别:
- 泛型代表一个可变的类型,一旦为其指定了一个具体的类型,则泛型就固定了,不能再更改了。
- Object类型代表一个可变的类型,在任何时间、地点都可以接受任何数据类型。
泛型引出
题目:设计一个坐标类。
要求:这个类可以表示Integer、Float、String类型的坐标。
分析:
如果按照以前学习的知识,只能使用Object类来完成此题目,因为只有Object类可以同时接受这三种数据类型。
范例1:有问题的范例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class Point {
private Object x;
private Object y;
public Point(Object x,Object y){
this.x = x;
this.y = y;
}
public Object getX() {
return x;
}
public Object getY() {
return y;
}
}
public class Test {
public static void main(String[] args){
// 传递的是String类型参数
Point p1 = new Point("120E","40N");
// 向下转型为Integer
// 程序运行抛出异常:java.lang.ClassCastException
// 原因是向下转型时出现了错误。
int ix = (Integer) p1.getX();
int iy = (Integer) p1.getY();
System.out.println("x= "+ix+",y= "+iy);
}
}
上面的错误我们一般情况下是不会犯的,但有时候由于程序的代码量十分庞大,同时团队开发的情况下,若A写的代码由B来维护,这样B就很容易不知道某一个对象在此时的具体类型是什么,因此很容易出现类转换错误。
范例2:使用泛型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// 泛型类的定义格式:class 类名<泛型类型>{}
// 下面的泛型类型写的是T,我们可以将T改成A、B、abc、Type等任意名称。
class Point<T> {
private T x;
private T y;
public Point(T x, T y) {
this.x = x;
this.y = y;
}
public T getX() {
return x;
}
public T getY() {
return y;
}
public void setX(T x) {
this.x = x;
}
}
public class Test {
public static void main(String[] args){
// 泛型是在“实例化对象的时候”才为类中的属性、方法,指定具体的数据类型。
// 这样p1中的所有T都会被替换成String。
Point<String> p1 = new Point<String>("120E","40N");
String ix = p1.getX();
String iy = p1.getY();
System.out.println("x= "+ix+",y= "+iy);
// p2中的所有T都会被替换成Integer。
// p1和p2互不干扰。
Point<Integer> p2 = new Point<Integer>(33,11);
int x = p2.getX();
// 如果使用如下代码,则就是编译错误而不是运行错误。
p1.setX(12);
}
}
范例3:不指定泛型(了解)。1
2
3
4
5
6
7
8
9
10
11
12
public class Test {
public static void main(String[] args) {
// 建立对象的时候不指定泛型也不会有编译错误,但是会有警告信息。
// 因为没指定泛型,所以Java按照任意类型来处理泛型,那么此时就又回到了原点。
Point p1 = new Point("120E", "40N");
String x = (String) p1.getX();
String y = (String) p1.getY();
// 如果想消除警告,可以这么写:
Point<Object> p2 = new Point<Object>("120E", "40N");
}
}
通配符
范例1:在泛型中没有向上转型这一概念。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Test {
public static void main(String[] args) {
// 在Java中可以将一个Integer对象赋值给一个Object类:
Object obj = new Integer(23);
Point<Object> p1 = new Point<Object>(12,23);
Point<Integer> p2 = new Point<Integer>(5,2);
// 但是在泛型中下面的代码就是错误的。
p1 = p2;
}
}
// 原因很简单:
// p2是Point<Integer>类型的引用变量,而不是Integer类型的变量。
// p1是Point<Object>类型的引用变量,而不是Object类型的变量。
// 简单的说p1和p2不再是简单的Integer、Object类型了,而变成一个复杂的类型了。
// 因此将一个Point<Integer>类型的对象赋值给Ponit<Object>类型的变量是错误的。
范例2:使用通配符。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Test {
public static void main(String[] args) {
// 下面使用的“?”就称为通配符。
// 它表示可以接受任意“Ponit<T>”类型的对象。
// 需要注意的是Point<?>和Point<Object>是不同的,后者只能接受Point<Object>类型。
Point<?> p1 = new Point<Object>(12,23);
Point<?> p2 = new Point<Integer>(5,2);
p1 = p2;
// 但是通配符是有缺陷的:只能引用不能修改。
Point<?> p3 = new Point<Integer>(12,23);
// 此语句没有问题
System.out.println(p3.getX());
// 编译错误。
p3.setX(2);
}
}
范例3:泛型上限。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 所谓的泛型上限就是限制泛型的取值范围,最高不能超过一个指定的类型。
// 下面限制了T只能是Number和Number子类。
class Point<T extends Number> {
private T x;
private T y;
public Point(T x, T y) { this.x = x; this.y = y;}
public T getX() { return x; }
public void setX(T x) { this.x = x; }
public T getY() { return y; }
}
public class Test {
public static void main(String[] args) {
// 没问题。
Point<Integer> p1 = new Point<Integer>(12,23);
// 编译错误。
Point<String> p2 = new Point<String>("120E","40N");
// 也可以不修改类,直接在实例化的时候设置上限。
Point< ? extends Number> p3 = new Point<Integer>(12,3);
}
// 相应的也可以在方法上设置上限。
public static void fun(Point< ? extends Number> p2){
System.out.println(p2.getX());
}
}
范例4:泛型下限。1
2
3
4
5
6
7// 顾名思义,泛型最低不能低过一个指定的类型。
public class Test {
public static void main(String[] args) {
// 下面限制了T只能是String或String的父类。
Point<? super String> p = new Point<String>("123E","40N");
}
}
泛型方法
所谓的泛型方法,就是在一个非泛型类中定义一个方法,这个方法有点特殊它使用了泛型。
范例1:错误的范例。1
2
3
4
5
6
7
8
9
10// 此类为非泛型类
public class Test {
// 定义一个泛型T。
public void say(T a){
System.out.println(a);
}
}
// 上面的代码会有编译错误,原因很简单:
// 编译器并没有把“T”当成一个泛型,而是做成一个普通的类了。
// 对编译器来说“T”和“String”、“Student”没什么区别,而它找了一圈之后并没有找到T。
范例2:修改代码。1
2
3
4
5
6
7
8
9
10
11
12public class Test {
// 在方法的返回值之前加一个<T>这就算是对T进行定义了。
// 这样一来编译器就知道T是一个泛型了。
public static <T>void say(T a){
System.out.println("say : "+a);
}
public static void main(String[] args){
say("Hello World") ; // 指定方法的泛型为String
say(123); // 指定方法的泛型为Integer
}
}
// 泛型方法的具体类型同样是由外部来指定的,在调用方法的时候指定的。
范例3:方法的返回值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Test {
// 返回值是泛型的写法,和普通方法的返回值一致。
public static <T>T say(T a){
return a;
}
public static <T>T print(T x,T y){
return x;
}
public static void main(String[] args){
String message = say("Hello World");
int i = say(123);
System.out.println(message+" "+i);
// 传递一个double和一个int给方法,编译器会有“类型推测”,自动推测出T的类型为Number。
Number n = print(5.2,2);
}
}
// 当然也可以返回泛型数组。
// public static <T>T[] say(T a)
泛型接口
范例1:定义与使用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42// 定义一个泛型接口
interface Demo<A> {
public void say(A a);
}
// 在Java中实现泛型接口有两种方式:
// 1、类本身也是一个泛型类。
class DemoOper<A> implements Demo<A> {
// 实现接口,但类本身也是泛型类。
public void say(A a){
System.out.println(a);
}
}
// 2、定义类的同时为接口指定泛型的类型。
class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 此范例是在实现泛型接口的同时为接口指定一个具体的类型。
// 相应的在接口中的方法中出现的泛型也要跟着改写。
// 如:
// Comparable接口中的方法原来为:public int compareTo(T o)
// 在此例中被改写为:public int compareTo(Person temp)
public int compareTo(Person temp) {
if (this.age > temp.age)
return 1;
else if (this.age < temp.age)
return -1;
else {
if (this.name.compareTo(temp.name) > 0)
return 1;
else if (this.name.compareTo(temp.name) < 0)
return -1;
else
return 0;
}
}
}
集合
数组:在Java中数组的长度一旦确定就不能更改。
集合:集合就是指一个长度可以变化的类似于(或等于)数组的东西。
- 作用:数组是干什么用的集合就是干什么用的,说白了就是存储数据用的。
- 为什么要用集合?
- 首先,数组长度固定,在实际应用中数组大小不好估计。
- 其次,集合可以提供一些附加的功能,十分利于实际中的开发。如:排序、高速存取、消除重复等。
Java提供的各种集合,主要派生自如下两个接口:
- Collection接口 :特点是数据直接被存在于集合中。
- Map接口 :特点是使用key/value的方式保存数据,通过key来读取value。
Collection接口
Collection接口表示集合,其定义了所有子类共有的一些操作(增删查改等),它是抽象的没办法直接使用,实际开发中我们一般都是用其子接口List和Set的实现类。
List接口的子类存储元素时,允许元素重复。
Set接口则不允许有重复元素。
List接口
List接口的子类按照其内部元素的存储方式分为两大类:
- 数组实现:代表有ArrayList等。当数组容量不足时,会建立一个更大的数组,然后将之前的元素全部copy到新数组中。
- 链表实现:代表有LinkedList等。
范例1:ArrayList。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58import java.util.*;
public class ArrayListDemo {
public static void main(String[] args){
List<String> array = new ArrayList<String>();
// 在最后增加元素
array.add("Hello World");
array.add("世界,你好!");
// 在指定位置增加元素,下标从0开始
array.add(0,"cxy");
// 指定位置删除元素,下标从0开始
array.remove(1);
// 指定元素删除
// 删除时会拿参数对象依次和列表里的每个元素比较,即调用equals()方法比较。
// 因为在String类中重写了equals()方法,所以可以找到并成功删除。
// 若是删除自定义类的对象,在该类没有重写equals()方法的前提下,可能就无法删除。
// 因为会调用Object类的equals()方法,其默认实现是引用变量的值的简单比较。
// 如果不是一个对象的话,就无法删除了。
array.remove("世界,你好!");
// 删除所有元素
array.clear();
// ArrayList类已经重写了toString方法
System.out.println(array);
就会使用Object的equals()方法
}
}
class Person {
private String name;
private int age;
public Person(String name, int age){
this.name = name;
this.age =age;
}
public boolean equals(Object obj){
if(this == obj)
return true;
if(!(obj instanceof Person))
return false;
Person temp = (Person) obj;
if(this.name.equals(temp.name) && this.age == temp.age)
return true;
return false;
}
public String toString(){
return "["+this.name+","+this.age+"]";
}
}
// ArrayList还有如下几个方法:
// 获得指定位置上的元素
array.get(i);
// 判断指定元素是否存在,contains方法也会调用equals()进行比较。
System.out.println(array.contains("Hello World"));
// 截取元素,从0开始到1结束,不包括1。
System.out.println(array.subList(0, 1));
// 元素替换,若下标越界,同样会抛异常。
array.set(1, "踏莎寻");
还有一个名为Vector的类,它的用法与ArrayList一样,不同的是其是线程安全的。
所谓的线程安全就是指,所有的方法都是用synchronized修饰。
前面也说了,使用此关键字修饰的方法同一时间只能被一个线程访问,其他线程必须等待,因此就造成程序执行时间较长的缺点,只有在一些对安全性要求高的场合下才考虑使用Vector类。
范例2:Stack。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// Stack类表示一个栈,其是Vector类的子类,所有的方法也是线程同步的。
// 栈是一种后进先出的数据结构。
import java.util.*;
public class MapDemo {
public static void main(String[] args){
Stack<String> stack = new Stack<String>();
stack.push("No.1");
stack.push("No.2");
stack.push("No.3");
stack.push("No.4");
stack.push("No.5");
System.out.println(stack);
System.out.println("当前栈顶元素为: "+stack.peek());
System.out.println("弹出栈顶元素: "+stack.pop());
System.out.println("当前栈顶元素为: "+stack.peek());
System.out.println("栈是否为空: "+stack.empty());
System.out.println("No.5的位置是: "+stack.search("No.5"));
}
}
范例3:LinkedList。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// LinkedList类表示一个链表,它实现了Queue接口,因而也是一个队列。
// 队是一种先进先出的数据结构。
import java.util.LinkedList;
public class LinkedListDemo {
public static void main(String[] args){
LinkedList<String> line = new LinkedList<String>();
line.add("No.1"); //在表尾增加元素
line.add(0,"No.2"); //在指定位置增加元素
line.push("No.5"); //在表头增加元素
line.addFirst("No.3"); //在表头增加元素
line.addLast("No.4"); //在表尾增加元素
System.out.println(line);
System.out.println("只查看表头:"+line.getFirst());
System.out.println("查看并删除表头:"+line.pop());
System.out.println("只查看表头:"+line.peek());
System.out.println("只查看表尾:"+line.getLast());
System.out.println("查看并删除表尾:"
+line.remove(line.size()-1));
String[] array = line.toArray(new String[]{});
for(String str : array)
System.out.print(str+" ");
}
}
CopyOnWriteArrayList
很多时候,会有多个线程同时操作一个ArrayList,如一个线程执行遍历,一个线程执行添加,但ArrayList的缺点不足以满足我们的需求:
首先,ArrayList提供的方法都是非线程安全的。
然后,ArrayList在通过Iterator接口(后述)遍历其内元素时,不能同时对其进行写操作,所为的“写”指的就是“add、remove”操作,否则就会抛异常。
范例1:ArrayList源码阅读。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// 使用List提供的iterator()方法可以获取一个Iterator接口的实例。
// 这个实例其实是ArrayList内部类Itr的一个实例,该内部类实现了Iterator接口,用于列表遍历。
// 然后在这个Itr的实例上调用next()方法时,就会执行类似于下面的代码。
// 为什么说类似下面的代码? 因为不同版本的jdk中ArrayList的源码是不同的。
// 有的jdk版本中的ArrayList并没有定义iterator方法,而是由其父类AbstractList来定义。
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
// 属性modCount代表ArrayList中当前元素的个数。
// 属性expectedModCount代表Iterator对象创建时,ArrayList中元素的个数。
if (modCount!= expectedModCount)
throw new ConcurrentModificationException();
}
// Vector类虽然是线程同步的,但同样无法遍历的同时执行写操作。
CopyOnWriteArrayList类对ArrayList类的功能进行了扩充,就是解决了上面的问题,接下来笔者简单的介绍一下这个类的实现原理。
首先CopyOnWriteArrayList与ArrayList一样其内使用一个Object[] array保存元素。
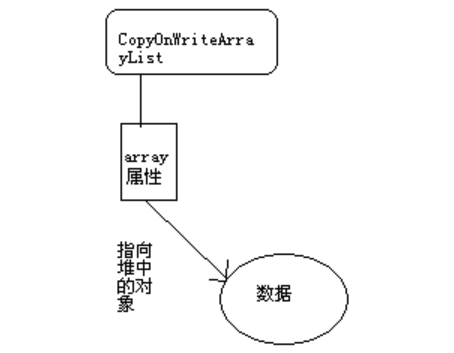
然后用户调用CopyOnWriteArrayList的iterator方法时,该类会创建并返回一个其内部类COWIterator的实例,该实例会使用一个新的引用变量elements来指向外部类的array,用户获取Iterator并调用next()方法获取数据时,都是在上elements(也就是array)调用的。
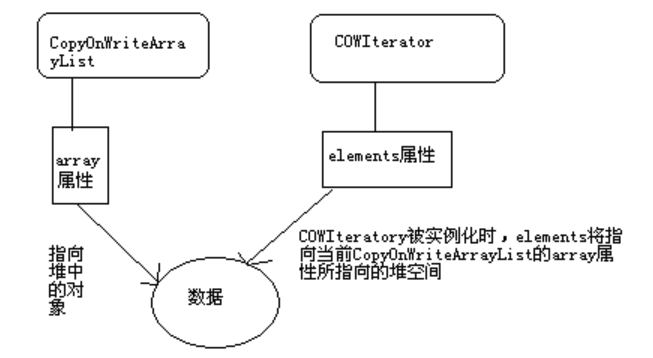
接着CopyOnWriteArrayList在执行所有与“写”操作有关的方法时,都会使用System.arraycopy()或Arrays.copyOf()(依据jdk版本而不同)来创建array的一个副本数组temp,然后在这个副本上执行“写”操作。 执行完毕后,会使array指向temp 。
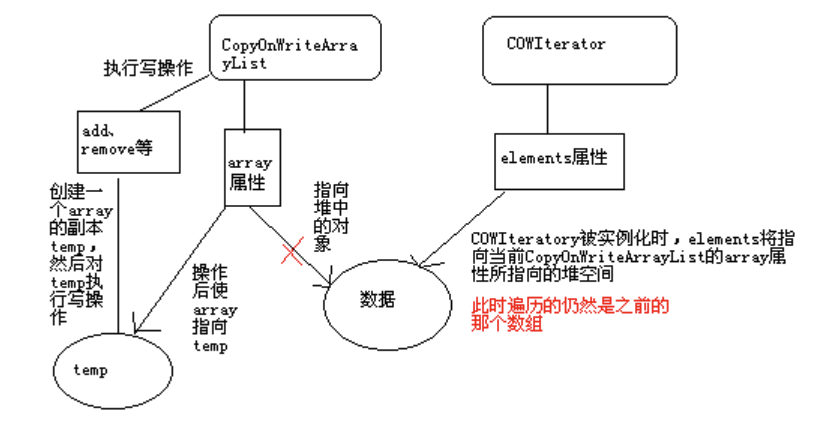
若当一个线程正在迭代集合中的数据时,另一个线程同时对List执行了“写”操作,这个“写”操作执行完毕后,最终更新的是的仅仅是array指向,而迭代线程所迭代的elements仍然指向最初的那个数组。同时CopyOnWriteArrayList类的“写”方法都是线程同步的。
因此CopyOnWriteArrayList顾名思义,当向ArrayList执行“写”操作时会先建立一个副本。
Set接口
若希望集合中不存在相同的元素则可以使用Set接口,Set接口最常见的两个子类:
- HashSet<E> :在没有相同元素的基础上,还可以高速存取。
- TreeSet<E> :在没有相同元素的基础上,还可以自动排序。
范例1:HashSet。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// 下面插入了2个"No.1"但是执行的结果却发现只有1个,这就是Set的特点,不允许有重复元素。
import java.util.HashSet;
public class HashSetDemo {
public static void main(String[] args){
HashSet<String> hash = new HashSet<String>();
hash.add("No.1");
hash.add("No.1");
hash.add("No.2");
hash.add("No.3");
hash.add("No.4");
hash.add("No.5");
System.out.println(hash);
}
}
// 使用HashSet的add()方法插入元素的时候:
// HashSe会自动调用元素的hashCode()方法。
// 然后根据hashCode()方法的返回值,来决定元素要插入的位置。
// 如果该位置上已经存在元素了,则会调用该元素equals()方法进行比较。
// 如果两个元素相等,则丢掉欲插入的元素。
// 如果两个元素不相等,则新元素会被加入到另一个位置(通过冲突检测来决定哪一个位置)。
// 本范例中使用的是String类,在String类已经重写完了Object类的equals()和hashCode()方法。
// 如果是自定义的类,却并没有重写这2个方法,则就无法消除重复。
// 说白了,对于自定义的类来说:
// 如果想完整的使用HashSet类,那么最少要重写equals()和hashCode()方法。
// 重写hashCode()用于获得元素的存储位置,只要能尽量使对象间的hash码互不相同即可。
// 重写equals()用于在两个元素的位置相同的时候,比较两个元素是否相等。
// HashSet的一个特性:
// 将元素A、B依次插入到HashSet中,A并不一定排在B的前面,因为元素存储位置是由hash码来确定的。
// 因此说HashSet是无序存放元素的。
范例1:TreeSet。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import java.util.TreeSet;
public class TreeSetDemo{
public static void main(String[] args){
TreeSet<String> tree = new TreeSet<String>();
tree.add("No.45");
tree.add("No.1");
tree.add("No.1");
tree.add("No.52");
tree.add("No.12");
tree.add("No.4");
tree.add("No.11");
System.out.println(tree);
}
}
// 执行程序后发现,TreeSet不允许元素重复同时会自动给元素进行排序。
// 但是自动排序功能是有条件的:
// TreeSet<T>中的T必须是实现了Comparable<T>接口,否则程序运行时抛异常。
// String类已经实现了Comparable接口,因此没有抛异常。
// 说白了,如果想完整的使用TreeSet<E>类,那么最少要实现Comparable接口。
// 重写compareTo()可以同时完成两份工作:排序和消除重复。
集合输出
在Java中有四种集合输出的方法:Iterator、ListIterator、foreach、Enumeration。
范例1:Iterator遍历。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import java.util.*;
public class Demo{
public static void main(String[] args){
Collection<String> array = new ArrayList<String>();
array.add("No.45");
array.add("No.15");
array.add("No.23");
array.add("No.14");
array.add("No.65");
array.add("No.12");
// Iterator就是迭代器的意思,使用它可以从第一个元素开始,一直遍历到最后一个元素。
// Iterator中有一个位置指针的概念,用来代表当前正在遍历的位置,
// 最初的时候这个指针指在第一个元素之前的位置。
// Collection接口的子类都有一个iterator()方法用来获取当前集合的迭代器。
Iterator<String> iter = array.iterator();
// 判断是否还有下一个元素
while(iter.hasNext()){
// 移动指针到下一个元素,并返回该元素
String str = iter.next();
if("No.14".equals(str))
// 使用迭代器删除当前元素,这个操作不会有并发修改的问题。
// 每调用一次iter.next()方法只可以执行一次iter.remove()。
iter.remove();
else
System.out.println(str);
}
System.out.println(array);
}
}
范例2:ListIterator遍历。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// ListIterator接口是专为List接口及其子类准备的,可以进行向前遍历和向后遍历。
// 向前遍历和向后遍历使用同一个位置指针,因此最初的时候,指针指向的第一个元素之前,
// 这时是无法进行向前遍历的。
import java.util.*;
public class Demo{
public static void main(String[] args){
List<String> array = new ArrayList<String>();
array.add("No.45");
array.add("No.15");
array.add("No.23");
array.add("No.14");
array.add("No.65");
array.add("No.12");
ListIterator<String> iter = array.listIterator();
System.out.println("从头开始遍历:");
while(iter.hasNext()){
System.out.print(iter.next()+" -- ");
}
System.out.println("\n从尾开始遍历:");
while(iter.hasPrevious()){
System.out.print(iter.previous()+" -- ");
}
}
}
范例3:Foreach遍历。1
2
3
4
5
6
7
8
9
10
11
12import java.util.*;
public class Demo{
public static void main(String[] args){
List<String> array = new ArrayList<String>();
array.add("No.45");
array.add("No.15");
array.add("No.65");
for(String str : array) {
System.out.println("☆"+str+"☆");
}
}
}
范例4:Enumeration遍历。1
2
3
4
5
6
7
8
9
10
11
12
13
14// Enumeration类用于遍历Vector类 和Vector是同一时代的产物。
import java.util.*;
public class Demo{
public static void main(String[] args){
Vector<String> array = new Vector<String>();
array.add("No.45");
array.add("No.15");
array.add("No.65");
Enumeration e = array.elements();
while(e.hasMoreElements()){
System.out.println(e.nextElement());
}
}
}
Map接口
Map接口可以操作两个值,比如说:
Key(姓名) value(电话号码)
张三 123123
李四 456456
王五 789789
这样的数据就可以使用Map存储,使用的时候根据key值去map中查找与其对应的value值。
HashMap
范例1:添加元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import java.util.*;
public class MapDemo {
public static void main(String[] args){
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("张三", 123123);
map.put("李四", 456456);
map.put("王五", 789789);
map.put("张三", 100000);
System.out.println(map);
// 通过map.get("张三")可以读取到“100000”。
}
}
// 程序运行的结果:
// 插入4条数据,输出的却只有3条。
// 这是因为Map中key值不可以重复,如果重复了则新value会覆盖旧value。
// 由于此处是使用String类作为key,所以可以保证key值不重复。
// 但是如果使用用户自定义类做key,则同样需要同时重写hashCode()和equals()方法,少一个都不行。
范例2:Iterator遍历元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import java.util.*;
public class MapDemo {
public static void main(String[] args){
Map<Person,String> map = new HashMap<Person,String>();
map.put(new Person("张三", 20),"No.1");
map.put(new Person("李四", 21),"No.2");
map.put(new Person("王五", 64),"No.3");
// 获取一个包含所有key的Set对象。
Set<Person> p = map.keySet();
Iterator<Person> iter = p.iterator();
while(iter.hasNext()){
Person temp =iter.next();
System.out.println(temp+" ; value --> "+map.get(temp));
}
}
}
// 程序执行结果:
// [李四,21] ; value --> No.2
// [王五,64] ; value --> No.3
// [张三,20] ; value --> No.1
范例3:Foreach遍历元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 在Map中为每个Item可以保存两个值,但是实际上在Map接口内部却不是直接保存这两个值。
// 在Map接口中真正保存的是一个个Map.Entry对象。
// 在一个Map.Entry对象中,保存的才是map中定义的K和V。
// 因此在Map中不可以直接使用Iterator接口遍历。
import java.util.*;
public class MapDemo {
public static void main(String[] args){
Map<Person,String> map = new TreeMap<Person,String>();
map.put(new Person("张三", 20),"No.1");
map.put(new Person("李四", 21),"No.2");
map.put(new Person("李四", 21),"No.3");
map.put(new Person("王五", 64),"No.4");
for(Map.Entry<Person, String> temp : map.entrySet())
System.out.println(temp.getKey()+" "+temp.getValue());
}
}
范例4:其它常用方法。1
2
3
4
5
6
7
8// 将其内部所有value放到一起,以Collection形式返回。
Collection<String> p = map.values();
// 按key移除元素,同样要求key的类同时重写hashCode()和equals()方法。
map.remove(new Person("王五", 64));
// 是否存在某个Key
map.containsKey("No.1");
// 是否存在某个Value
map.containsValue(1);
还有一个名为Hashtable的类,它的用法与HashMap一样,不同的是其是线程安全的。
TreeMap
范例1:添加元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// TreeMap类同样不允许key重复,并且会自动排序。
import java.util.*;
public class MapDemo {
public static void main(String[] args){
Map<String,String> map = new TreeMap<String,String>();
map.put("No.3", "赵六");
map.put("No.1", "张三");
map.put("No.2", "王五");
map.put("No.4", "秦七");
map.put("No.1", "李四");
System.out.println(map);
}
}
// 程序运行的结果:
// {No.1=李四, No.2=王五, No.3=赵六, No.4=秦七}
范例2:自定义类作为key。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 如果想完整的使用TreeMap<K,V>类,那么最少要实现Comparable接口。
// 重写compareTo()可以同时完成两份工作:排序和消除重复key。
import java.util.*;
public class MapDemo {
public static void main(String[] args){
Map<Person,String> map = new TreeMap<Person,String>();
map.put(new Person("张三", 20),"No.1");
map.put(new Person("李四", 21),"No.2");
map.put(new Person("李四", 21),"No.3");
map.put(new Person("王五", 64),"No.4");
System.out.println(map);
}
}
// 在Map接口中,插入、删除等需要重写(compareTo、equals、hashCode)等方法,
// 都是针对于key来说的,value仅仅用来保存数据,value并不参与匹配。
// 在Set接口(TreeSet和HashSet)中,若出现了重复元素,则会将待插入元素删掉。
// 在Map接口(TreeMap和HashMap)中,若出现了重复key,则会用新value覆盖旧value。
IdentityHashMap
在Map中是不允许key值重复的,但是在此类中可以允许key值重复。
范例1:Identity。1
2
3
4
5
6
7
8
9
10
11
12import java.util.*;
public class MapDemo {
public static void main(String[] args){
Map<Person,String> map = new IdentityHashMap<Person,String>();
map.put(new Person("张三", 20),"No.1");
map.put(new Person("张三", 20),"No.2");
System.out.println(map);
}
}
// 只要在两个对象的key使用“==”进行比较时不相等,就可以允许这2个key同时存在。
// 我在Person类中重写了hashCode()方法,如果“==”比较的是对象的hashCode码的话,
// 那么上面的范例中就只会有一个元素,但事实上却出现2个元素。
Properties
Properties类通常操作软件的配置文件,配置文件用来保存用户对软件进行的一些个性化配置。如:软件使用的主题、皮肤等设置。
范例1:属性文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// Properties类是的Hashtable的子类。
// 配置文件是由一个个的属性组成的,每个属性都是采用key/value的形式来表示。
public class Demo {
public static void main(String[] args) throws Exception {
// 实例化一个Properties对象。
Properties p = new Properties();
// 创建属性。
p.setProperty("cxy", "tsx");
p.setProperty("ch.cxf", "china");
p.setProperty("en", "english");
p.setProperty("world", "世界");
// 将属性文件持久化到外存中。
File exportFile = new File("D:"+File.separator+"config.properties");
p.store(new FileOutputStream(exportFile), "Hello World");
}
}
// 属性文件是纯文本格式的,属性文件的名称和后缀名可以任意设定。
// 但是通常是“.properties”做为文件的后缀名。
// 使用setProperty()方法创建属性,然后将属性保存到Properties对象中。
// 使用store()方法将当前Properties对象中的数据写到外存中保存,此方法的第二个参数是当前属性文件的注释文字。
// 输出的文件内容:
// #Hello World
// #Thu Sep 06 22:19:10 CST 2012
// en=english
// world=\u4E16\u754C
// cxy=tsx
// ch.cxf=china
范例2:XML格式文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class Demo {
public static void main(String[] args) throws Exception {
// 实例化一个Properties对象。
Properties p = new Properties();
// 创建属性。
p.setProperty("cxy", "tsx");
p.setProperty("ch.cxf", "china");
p.setProperty("en", "english");
p.setProperty("world", "世界");
// 将属性文件持久化到外存中。
File exportFile = new File("D:"+File.separator+"config.xml");
p.storeToXML(new FileOutputStream(exportFile), "Hello World","UTF-8");
}
}
// 输出的文件内容:
// <?xml version="1.0" encoding="UTF-8" standalone="no"?>
// <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
// <properties>
// <comment>Hello World</comment>
// <entry key="en">english</entry>
// <entry key="world">世界</entry>
// <entry key="cxy">tsx</entry>
// <entry key="ch.cxf">china</entry>
// </properties>
范例3:载入文件。1
2
3
4
5
6
7
8
9
10
11
12
13public class Demo {
public static void main(String[] args) throws Exception {
// 实例化一个Properties对象。
Properties p = new Properties();
// 将一个xml风格的配置文件导入进内存。
File importFile = new File("D:"+File.separator+"config.xml");
// 使用loadFromXML()方法导入XML风格的配置文件,将数据保存到当前Properties对象中。
// 还有一个load()方法导入普通风格的配置文件。
p.loadFromXML(new FileInputStream(importFile));
// 若world属性不存在,则返回null。
System.out.println(p.get("world"));
}
}
Collections
Collections类和Arrays类的性质是一样的,都是工具类。
- Arrays类提供了一些对数组进行操作的方法。
- Collections类提供了一些对集合进行操作的方法,其内全部都是静态方法。
范例1:排序。1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.*;
public class CollectionsDemo {
public static void main(String[] args){
ArrayList<String> array = new ArrayList<String>();
array.add("No.7");
array.add("No.6");
array.add("No.5");
array.add("No.4");
array.add("No.3");
Collections.sort(array);
System.out.println(array);
}
}
范例2:填充元素。1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.*;
public class CollectionsDemo {
public static void main(String[] args){
ArrayList<String> array = new ArrayList<String>();
array.add("No.7");
array.add("No.6");
array.add("No.5");
array.add("No.4");
array.add("No.3");
Collections.fill(array,"Hello World");
System.out.println(array);
}
}
范例3:增加元素。1
2
3
4
5
6
7
8
9
10
11import java.util.*;
public class CollectionsDemo {
public static void main(String[] args){
ArrayList<String> array = new ArrayList<String>();
array.add("No.7");
array.add("No.6");
array.add("No.5");
Collections.addAll(array,"Hello World","Tomcat","JimDog");
System.out.println(array);
}
}
范例4:折半查找。1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.*;
public class CollectionsDemo {
public static void main(String[] args){
ArrayList<String> array = new ArrayList<String>();
array.add("No.7");
array.add("No.6");
array.add("No.5");
array.add("Tomcat");
array.add("JimDog");
System.out.println("Tomcat的下标为:"
+ Collections.binarySearch(array, "Tomcat"));
}
}
范例5:逆序排序。1
2
3
4
5
6
7
8
9
10
11
12import java.util.*;
public class CollectionDemo {
public static void main(String[] args) {
ArrayList<Integer> array = new ArrayList<Integer>();
array.add(3); array.add(1);
array.add(9); array.add(33);
Collections.sort(array); // 升序排序。
System.out.println("升序排序:"+array);
Collections.reverse(array); // 反转集合,即首尾元素依次交换位置。
System.out.println("降序排序:"+array);
}
}
进阶特性
反射
Class
在Java世界中,万物皆对象,比如“人类”可以使用Person类来表示,Person类中有age、name、sex等属性。如果继续深入一下的话,也许您会提出另一个问题,“你不是说万物皆对象吗?那好,我问你,人类可以用Person来表示,那Person类生成的字节码,用什么表示?别给我说木有”,这个…确实有东西可以表示,它就是咱们所说的“Class”类。
简单的说,Class类的对象就是代表经过编译后生成字节码文件,仔细观察一下API就知道,Class描述的是类的结构,比如:构造方法、成员方法、成员变量等等。
也就是说,接下来通过反射机制所要研究的,是“类的结构”,而不是“类的内容”。
提示:反射是十分重要的,它在Java的很多技术中被广泛的使用,如EL表达式、标签编程、JavaBean等,所以研究并深刻理解反射机制是十分必要的。
范例1:获取Class对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class ClassDemo1 {
public static void main(String[] args) throws Exception {
// 第一种方式,通过forName方法获取Class对象。
// 加载指定的类到内存中(若已再内存则不会重复加载),然后实例化对应的Class类。
Class<?> cls = Class.forName("cxy.zy.reflect.Person");
// getName方法返回该Class对象所表示的类的类名。
System.out.println(cls.getName());
// 第二种方式,直接通过“类名.class”来获取Class对象。
cls = Person.class;
System.out.println(cls.getName());
// 第三种方式,通过“对象.getClass()”实例化Class类。
Person p = new Person("张三",50);
Class<?> cls = p.getClass();
System.out.println(cls.getName());
}
}
范例2:字节码比较。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class Demo {
public static void main(String[] args) throws Exception{
Class<?> cls1 = "abc".getClass();
Class<String> cls2 = String.class;
Class cls3 = Class.forName("java.lang.String");
// 每个类的字节码,在内存中只会存在一份。
// 执行结果:true、true、true
System.out.println(cls1 == cls2);
System.out.println(cls1 == cls3);
System.out.println(cls2 == cls3);
// Java中内置了9种Class对象:8中基本数据类型与void类型。
// isPrimitive判定指定的Class对象是否表示内置的9种Class字节码。
System.out.println(int.class.isPrimitive()); // true
System.out.println(int[].class.isPrimitive()); // false
System.out.println(int[].class.isArray()); // true
System.out.println(Integer.class.isPrimitive()); // false
System.out.println(void.class.isPrimitive()); // true
// 判断int和Integer是否具有相同的字节码。
System.out.println(int.class == Integer.class); // false
System.out.println(int.class == Integer.TYPE); // true
}
}
范例3:实例化Person类对象。1
2
3
4
5
6
7
8
9public class ClassDemo {
public static void main(String[] args) throws Exception {
Class<?> cls = Class.forName("cxy.zy.reflect.Person");
// 调用Person类的无参构造方法,实例化对象。
// 若Person类中没有无参的构造方法,则运行的时候会抛异常。
Person p = (Person)cls.newInstance();
System.out.println(p);
}
}
范例4:获取父类和接口。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class ClassDemo {
public static void main(String[] args) throws Exception {
Class<?> cls = Class.forName("java.lang.String");
// 获取String的父类
Class<?> sup = cls.getSuperclass();
// 输出:java.lang.Object
System.out.println(sup.getName());
// 获取String所实现的接口
Class<?> inter[] = cls.getInterfaces();
for(Class<?> temp : inter){
System.out.println(temp.getName());
}
// 输出:
// java.io.Serializable
// java.lang.Comparable
// java.lang.CharSequence
}
}
Constructor
引言:每个类都有一个或多个构造方法,每个构造方法,都可以使用Constructor类来表示。
范例1:获取所有构造方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import java.lang.reflect.Constructor;
public class ClassDemo {
public static void main(String[] args) throws Exception {
Class<?> cls = String.class;
// 获取该类的所有构造方法。
Constructor<?>[] con = cls.getConstructors();
for(Constructor c:con){
System.out.print(c.getName()+"(");
// 获得该构造方法的,所有参数的类型。
for(Class temp : c.getParameterTypes()){
System.out.print(temp.getName()+",");
}
System.out.println(")");
}
}
}
范例2:调用指定的构造方法。1
2
3
4
5
6
7
8
9
10
11
12
13import java.lang.reflect.Constructor;
public class ConstructorDemo {
public static void main(String[] args) throws Exception {
Class<String> cls = String.class;
// 获得String类中,具有一个String参数的构造方法。
// 若要调用无参的构造方法,则不需传递参数或传递null。
Constructor<String> con = cls.getConstructor(String.class);
// 调用这个构造方法,并给这个构造方法传递一个String参数。
String str = con.newInstance("黑马");
// 输出结果。
System.out.println(str);
}
}
范例3:拆分构造方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import java.lang.reflect.*;
public class ClassDemo {
public static void main(String[] args) throws Exception {
Class<?> cls = Class.forName("java.lang.String");
Constructor<?> con[] = cls.getConstructors();
for(Constructor<?> temp : con){
// 获得方法的修饰符
String mod = Modifier.toString(temp.getModifiers());
String name = temp.getName(); //获得方法名称
Class<?> param[] = temp.getParameterTypes(); //获得参数列表
System.out.print(mod+" "+name+"(");
for(int i=0;i<param.length;i++){
System.out.print(param[i].getName()+" p"+i);
if(i<param.length-1){
System.out.print(",");
}
}
System.out.println(")");
}
}
}
Field
引言:每个类一般都有若干个属性,每个属性都可以使用Field类来表示。
范例1:获取所有属性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Demo {
public static void main(String[] args) throws Exception {
// 使用getFields()或getField()方法,仅能访问到,该类的public属性。
Field[] arr = Point.class.getFields();
for(Field f:arr){
System.out.println(f.getName());
}
// 返回包括公共、保护、默认(包)访问和私有字段,但不包括继承的字段。
// 此方法只可以访问private的属性,不可以修改其值。
arr = Point.class.getDeclaredFields();
for(Field f:arr){
System.out.println(f.getName());
}
}
}
范例2:访问与修改属性。1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Test {
public static void main(String[] args) throws Exception {
Person p = new Person();
Field field = Person.class.getDeclaredField("name");
// 使用setAccessible方法,就可以修改private类型的属性。
field.setAccessible(true);
field.set(p, "张三");
System.out.println(field.get(p));
}
}
class Person {
private String name;
private int age;
}
范例3:替换字符串。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public class Test {
public static void main(String[] args) throws Exception {
Point p = new Point();
// 列出所有的属性。
Field[] array = Point.class.getDeclaredFields();
// 遍历每个属性。
for(Field temp : array){
// 扩大当前属性的访问权限。
temp.setAccessible(true);
// 若属性是String类型的。
if(temp.getType() == String.class){
// 进行替换操作
temp.set(p,((String)temp.get(p)).replace('a','C'));
}
// 不论是否替换,都将结果输出。
System.out.println(temp.get(p));
}
}
}
class Point {
private String a = "aaaaaabbbbbabab";
private String b = "a";
private String c = "bb";
}
Method
引言:每个类一般都有若干个方法,每个方法都可以使用Method类来表示。
范例1:获取指定的函数。1
2
3
4
5
6
7
8
9
10
11
12
13public static void main(String[] args) throws Exception {
// getMethods()方法可以获得当前类中的所有的方法。
// getMethod()方法可以获得某个具体的方法。
// 找到String类中的matches方法,由于可能存在方法重载,因此需要指出该方法参数列表。
Method m = String.class.getMethod("matches", String.class);
// 使用invoke方法,执行方法的调用,第一个参数是表示在哪个对象身上调用此方法。
// 调用对象“12345”的matches方法,进行正则表达式验证,\\d+是传递给方法的参数。
System.out.println(m.invoke("12345","\\d+"));
// 静态方法不依附与某个对象,所以第一个参数可以传递null。
Method m = Math.class.getMethod("pow",double.class,double.class);
System.out.println(m.invoke(null,2,2));
}
范例2:泛型不是万能的。1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.*;
import java.lang.reflect.*;
public class Demo {
public static void main(String[] args)throws Exception{
ArrayList<Integer> list = new ArrayList<Integer>();
Method m = ArrayList.class.getMethod("add",Object.class);
m.invoke(list,"cxy");
System.out.println(list);
}
}
// 首先,“泛型是专门给编译器看的,编译结束后,ArrayList<Integer>中的<Integer>会被删除”。
// 然后,利用反射,就可以将String对象,插入到ArrayList<Integer>中。
// 最后,调用add方法时,参数的类型为“Object.class”。
范例3:拆分方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import java.lang.reflect.*;
public class ClassDemo {
public static void main(String[] args) throws Exception {
Class<?> cls = Class.forName("java.lang.String");
Method[] method = cls.getMethods();
for(Method m : method){
// 方法的修饰符
String mod = Modifier.toString(m.getModifiers());
String name = m.getName(); // 方法的名称
Class<?> reType = m.getReturnType(); // 方法返回值类型
Class<?> excep[] = m.getExceptionTypes();//方法可能抛出的异常
Class<?> param[] = m.getParameterTypes(); //方法的参数列表
System.out.print(mod+" "+reType.getName()+" "+name+"(");
for(int i=0;i<param.length;i++){
System.out.print(param[i].getName()+" args-"+i);
if(i<param.length-1){
System.out.print(",");
}
}
System.out.print(")");
if(excep.length>0){ //如果抛出了异常
System.out.print(" throws ");
for(int j=0;j<excep.length;j++){
System.out.print(excep[j].getName());
if(j<excep.length-1){
System.out.print(",");
}
}
}
System.out.println();
}
}
}
范例4:反射私有方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18package org.cxy.reflect;
import java.lang.reflect.Method;
public class Person {
private void print(){
System.out.println("0-------0");
}
}
class Demo{
public static void main(String[] args) throws Exception{
Class<Person> cls =
(Class<Person>) Class.forName("org.cxy.reflect.Person");
Person p = cls.newInstance();
Method m = cls.getDeclaredMethod("print", null);
m.setAccessible(true);
m.invoke(p, null);
}
}
范例5:反射带有数组参数的方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class MethodDemo {
public static void main(String[] args) throws Exception {
Class<MethodDemo> cls = MethodDemo.class;
// 获得方法对象。
Method m = cls.getMethod("aaa", String[].class);
// 错误!
// m.invoke(null, new String[]{"123","456"});
// 正确!
m.invoke(null, (Object)new String[]{"123","456"});
}
public static void aaa(String[] array){
System.out.println(Arrays.asList(array));
}
}
// invoke的方法原型为:
// public Object invoke(Object obj, Object... args)
// 第二个参数是可变参数,若直接传递new String[]{"123","456"}给invoke方法,则会去调用aaa(String a1,String a2),结果自然是找不到。
// 因此需要将String[]转换成Object,以此来告诉JVM 调用具有一个String[]类型参数的aaa方法。
枚举
枚举可以限制一个内容的取值范围。如:
- 限制性别的取值只能是:男、女。
- 限制一周只能有7天。
- 限制三基色只能为:红、绿、蓝。
范例1:定义枚举类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 使用enum关键字来定义一个枚举类Color,该类的引用变量取值只能为RED、GREEN、BLUE三者之一。
// 其中RED、GREEN、BLUE被称为枚举常量,每个枚举常量都是一个“static”的。
// 使用enum关键字定义的枚举类,同样会产生一个.class文件。
enum Color {
RED, GREEN, BLUE;
}
public class Test {
public static void main(String[] args) {
Color c = Color.RED;
System.out.println(c);
// values()方法可以获取所有枚举常量
for (Color item : Color.values()) {
// 枚举常量的名称和下标
System.out.println(item.name() + " --> " + item.ordinal());
}
// 程序输出:
// RED
// RED --> 0
// GREEN --> 1
// BLUE --> 2
}
}
范例2:枚举常量与switch。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Test {
public static void main(String[] args) {
Color c1 = Color.BLUE;
switch (c1) {
// 在case后面的枚举常量,不能写成“Color.RED”,只能写成“RED”。
case RED: {
System.out.println("红色");
break;
}
case GREEN: {
System.out.println("绿色");
break;
}
case BLUE: {
System.out.println("蓝色");
break;
}
}
}
}
范例3:构造方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 在枚举类中可以定义构造方法,每个枚举常量都会默认调用无参的构造方法,
// 如果没有无参的构造方法,则需要为每一个枚举常量指明要调用哪一个构造方法。
public enum Color{
RED("红色"),GREEN("绿色"),BLUE; //若枚举常量后还有其他,则这个分号必须加上。
private String name; // 属性的定义位置必须要在枚举常量之后。
Color(){} //构造方法不可以是public的,因为构造器只需要被枚举常量调用。
private Color(String name){
this.name = name;
}
public String toString(){
// name()方法是Enum类自有的,用于返回枚举常量的字面名称。
// name字段是咱们自定义的。
return this.name == null? this.name():this.name;
}
}
范例4:抽象方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// 在枚举中可以定义抽象方法,但是每一个枚举对象都必须分别重写此抽象方法。
enum Color {
RED("红") {
public String getInfo() {
// 可以在方法中引用字段,但字段不能用private修饰。
return "我的名字是:" + title;
}
},
GREEN("绿") {
public String getInfo() {
return "我的名字是:" + title;
}
},
BLUE("蓝") {
public String getInfo() {
return "我的名字是:" + title;
}
};
String title;
private Color(String title) {
this.title = title;
}
public abstract String getInfo();
}
public class Test {
public static void main(String[] args) {
System.out.println(Color.RED.getInfo());
}
}
// 枚举类也可以实现某个接口,实现的方式和普通类一样。
// 既可以在枚举类中直接重写接口中的抽象方法,也可以像本范例这样让每个枚举常量分别重写。
范例5:集合的支持。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 在枚举中可以定义抽象方法,但是每一个枚举对象都必须分别重写此抽象方法。
enum Color {
RED, GREEN, BLUE;
}
public class Test {
public static void main(String[] args) {
// 枚举Set集合
EnumSet<Color> set = EnumSet.allOf(Color.class);
Iterator<Color> iter = set.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
// 枚举Map集合
EnumMap<Color, String> em = new EnumMap<Color, String>(Color.class);
em.put(Color.BLUE, "蓝色1");
em.put(Color.BLUE, "蓝色2");
em.put(Color.GREEN, "绿色");
em.put(Color.RED, "红色");
for (Map.Entry<Color, String> map : em.entrySet()) {
System.out.println(map.getKey() + " " + map.getValue());
}
}
}
// 提示:也可以通过枚举类来实现单例设计模式。
引用
Java中每个对象都存在引用,外界可以通过对象的引用来操作存在于堆中的对象。
为了更好的管理JVM内存,防止出现内存泄漏甚至是程序抛出OOM的错误,从JDK1.2版本开始,把对象的引用分为四种级别,从而使程序能更加灵活的控制对象的生命周期,这四种级别由高到低依次为:强引用、软引用、弱引用和虚引用。
内存泄漏:通俗的说,堆中存在很多已经无用的空间(对象),这些空间(对象)在被使用过后,其引用并没有释放,而是还被外界的某个变量所持有,这导致垃圾回收器无法回收该对象,这种系统中明明存在可用的内存空间,却偏偏不能使用的情况称为内存泄漏。
内存溢出(OOM, Out of Memory):当JVM中的内存不够使用的时候,会抛出java.lang.OutOfMemoryError错误。若内存泄漏严重或者加载过大的数据(如从磁盘加载图片到程序中),最终就会导致OOM的发生。
范例1:之前一直都是强引用。1
2
3
4
5
6
7
8
9
10
11
12public class Demo {
static StringBuilder sub;
public static void main(String[] args) throws Exception {
// 变量sub与StringBuilder对象关系就是强引用关系。
// GC试图回收某个对象时,会检查外界是否有变量持有该对象的强引用,若无才会回收。
// 当内存空间不足,JVM宁愿抛出OutOfMemoryError错误使程序异常终止,
// 也不会靠随意回收具有强引用的对象来解决内存不足问题。
// 因此若sub不被置null则StringBuilder对象将永远不会被GC当作垃圾给回收掉。
sub = new StringBuilder("str");
System.out.println(sub);
}
}
在Java中软引用、弱引用、虚引用每种引用对象类型都是通过抽象的基本 Reference 类的一个子类实现的,三种引用的区别仅仅是在何种场合下去回收指示对象。
- 强引用:是Java程序中最普遍的,只要强引用还存在,GC宁愿抛OOM也不会回收掉被引用的对象。
- 软引用:若对象存在强引用,则对象不会被GC回收,同时它的软引用也不会返回空,否则GC会在系统内存不够用时回收该对象,当该对象被回收后,它的软引用将返回空。需要注意的是,软引用返回空有两个条件:系统内存不足和对象没有强引用;只满足某一条是不行的,比如若对象只是没有强引用时你主动调用gc后,你立刻访问软引用所引用的对象,是可以获取到该对象的。
- 弱引用:它的强度比软引用更弱些,被弱引用关联的对象只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。若对象存在强引用则不会回收弱引用。
- 虚引用:最弱的一种引用关系,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的是希望能在这个对象被收集器回收时收到一个系统通知。
范例2:测试软引用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class Test {
// 执行本代码之前,请将虚拟机堆内存的最大容量设置为20M,使用下面的参数即可:
// -Xmx20M
public static void main(String[] args) throws Exception {
// 申请一个占据10M内存的字节数组,并赋值给一个强引用
byte[] data = new byte[1024 * 1024 * 10];
// 再使用一个软引用包裹住字节数组
SoftReference<byte[]> soft = new SoftReference<byte[]>(data);
// 由于此时的字节数组身上有两个引用:一个强引用、一个软引用,且虚拟机当前内存足够。
// 所以下面代码可以获取到字节数组的引用。
System.out.println(soft.get());
// 此代码用来断开强引用。
data = null;
// 调用垃圾回收
System.gc();
// 再次申请10M内存,由于上面强引用被断开了,所以那片空间就可以被回收了。
byte[] bytes = new byte[1024 * 1024 * 10];
// 下面会输出null
System.out.println(soft.get());
// 如果把第13行代码删掉,不去断开强引用,那么虚拟机宁愿抛出OOM,也不会回收软引用。
}
}
// 相应的还有:
// 弱引用:WeakReference
// 虚引用:PhantomReference